 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAVGBench: Benchmarking Text to Audible-Video Generation
Paper and Code
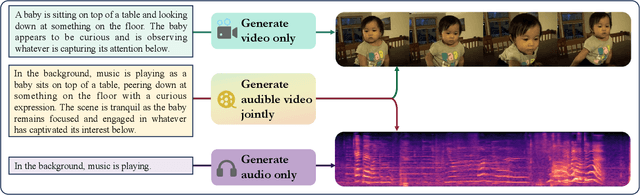

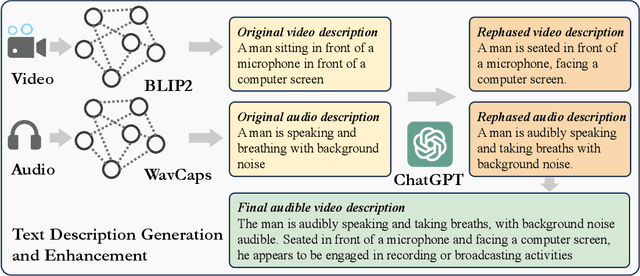

The Text to Audible-Video Generation (TAVG) task involves generating videos with accompanying audio based on text descriptions. Achieving this requires skillful alignment of both audio and video elements. To support research in this field, we have developed a comprehensive Text to Audible-Video Generation Benchmark (TAVGBench), which contains over 1.7 million clips with a total duration of 11.8 thousand hours. We propose an automatic annotation pipeline to ensure each audible video has detailed descriptions for both its audio and video contents. We also introduce the Audio-Visual Harmoni score (AVHScore) to provide a quantitative measure of the alignment between the generated audio and video modalities. Additionally, we present a baseline model for TAVG called TAVDiffusion, which uses a two-stream latent diffusion model to provide a fundamental starting point for further research in this area. We achieve the alignment of audio and video by employing cross-attention and contrastive learning. Through extensive experiments and evaluations on TAVGBench, we demonstrate the effectiveness of our proposed model under both conventional metrics and our proposed metrics.