 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClaimDiff-RL: Fine-Grained Caption Reinforcement Learning through Visual Claim Comparison
May 19, 2026Long-form image captioning exposes a reward granularity problem in RL: captions are judged as whole sequences, while the important errors occur at the level of individual visual claims. A good dense caption should be both faithful and informative, avoiding hallucination without omitting salient details. Yet pairwise preferences, reference-based metrics, and holistic scalar rewards compress these local errors into a single sequence-level signal, obscuring the tradeoff between factuality and coverage. We introduce ClaimDiff-RL, a framework that uses reference-conditioned atomic claim differences as the reward unit for caption RL. Given an image, an actor caption, and a reference caption, a multimodal judge enumerates visually grounded differences, verifies each difference against the image, assigns open-vocabulary error types and severity levels, and produces per-difference statistics for reward composition. This makes hallucinated claims and omitted salient facts separately measurable and tunable. Experiments show that holistic scalar rewards can reduce hallucination by increasing missing facts, while ClaimDiff-RL exposes this faithfulness and coverage tradeoff and enables more balanced operating points. On a 160-image human-labeled diagnostic benchmark, public captioning benchmarks, and VQA benchmarks, ClaimDiff-RL improves the hallucination--missing-fact balance, preserves general capability, and even surpasses Gemini-3-Pro-Preview on several fine-grained Capability dimensions such as object counting, spatial relations, and scene recognition. These results suggest that typed, verifiable claim differences are an effective reward unit for fine-grained and diagnosable caption RL.
Uncertainty-Guided Latent Diagnostic Trajectory Learning for Sequential Clinical Diagnosis
Apr 06, 2026Clinical diagnosis requires sequential evidence acquisition under uncertainty. However, most Large Language Model (LLM) based diagnostic systems assume fully observed patient information and therefore do not explicitly model how clinical evidence should be sequentially acquired over time. Even when diagnosis is formulated as a sequential decision process, it is still challenging to learn effective diagnostic trajectories. This is because the space of possible evidence-acquisition paths is relatively large, while clinical datasets rarely provide explicit supervision information for desirable diagnostic paths. To this end, we formulate sequential diagnosis as a Latent Diagnostic Trajectory Learning (LDTL) framework based on a planning LLM agent and a diagnostic LLM agent. For the diagnostic LLM agent, diagnostic action sequences are treated as latent paths and we introduce a posterior distribution that prioritizes trajectories providing more diagnostic information. The planning LLM agent is then trained to follow this distribution, encouraging coherent diagnostic trajectories that progressively reduce uncertainty. Experiments on the MIMIC-CDM benchmark demonstrate that our proposed LDTL framework outperforms existing baselines in diagnostic accuracy under a sequential clinical diagnosis setting, while requiring fewer diagnostic tests. Furthermore, ablation studies highlight the critical role of trajectory-level posterior alignment in achieving these improvements.
Empowering Power Outage Prediction with Spatially Aware Hybrid Graph Neural Networks and Contrastive Learning
Apr 06, 2026Extreme weather events, such as severe storms, hurricanes, snowstorms, and ice storms, which are exacerbated by climate change, frequently cause widespread power outages. These outages halt industrial operations, impact communities, damage critical infrastructure, profoundly disrupt economies, and have far-reaching effects across various sectors. To mitigate these effects, the University of Connecticut and Eversource Energy Center have developed an outage prediction modeling (OPM) system to provide pre-emptive forecasts for electric distribution networks before such weather events occur. However, existing predictive models in the system do not incorporate the spatial effect of extreme weather events. To this end, we develop Spatially Aware Hybrid Graph Neural Networks (SA-HGNN) with contrastive learning to enhance the OPM predictions for extreme weather-induced power outages. Specifically, we first encode spatial relationships of both static features (e.g., land cover, infrastructure) and event-specific dynamic features (e.g., wind speed, precipitation) via Spatially Aware Hybrid Graph Neural Networks (SA-HGNN). Next, we leverage contrastive learning to handle the imbalance problem associated with different types of extreme weather events and generate location-specific embeddings by minimizing intra-event distances between similar locations while maximizing inter-event distances across all locations. Thorough empirical studies in four utility service territories, i.e., Connecticut, Western Massachusetts, Eastern Massachusetts, and New Hampshire, demonstrate that SA-HGNN can achieve state-of-the-art performance for power outage prediction.
FlashSampling: Fast and Memory-Efficient Exact Sampling
Mar 16, 2026Sampling from a categorical distribution is mathematically simple, but in large-vocabulary decoding, it often triggers extra memory traffic and extra kernels after the LM head. We present FlashSampling, an exact sampling primitive that fuses sampling into the LM-head matmul and never materializes the logits tensor in HBM. The method is simple: compute logits tile-by-tile on chip, add Gumbel noise, keep only one maximizer per row and per vocabulary tile, and finish with a small reduction over tiles. The fused tiled kernel is exact because $\argmax$ decomposes over a partition; grouped variants for online and tensor-parallel settings are exact by hierarchical factorization of the categorical distribution. Across H100, H200, B200, and B300 GPUs, FlashSampling speeds up kernel-level decode workloads, and in end-to-end vLLM experiments, it reduces time per output token by up to $19%$ on the models we test. These results show that exact sampling, with no approximation, can be integrated into the matmul itself, turning a bandwidth-bound postprocessing step into a lightweight epilogue. Project Page: https://github.com/FlashSampling/FlashSampling.
What Does Vision Tool-Use Reinforcement Learning Really Learn? Disentangling Tool-Induced and Intrinsic Effects for Crop-and-Zoom
Feb 01, 2026Vision tool-use reinforcement learning (RL) can equip vision-language models with visual operators such as crop-and-zoom and achieves strong performance gains, yet it remains unclear whether these gains are driven by improvements in tool use or evolving intrinsic capabilities.We introduce MED (Measure-Explain-Diagnose), a coarse-to-fine framework that disentangles intrinsic capability changes from tool-induced effects, decomposes the tool-induced performance difference into gain and harm terms, and probes the mechanisms driving their evolution. Across checkpoint-level analyses on two VLMs with different tool priors and six benchmarks, we find that improvements are dominated by intrinsic learning, while tool-use RL mainly reduces tool-induced harm (e.g., fewer call-induced errors and weaker tool schema interference) and yields limited progress in tool-based correction of intrinsic failures. Overall, current vision tool-use RL learns to coexist safely with tools rather than master them.
Elucidating the Design Space of Decay in Linear Attention
Sep 05, 2025This paper presents a comprehensive investigation into the decay mechanisms inherent in linear complexity sequence models. We systematically delineate the design space of decay mechanisms across four pivotal dimensions: parameterization strategy, which refers to the computational methodology for decay; parameter sharing, which involves the utilization of supplementary parameters for decay computation; decay granularity, comparing scalar versus vector-based decay; and compatibility with relative positional encoding methods, such as Rotary Position Embedding (RoPE). Through an extensive series of experiments conducted on diverse language modeling tasks, we uncovered several critical insights. Firstly, the design of the parameterization strategy for decay requires meticulous consideration. Our findings indicate that effective configurations are typically confined to a specific range of parameters. Secondly, parameter sharing cannot be used arbitrarily, as it may cause decay values to be too large or too small, thereby significantly impacting performance. Thirdly, under identical parameterization strategies, scalar decay generally underperforms compared to its vector-based counterpart. However, in certain scenarios with alternative parameterization strategies, scalar decay may unexpectedly surpass vector decay in efficacy. Lastly, our analysis reveals that RoPE, a commonly employed relative positional encoding method, typically fails to provide tangible benefits to the majority of linear attention mechanisms.
Autoregressive Image Generation with Linear Complexity: A Spatial-Aware Decay Perspective
Jul 02, 2025Autoregressive (AR) models have garnered significant attention in image generation for their ability to effectively capture both local and global structures within visual data. However, prevalent AR models predominantly rely on the transformer architectures, which are beset by quadratic computational complexity concerning input sequence length and substantial memory overhead due to the necessity of maintaining key-value caches. Although linear attention mechanisms have successfully reduced this burden in language models, our initial experiments reveal that they significantly degrade image generation quality because of their inability to capture critical long-range dependencies in visual data. We propose Linear Attention with Spatial-Aware Decay (LASAD), a novel attention mechanism that explicitly preserves genuine 2D spatial relationships within the flattened image sequences by computing position-dependent decay factors based on true 2D spatial location rather than 1D sequence positions. Based on this mechanism, we present LASADGen, an autoregressive image generator that enables selective attention to relevant spatial contexts with linear complexity. Experiments on ImageNet show LASADGen achieves state-of-the-art image generation performance and computational efficiency, bridging the gap between linear attention's efficiency and spatial understanding needed for high-quality generation.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
One RL to See Them All: Visual Triple Unified Reinforcement Learning
May 23, 2025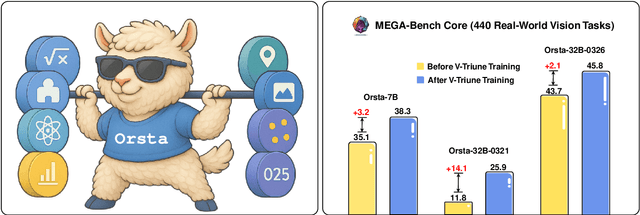
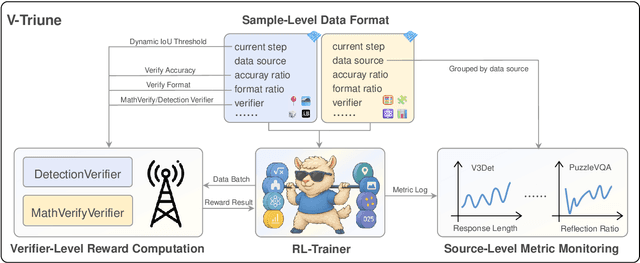
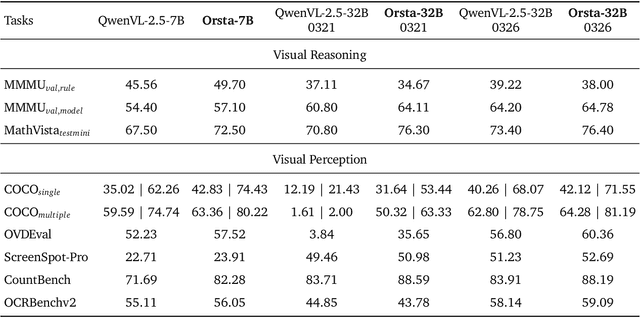
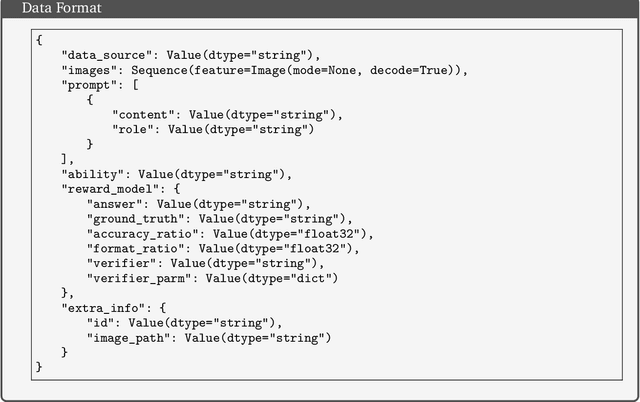
Reinforcement learning (RL) has significantly advanced the reasoning capabilities of vision-language models (VLMs). However, the use of RL beyond reasoning tasks remains largely unexplored, especially for perceptionintensive tasks like object detection and grounding. We propose V-Triune, a Visual Triple Unified Reinforcement Learning system that enables VLMs to jointly learn visual reasoning and perception tasks within a single training pipeline. V-Triune comprises triple complementary components: Sample-Level Data Formatting (to unify diverse task inputs), Verifier-Level Reward Computation (to deliver custom rewards via specialized verifiers) , and Source-Level Metric Monitoring (to diagnose problems at the data-source level). We further introduce a novel Dynamic IoU reward, which provides adaptive, progressive, and definite feedback for perception tasks handled by V-Triune. Our approach is instantiated within off-the-shelf RL training framework using open-source 7B and 32B backbone models. The resulting model, dubbed Orsta (One RL to See Them All), demonstrates consistent improvements across both reasoning and perception tasks. This broad capability is significantly shaped by its training on a diverse dataset, constructed around four representative visual reasoning tasks (Math, Puzzle, Chart, and Science) and four visual perception tasks (Grounding, Detection, Counting, and OCR). Subsequently, Orsta achieves substantial gains on MEGA-Bench Core, with improvements ranging from +2.1 to an impressive +14.1 across its various 7B and 32B model variants, with performance benefits extending to a wide range of downstream tasks. These results highlight the effectiveness and scalability of our unified RL approach for VLMs. The V-Triune system, along with the Orsta models, is publicly available at https://github.com/MiniMax-AI.
Rethinking RL Scaling for Vision Language Models: A Transparent, From-Scratch Framework and Comprehensive Evaluation Scheme
Apr 03, 2025Reinforcement learning (RL) has recently shown strong potential in improving the reasoning capabilities of large language models and is now being actively extended to vision-language models (VLMs). However, existing RL applications in VLMs often rely on heavily engineered frameworks that hinder reproducibility and accessibility, while lacking standardized evaluation protocols, making it difficult to compare results or interpret training dynamics. This work introduces a transparent, from-scratch framework for RL in VLMs, offering a minimal yet functional four-step pipeline validated across multiple models and datasets. In addition, a standardized evaluation scheme is proposed to assess training dynamics and reflective behaviors. Extensive experiments on visual reasoning tasks uncover key empirical findings: response length is sensitive to random seeds, reflection correlates with output length, and RL consistently outperforms supervised fine-tuning (SFT) in generalization, even with high-quality data. These findings, together with the proposed framework, aim to establish a reproducible baseline and support broader engagement in RL-based VLM research.