 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSR: A Training-Free Approach for Streaming 3D Reconstruction
Mar 16, 2026Streaming 3D reconstruction demands long-horizon state updates under strict latency constraints, yet stateful recurrent models often suffer from geometric drift as errors accumulate over time. We revisit this problem from a Grassmannian manifold perspective: the latent persistent state can be viewed as a subspace representation, i.e., a point evolving on a Grassmannian manifold, where temporal coherence implies the state trajectory should remain on (or near) this manifold.Based on this view, we propose Self-expressive Sequence Regularization (SSR), a plug-and-play, training-free operator that enforces Grassmannian sequence regularity during inference.Given a window of historical states, SSR computes an analytical affinity matrix via the self-expressive property and uses it to regularize the current update, effectively pulling noisy predictions back toward the manifold-consistent trajectory with minimal overhead. Experiments on long-sequence benchmarks demonstrate that SSR consistently reduces drift and improves reconstruction quality across multiple streaming 3D reconstruction tasks.
CLASP: Cross-modal Salient Anchor-based Semantic Propagation for Weakly-supervised Dense Audio-Visual Event Localization
Aug 06, 2025The Dense Audio-Visual Event Localization (DAVEL) task aims to temporally localize events in untrimmed videos that occur simultaneously in both the audio and visual modalities. This paper explores DAVEL under a new and more challenging weakly-supervised setting (W-DAVEL task), where only video-level event labels are provided and the temporal boundaries of each event are unknown. We address W-DAVEL by exploiting \textit{cross-modal salient anchors}, which are defined as reliable timestamps that are well predicted under weak supervision and exhibit highly consistent event semantics across audio and visual modalities. Specifically, we propose a \textit{Mutual Event Agreement Evaluation} module, which generates an agreement score by measuring the discrepancy between the predicted audio and visual event classes. Then, the agreement score is utilized in a \textit{Cross-modal Salient Anchor Identification} module, which identifies the audio and visual anchor features through global-video and local temporal window identification mechanisms. The anchor features after multimodal integration are fed into an \textit{Anchor-based Temporal Propagation} module to enhance event semantic encoding in the original temporal audio and visual features, facilitating better temporal localization under weak supervision. We establish benchmarks for W-DAVEL on both the UnAV-100 and ActivityNet1.3 datasets. Extensive experiments demonstrate that our method achieves state-of-the-art performance.
Autoregressive Image Generation with Linear Complexity: A Spatial-Aware Decay Perspective
Jul 02, 2025Autoregressive (AR) models have garnered significant attention in image generation for their ability to effectively capture both local and global structures within visual data. However, prevalent AR models predominantly rely on the transformer architectures, which are beset by quadratic computational complexity concerning input sequence length and substantial memory overhead due to the necessity of maintaining key-value caches. Although linear attention mechanisms have successfully reduced this burden in language models, our initial experiments reveal that they significantly degrade image generation quality because of their inability to capture critical long-range dependencies in visual data. We propose Linear Attention with Spatial-Aware Decay (LASAD), a novel attention mechanism that explicitly preserves genuine 2D spatial relationships within the flattened image sequences by computing position-dependent decay factors based on true 2D spatial location rather than 1D sequence positions. Based on this mechanism, we present LASADGen, an autoregressive image generator that enables selective attention to relevant spatial contexts with linear complexity. Experiments on ImageNet show LASADGen achieves state-of-the-art image generation performance and computational efficiency, bridging the gap between linear attention's efficiency and spatial understanding needed for high-quality generation.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
MiniMax-01: Scaling Foundation Models with Lightning Attention
Jan 14, 2025We introduce MiniMax-01 series, including MiniMax-Text-01 and MiniMax-VL-01, which are comparable to top-tier models while offering superior capabilities in processing longer contexts. The core lies in lightning attention and its efficient scaling. To maximize computational capacity, we integrate it with Mixture of Experts (MoE), creating a model with 32 experts and 456 billion total parameters, of which 45.9 billion are activated for each token. We develop an optimized parallel strategy and highly efficient computation-communication overlap techniques for MoE and lightning attention. This approach enables us to conduct efficient training and inference on models with hundreds of billions of parameters across contexts spanning millions of tokens. The context window of MiniMax-Text-01 can reach up to 1 million tokens during training and extrapolate to 4 million tokens during inference at an affordable cost. Our vision-language model, MiniMax-VL-01 is built through continued training with 512 billion vision-language tokens. Experiments on both standard and in-house benchmarks show that our models match the performance of state-of-the-art models like GPT-4o and Claude-3.5-Sonnet while offering 20-32 times longer context window. We publicly release MiniMax-01 at https://github.com/MiniMax-AI.
Tri-Ergon: Fine-grained Video-to-Audio Generation with Multi-modal Conditions and LUFS Control
Dec 29, 2024Video-to-audio (V2A) generation utilizes visual-only video features to produce realistic sounds that correspond to the scene. However, current V2A models often lack fine-grained control over the generated audio, especially in terms of loudness variation and the incorporation of multi-modal conditions. To overcome these limitations, we introduce Tri-Ergon, a diffusion-based V2A model that incorporates textual, auditory, and pixel-level visual prompts to enable detailed and semantically rich audio synthesis. Additionally, we introduce Loudness Units relative to Full Scale (LUFS) embedding, which allows for precise manual control of the loudness changes over time for individual audio channels, enabling our model to effectively address the intricate correlation of video and audio in real-world Foley workflows. Tri-Ergon is capable of creating 44.1 kHz high-fidelity stereo audio clips of varying lengths up to 60 seconds, which significantly outperforms existing state-of-the-art V2A methods that typically generate mono audio for a fixed duration.
Towards Open-Vocabulary Audio-Visual Event Localization
Nov 18, 2024The Audio-Visual Event Localization (AVEL) task aims to temporally locate and classify video events that are both audible and visible. Most research in this field assumes a closed-set setting, which restricts these models' ability to handle test data containing event categories absent (unseen) during training. Recently, a few studies have explored AVEL in an open-set setting, enabling the recognition of unseen events as ``unknown'', but without providing category-specific semantics. In this paper, we advance the field by introducing the Open-Vocabulary Audio-Visual Event Localization (OV-AVEL) problem, which requires localizing audio-visual events and predicting explicit categories for both seen and unseen data at inference. To address this new task, we propose the OV-AVEBench dataset, comprising 24,800 videos across 67 real-life audio-visual scenes (seen:unseen = 46:21), each with manual segment-level annotation. We also establish three evaluation metrics for this task. Moreover, we investigate two baseline approaches, one training-free and one using a further fine-tuning paradigm. Specifically, we utilize the unified multimodal space from the pretrained ImageBind model to extract audio, visual, and textual (event classes) features. The training-free baseline then determines predictions by comparing the consistency of audio-text and visual-text feature similarities. The fine-tuning baseline incorporates lightweight temporal layers to encode temporal relations within the audio and visual modalities, using OV-AVEBench training data for model fine-tuning. We evaluate these baselines on the proposed OV-AVEBench dataset and discuss potential directions for future work in this new field.
Label-anticipated Event Disentanglement for Audio-Visual Video Parsing
Jul 11, 2024Audio-Visual Video Parsing (AVVP) task aims to detect and temporally locate events within audio and visual modalities. Multiple events can overlap in the timeline, making identification challenging. While traditional methods usually focus on improving the early audio-visual encoders to embed more effective features, the decoding phase -- crucial for final event classification, often receives less attention. We aim to advance the decoding phase and improve its interpretability. Specifically, we introduce a new decoding paradigm, \underline{l}abel s\underline{e}m\underline{a}ntic-based \underline{p}rojection (LEAP), that employs labels texts of event categories, each bearing distinct and explicit semantics, for parsing potentially overlapping events.LEAP works by iteratively projecting encoded latent features of audio/visual segments onto semantically independent label embeddings. This process, enriched by modeling cross-modal (audio/visual-label) interactions, gradually disentangles event semantics within video segments to refine relevant label embeddings, guaranteeing a more discriminative and interpretable decoding process. To facilitate the LEAP paradigm, we propose a semantic-aware optimization strategy, which includes a novel audio-visual semantic similarity loss function. This function leverages the Intersection over Union of audio and visual events (EIoU) as a novel metric to calibrate audio-visual similarities at the feature level, accommodating the varied event densities across modalities. Extensive experiments demonstrate the superiority of our method, achieving new state-of-the-art performance for AVVP and also enhancing the relevant audio-visual event localization task.
You Only Scan Once: Efficient Multi-dimension Sequential Modeling with LightNet
May 31, 2024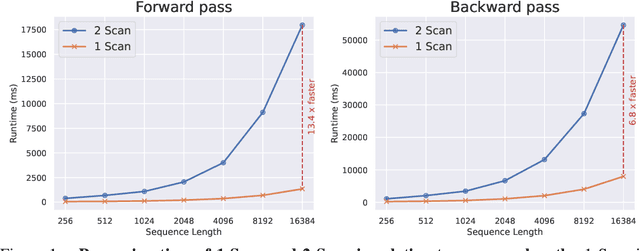
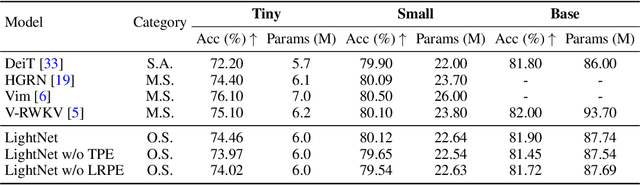
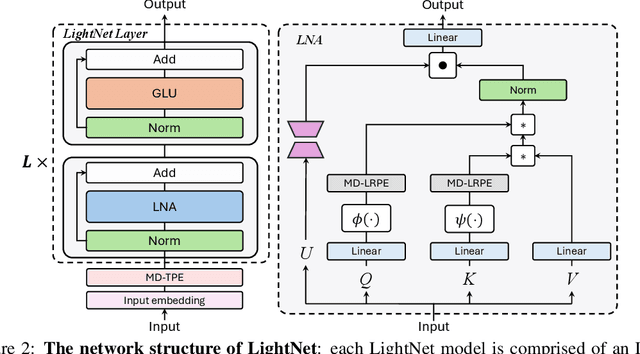
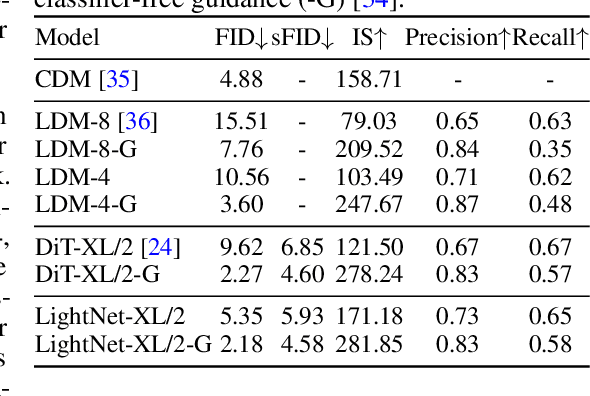
Linear attention mechanisms have gained prominence in causal language models due to their linear computational complexity and enhanced speed. However, the inherent decay mechanism in linear attention presents challenges when applied to multi-dimensional sequence modeling tasks, such as image processing and multi-modal learning. In these scenarios, the utilization of sequential scanning to establish a global receptive field necessitates multiple scans for multi-dimensional data, thereby leading to inefficiencies. This paper identifies the inefficiency caused by a multiplicative linear recurrence and proposes an efficient alternative additive linear recurrence to avoid the issue, as it can handle multi-dimensional data within a single scan. We further develop an efficient multi-dimensional sequential modeling framework called LightNet based on the new recurrence. Moreover, we present two new multi-dimensional linear relative positional encoding methods, MD-TPE and MD-LRPE to enhance the model's ability to discern positional information in multi-dimensional scenarios. Our empirical evaluations across various tasks, including image classification, image generation, bidirectional language modeling, and autoregressive language modeling, demonstrate the efficacy of LightNet, showcasing its potential as a versatile and efficient solution for multi-dimensional sequential modeling.
TAVGBench: Benchmarking Text to Audible-Video Generation
Apr 22, 2024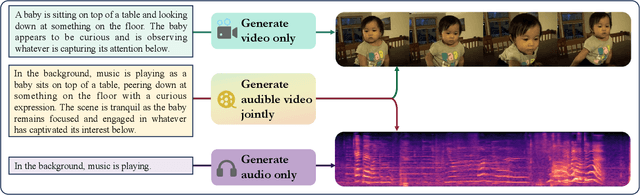

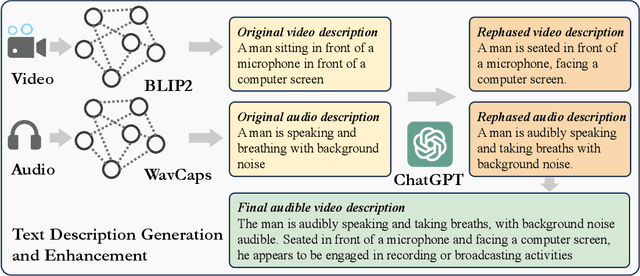

The Text to Audible-Video Generation (TAVG) task involves generating videos with accompanying audio based on text descriptions. Achieving this requires skillful alignment of both audio and video elements. To support research in this field, we have developed a comprehensive Text to Audible-Video Generation Benchmark (TAVGBench), which contains over 1.7 million clips with a total duration of 11.8 thousand hours. We propose an automatic annotation pipeline to ensure each audible video has detailed descriptions for both its audio and video contents. We also introduce the Audio-Visual Harmoni score (AVHScore) to provide a quantitative measure of the alignment between the generated audio and video modalities. Additionally, we present a baseline model for TAVG called TAVDiffusion, which uses a two-stream latent diffusion model to provide a fundamental starting point for further research in this area. We achieve the alignment of audio and video by employing cross-attention and contrastive learning. Through extensive experiments and evaluations on TAVGBench, we demonstrate the effectiveness of our proposed model under both conventional metrics and our proposed metrics.