 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClaimDiff-RL: Fine-Grained Caption Reinforcement Learning through Visual Claim Comparison
May 19, 2026Long-form image captioning exposes a reward granularity problem in RL: captions are judged as whole sequences, while the important errors occur at the level of individual visual claims. A good dense caption should be both faithful and informative, avoiding hallucination without omitting salient details. Yet pairwise preferences, reference-based metrics, and holistic scalar rewards compress these local errors into a single sequence-level signal, obscuring the tradeoff between factuality and coverage. We introduce ClaimDiff-RL, a framework that uses reference-conditioned atomic claim differences as the reward unit for caption RL. Given an image, an actor caption, and a reference caption, a multimodal judge enumerates visually grounded differences, verifies each difference against the image, assigns open-vocabulary error types and severity levels, and produces per-difference statistics for reward composition. This makes hallucinated claims and omitted salient facts separately measurable and tunable. Experiments show that holistic scalar rewards can reduce hallucination by increasing missing facts, while ClaimDiff-RL exposes this faithfulness and coverage tradeoff and enables more balanced operating points. On a 160-image human-labeled diagnostic benchmark, public captioning benchmarks, and VQA benchmarks, ClaimDiff-RL improves the hallucination--missing-fact balance, preserves general capability, and even surpasses Gemini-3-Pro-Preview on several fine-grained Capability dimensions such as object counting, spatial relations, and scene recognition. These results suggest that typed, verifiable claim differences are an effective reward unit for fine-grained and diagnosable caption RL.
Speed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model
Mar 23, 2026We present daVinci-MagiHuman, an open-source audio-video generative foundation model for human-centric generation. daVinci-MagiHuman jointly generates synchronized video and audio using a single-stream Transformer that processes text, video, and audio within a unified token sequence via self-attention only. This single-stream design avoids the complexity of multi-stream or cross-attention architectures while remaining easy to optimize with standard training and inference infrastructure. The model is particularly strong in human-centric scenarios, producing expressive facial performance, natural speech-expression coordination, realistic body motion, and precise audio-video synchronization. It supports multilingual spoken generation across Chinese (Mandarin and Cantonese), English, Japanese, Korean, German, and French. For efficient inference, we combine the single-stream backbone with model distillation, latent-space super-resolution, and a Turbo VAE decoder, enabling generation of a 5-second 256p video in 2 seconds on a single H100 GPU. In automatic evaluation, daVinci-MagiHuman achieves the highest visual quality and text alignment among leading open models, along with the lowest word error rate (14.60%) for speech intelligibility. In pairwise human evaluation, it achieves win rates of 80.0% against Ovi 1.1 and 60.9% against LTX 2.3 over 2000 comparisons. We open-source the complete model stack, including the base model, the distilled model, the super-resolution model, and the inference codebase.
What Does Vision Tool-Use Reinforcement Learning Really Learn? Disentangling Tool-Induced and Intrinsic Effects for Crop-and-Zoom
Feb 01, 2026Vision tool-use reinforcement learning (RL) can equip vision-language models with visual operators such as crop-and-zoom and achieves strong performance gains, yet it remains unclear whether these gains are driven by improvements in tool use or evolving intrinsic capabilities.We introduce MED (Measure-Explain-Diagnose), a coarse-to-fine framework that disentangles intrinsic capability changes from tool-induced effects, decomposes the tool-induced performance difference into gain and harm terms, and probes the mechanisms driving their evolution. Across checkpoint-level analyses on two VLMs with different tool priors and six benchmarks, we find that improvements are dominated by intrinsic learning, while tool-use RL mainly reduces tool-induced harm (e.g., fewer call-induced errors and weaker tool schema interference) and yields limited progress in tool-based correction of intrinsic failures. Overall, current vision tool-use RL learns to coexist safely with tools rather than master them.
Adaptively trained Physics-informed Radial Basis Function Neural Networks for Solving Multi-asset Option Pricing Problems
Jan 19, 2026The present study investigates the numerical solution of Black-Scholes partial differential equation (PDE) for option valuation with multiple underlying assets. We develop a physics-informed (PI) machine learning algorithm based on a radial basis function neural network (RBFNN) that concurrently optimizes the network architecture and predicts the target option price. The physics-informed radial basis function neural network (PIRBFNN) combines the strengths of the traditional radial basis function collocation method and the physics-informed neural network machine learning approach to effectively solve PDE problems in the financial context. By employing a PDE residual-based technique to adaptively refine the distribution of hidden neurons during the training process, the PIRBFNN facilitates accurate and efficient handling of multidimensional option pricing models featuring non-smooth payoff conditions. The validity of the proposed method is demonstrated through a set of experiments encompassing a single-asset European put option, a double-asset exchange option, and a four-asset basket call option.
Visual Programmability: A Guide for Code-as-Thought in Chart Understanding
Sep 11, 2025Chart understanding presents a critical test to the reasoning capabilities of Vision-Language Models (VLMs). Prior approaches face critical limitations: some rely on external tools, making them brittle and constrained by a predefined toolkit, while others fine-tune specialist models that often adopt a single reasoning strategy, such as text-based chain-of-thought (CoT). The intermediate steps of text-based reasoning are difficult to verify, which complicates the use of reinforcement-learning signals that reward factual accuracy. To address this, we propose a Code-as-Thought (CaT) approach to represent the visual information of a chart in a verifiable, symbolic format. Our key insight is that this strategy must be adaptive: a fixed, code-only implementation consistently fails on complex charts where symbolic representation is unsuitable. This finding leads us to introduce Visual Programmability: a learnable property that determines if a chart-question pair is better solved with code or direct visual analysis. We implement this concept in an adaptive framework where a VLM learns to choose between the CaT pathway and a direct visual reasoning pathway. The selection policy of the model is trained with reinforcement learning using a novel dual-reward system. This system combines a data-accuracy reward to ground the model in facts and prevent numerical hallucination, with a decision reward that teaches the model when to use each strategy, preventing it from defaulting to a single reasoning mode. Experiments demonstrate strong and robust performance across diverse chart-understanding benchmarks. Our work shows that VLMs can be taught not only to reason but also how to reason, dynamically selecting the optimal reasoning pathway for each task.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
Thinking with Generated Images
May 28, 2025We present Thinking with Generated Images, a novel paradigm that fundamentally transforms how large multimodal models (LMMs) engage with visual reasoning by enabling them to natively think across text and vision modalities through spontaneous generation of intermediate visual thinking steps. Current visual reasoning with LMMs is constrained to either processing fixed user-provided images or reasoning solely through text-based chain-of-thought (CoT). Thinking with Generated Images unlocks a new dimension of cognitive capability where models can actively construct intermediate visual thoughts, critique their own visual hypotheses, and refine them as integral components of their reasoning process. We demonstrate the effectiveness of our approach through two complementary mechanisms: (1) vision generation with intermediate visual subgoals, where models decompose complex visual tasks into manageable components that are generated and integrated progressively, and (2) vision generation with self-critique, where models generate an initial visual hypothesis, analyze its shortcomings through textual reasoning, and produce refined outputs based on their own critiques. Our experiments on vision generation benchmarks show substantial improvements over baseline approaches, with our models achieving up to 50% (from 38% to 57%) relative improvement in handling complex multi-object scenarios. From biochemists exploring novel protein structures, and architects iterating on spatial designs, to forensic analysts reconstructing crime scenes, and basketball players envisioning strategic plays, our approach enables AI models to engage in the kind of visual imagination and iterative refinement that characterizes human creative, analytical, and strategic thinking. We release our open-source suite at https://github.com/GAIR-NLP/thinking-with-generated-images.
One RL to See Them All: Visual Triple Unified Reinforcement Learning
May 23, 2025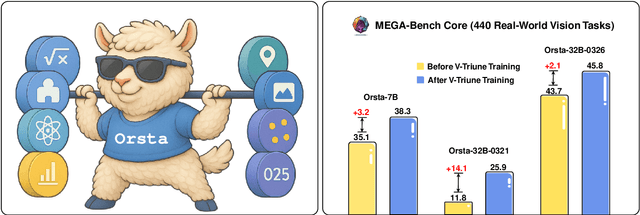
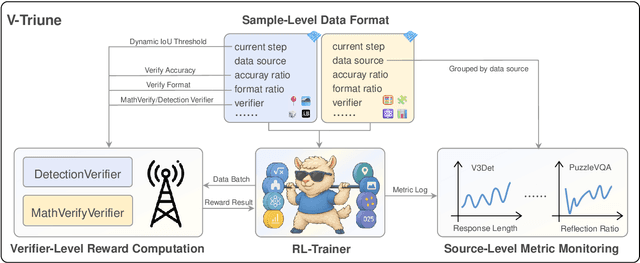
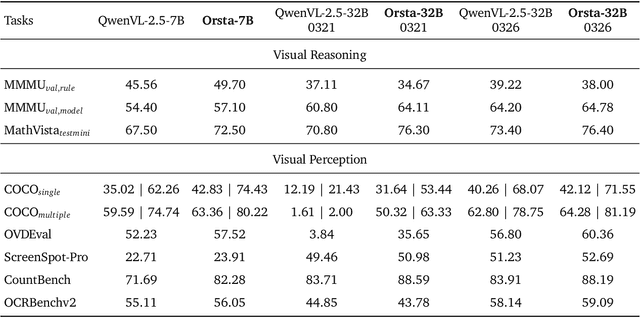
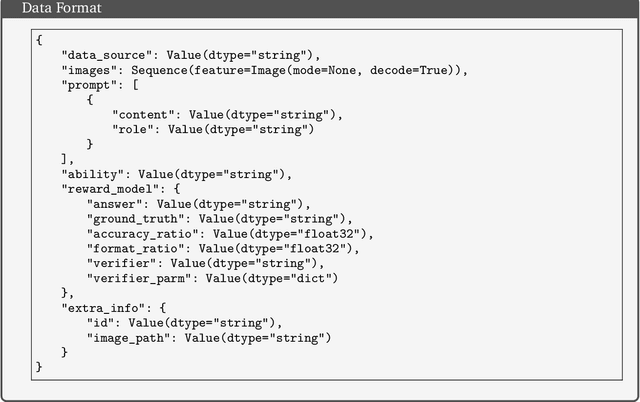
Reinforcement learning (RL) has significantly advanced the reasoning capabilities of vision-language models (VLMs). However, the use of RL beyond reasoning tasks remains largely unexplored, especially for perceptionintensive tasks like object detection and grounding. We propose V-Triune, a Visual Triple Unified Reinforcement Learning system that enables VLMs to jointly learn visual reasoning and perception tasks within a single training pipeline. V-Triune comprises triple complementary components: Sample-Level Data Formatting (to unify diverse task inputs), Verifier-Level Reward Computation (to deliver custom rewards via specialized verifiers) , and Source-Level Metric Monitoring (to diagnose problems at the data-source level). We further introduce a novel Dynamic IoU reward, which provides adaptive, progressive, and definite feedback for perception tasks handled by V-Triune. Our approach is instantiated within off-the-shelf RL training framework using open-source 7B and 32B backbone models. The resulting model, dubbed Orsta (One RL to See Them All), demonstrates consistent improvements across both reasoning and perception tasks. This broad capability is significantly shaped by its training on a diverse dataset, constructed around four representative visual reasoning tasks (Math, Puzzle, Chart, and Science) and four visual perception tasks (Grounding, Detection, Counting, and OCR). Subsequently, Orsta achieves substantial gains on MEGA-Bench Core, with improvements ranging from +2.1 to an impressive +14.1 across its various 7B and 32B model variants, with performance benefits extending to a wide range of downstream tasks. These results highlight the effectiveness and scalability of our unified RL approach for VLMs. The V-Triune system, along with the Orsta models, is publicly available at https://github.com/MiniMax-AI.
Generative AI Act II: Test Time Scaling Drives Cognition Engineering
Apr 21, 2025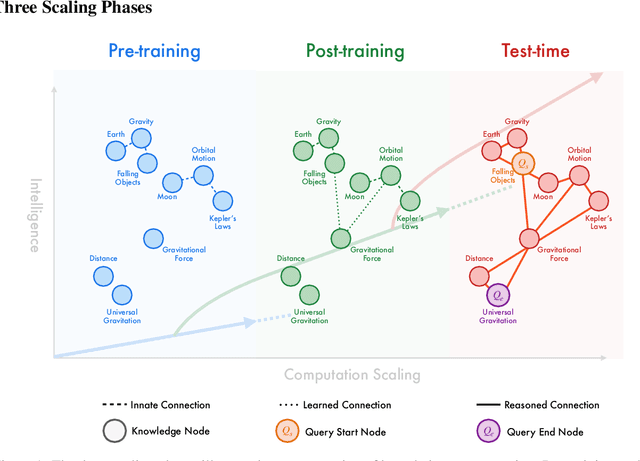
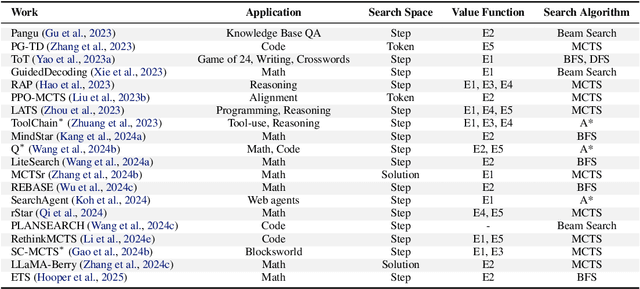
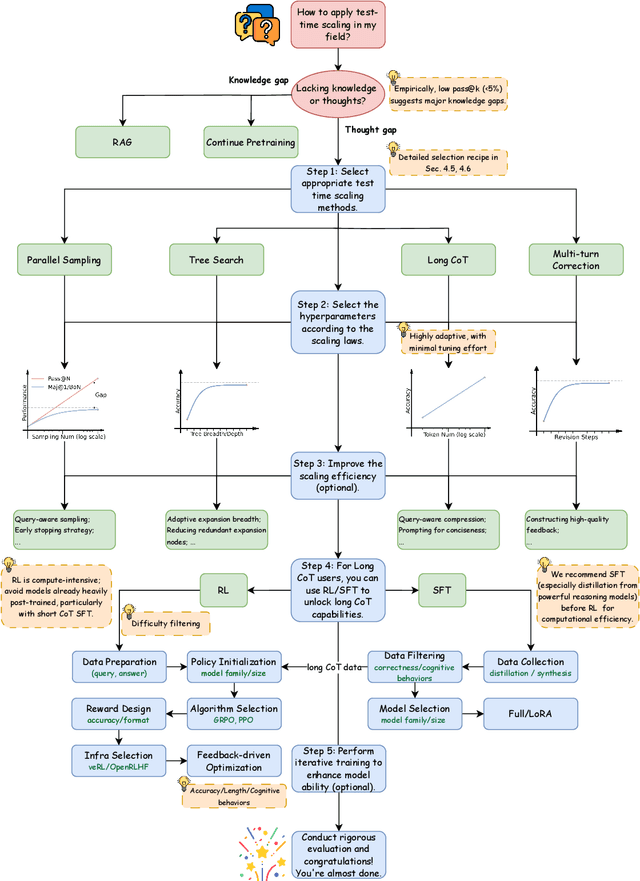
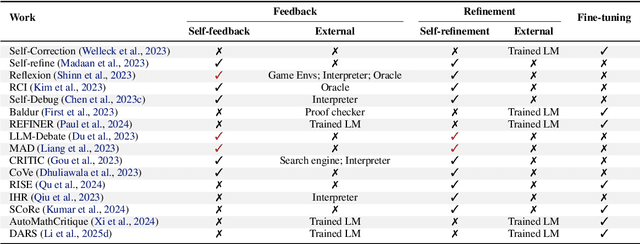
The first generation of Large Language Models - what might be called "Act I" of generative AI (2020-2023) - achieved remarkable success through massive parameter and data scaling, yet exhibited fundamental limitations such as knowledge latency, shallow reasoning, and constrained cognitive processes. During this era, prompt engineering emerged as our primary interface with AI, enabling dialogue-level communication through natural language. We now witness the emergence of "Act II" (2024-present), where models are transitioning from knowledge-retrieval systems (in latent space) to thought-construction engines through test-time scaling techniques. This new paradigm establishes a mind-level connection with AI through language-based thoughts. In this paper, we clarify the conceptual foundations of cognition engineering and explain why this moment is critical for its development. We systematically break down these advanced approaches through comprehensive tutorials and optimized implementations, democratizing access to cognition engineering and enabling every practitioner to participate in AI's second act. We provide a regularly updated collection of papers on test-time scaling in the GitHub Repository: https://github.com/GAIR-NLP/cognition-engineering
Rethinking RL Scaling for Vision Language Models: A Transparent, From-Scratch Framework and Comprehensive Evaluation Scheme
Apr 03, 2025Reinforcement learning (RL) has recently shown strong potential in improving the reasoning capabilities of large language models and is now being actively extended to vision-language models (VLMs). However, existing RL applications in VLMs often rely on heavily engineered frameworks that hinder reproducibility and accessibility, while lacking standardized evaluation protocols, making it difficult to compare results or interpret training dynamics. This work introduces a transparent, from-scratch framework for RL in VLMs, offering a minimal yet functional four-step pipeline validated across multiple models and datasets. In addition, a standardized evaluation scheme is proposed to assess training dynamics and reflective behaviors. Extensive experiments on visual reasoning tasks uncover key empirical findings: response length is sensitive to random seeds, reflection correlates with output length, and RL consistently outperforms supervised fine-tuning (SFT) in generalization, even with high-quality data. These findings, together with the proposed framework, aim to establish a reproducible baseline and support broader engagement in RL-based VLM research.