 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSR: A Training-Free Approach for Streaming 3D Reconstruction
Mar 16, 2026Streaming 3D reconstruction demands long-horizon state updates under strict latency constraints, yet stateful recurrent models often suffer from geometric drift as errors accumulate over time. We revisit this problem from a Grassmannian manifold perspective: the latent persistent state can be viewed as a subspace representation, i.e., a point evolving on a Grassmannian manifold, where temporal coherence implies the state trajectory should remain on (or near) this manifold.Based on this view, we propose Self-expressive Sequence Regularization (SSR), a plug-and-play, training-free operator that enforces Grassmannian sequence regularity during inference.Given a window of historical states, SSR computes an analytical affinity matrix via the self-expressive property and uses it to regularize the current update, effectively pulling noisy predictions back toward the manifold-consistent trajectory with minimal overhead. Experiments on long-sequence benchmarks demonstrate that SSR consistently reduces drift and improves reconstruction quality across multiple streaming 3D reconstruction tasks.
RnG: A Unified Transformer for Complete 3D Modeling from Partial Observations
Mar 01, 2026Human perceive the 3D world through 2D observations from limited viewpoints. While recent feed-forward generalizable 3D reconstruction models excel at recovering 3D structures from sparse images, their representations are often confined to observed regions, leaving unseen geometry un-modeled. This raises a key, fundamental challenge: Can we infer a complete 3D structure from partial 2D observations? We present RnG (Reconstruction and Generation), a novel feed-forward Transformer that unifies these two tasks by predicting an implicit, complete 3D representation. At the core of RnG, we propose a reconstruction-guided causal attention mechanism that separates reconstruction and generation at the attention level, and treats the KV-cache as an implicit 3D representation. Then, arbitrary poses can efficiently query this cache to render high-fidelity, novel-view RGBD outputs. As a result, RnG not only accurately reconstructs visible geometry but also generates plausible, coherent unseen geometry and appearance. Our method achieves state-of-the-art performance in both generalizable 3D reconstruction and novel view generation, while operating efficiently enough for real-time interactive applications. Project page: https://npucvr.github.io/RnG
MixRI: Mixing Features of Reference Images for Novel Object Pose Estimation
Jan 11, 2026We present MixRI, a lightweight network that solves the CAD-based novel object pose estimation problem in RGB images. It can be instantly applied to a novel object at test time without finetuning. We design our network to meet the demands of real-world applications, emphasizing reduced memory requirements and fast inference time. Unlike existing works that utilize many reference images and have large network parameters, we directly match points based on the multi-view information between the query and reference images with a lightweight network. Thanks to our reference image fusion strategy, we significantly decrease the number of reference images, thus decreasing the time needed to process these images and the memory required to store them. Furthermore, with our lightweight network, our method requires less inference time. Though with fewer reference images, experiments on seven core datasets in the BOP challenge show that our method achieves comparable results with other methods that require more reference images and larger network parameters.
* Accepted by ICCV 2025
Focus Through Motion: RGB-Event Collaborative Token Sparsification for Efficient Object Detection
Sep 04, 2025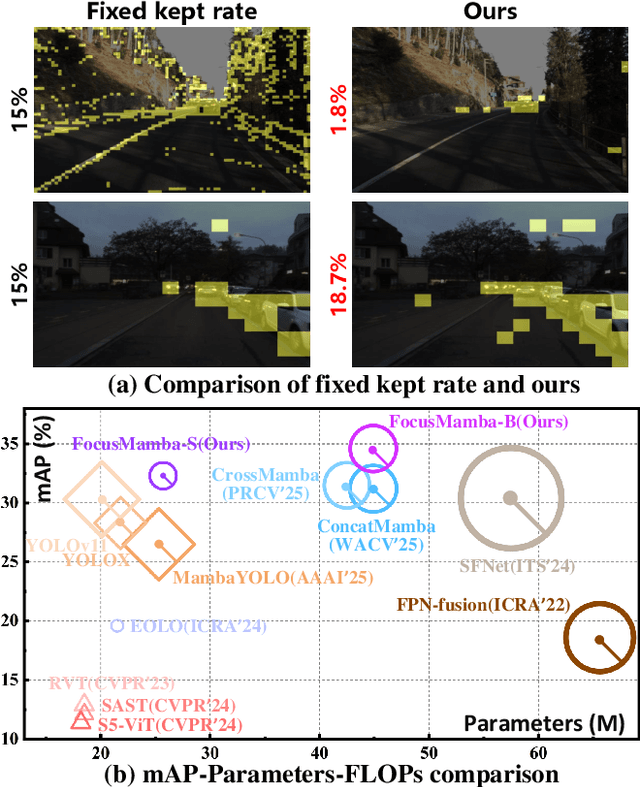
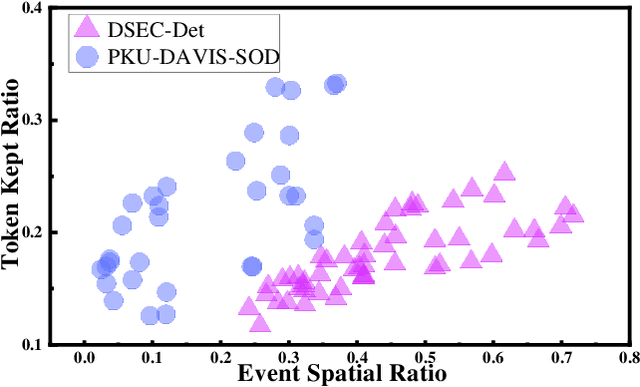
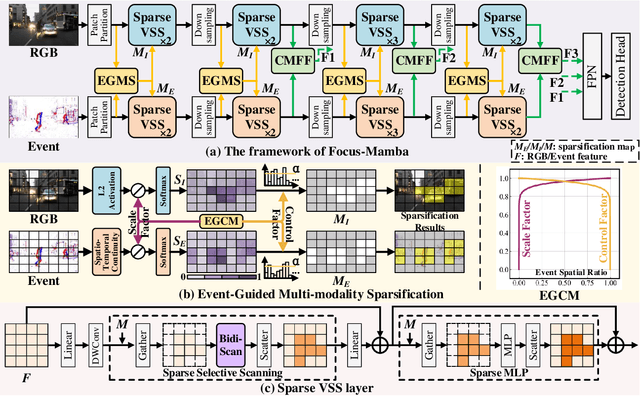
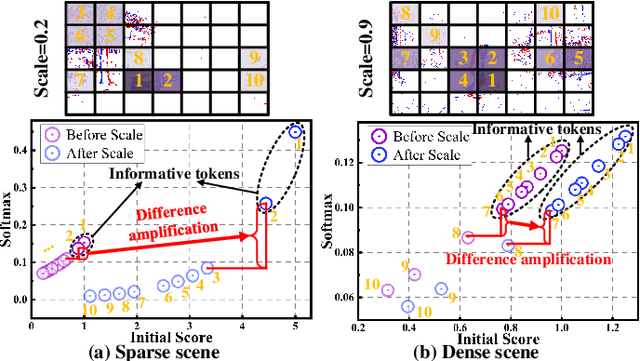
Existing RGB-Event detection methods process the low-information regions of both modalities (background in images and non-event regions in event data) uniformly during feature extraction and fusion, resulting in high computational costs and suboptimal performance. To mitigate the computational redundancy during feature extraction, researchers have respectively proposed token sparsification methods for the image and event modalities. However, these methods employ a fixed number or threshold for token selection, hindering the retention of informative tokens for samples with varying complexity. To achieve a better balance between accuracy and efficiency, we propose FocusMamba, which performs adaptive collaborative sparsification of multimodal features and efficiently integrates complementary information. Specifically, an Event-Guided Multimodal Sparsification (EGMS) strategy is designed to identify and adaptively discard low-information regions within each modality by leveraging scene content changes perceived by the event camera. Based on the sparsification results, a Cross-Modality Focus Fusion (CMFF) module is proposed to effectively capture and integrate complementary features from both modalities. Experiments on the DSEC-Det and PKU-DAVIS-SOD datasets demonstrate that the proposed method achieves superior performance in both accuracy and efficiency compared to existing methods. The code will be available at https://github.com/Zizzzzzzz/FocusMamba.
PanoSplatt3R: Leveraging Perspective Pretraining for Generalized Unposed Wide-Baseline Panorama Reconstruction
Jul 29, 2025Wide-baseline panorama reconstruction has emerged as a highly effective and pivotal approach for not only achieving geometric reconstruction of the surrounding 3D environment, but also generating highly realistic and immersive novel views. Although existing methods have shown remarkable performance across various benchmarks, they are predominantly reliant on accurate pose information. In real-world scenarios, the acquisition of precise pose often requires additional computational resources and is highly susceptible to noise. These limitations hinder the broad applicability and practicality of such methods. In this paper, we present PanoSplatt3R, an unposed wide-baseline panorama reconstruction method. We extend and adapt the foundational reconstruction pretrainings from the perspective domain to the panoramic domain, thus enabling powerful generalization capabilities. To ensure a seamless and efficient domain-transfer process, we introduce RoPE rolling that spans rolled coordinates in rotary positional embeddings across different attention heads, maintaining a minimal modification to RoPE's mechanism, while modeling the horizontal periodicity of panorama images. Comprehensive experiments demonstrate that PanoSplatt3R, even in the absence of pose information, significantly outperforms current state-of-the-art methods. This superiority is evident in both the generation of high-quality novel views and the accuracy of depth estimation, thereby showcasing its great potential for practical applications. Project page: https://npucvr.github.io/PanoSplatt3R
Autoregressive Image Generation with Linear Complexity: A Spatial-Aware Decay Perspective
Jul 02, 2025Autoregressive (AR) models have garnered significant attention in image generation for their ability to effectively capture both local and global structures within visual data. However, prevalent AR models predominantly rely on the transformer architectures, which are beset by quadratic computational complexity concerning input sequence length and substantial memory overhead due to the necessity of maintaining key-value caches. Although linear attention mechanisms have successfully reduced this burden in language models, our initial experiments reveal that they significantly degrade image generation quality because of their inability to capture critical long-range dependencies in visual data. We propose Linear Attention with Spatial-Aware Decay (LASAD), a novel attention mechanism that explicitly preserves genuine 2D spatial relationships within the flattened image sequences by computing position-dependent decay factors based on true 2D spatial location rather than 1D sequence positions. Based on this mechanism, we present LASADGen, an autoregressive image generator that enables selective attention to relevant spatial contexts with linear complexity. Experiments on ImageNet show LASADGen achieves state-of-the-art image generation performance and computational efficiency, bridging the gap between linear attention's efficiency and spatial understanding needed for high-quality generation.
The Meeseeks Mesh: Spatially Consistent 3D Adversarial Objects for BEV Detector
May 29, 20253D object detection is a critical component in autonomous driving systems. It allows real-time recognition and detection of vehicles, pedestrians and obstacles under varying environmental conditions. Among existing methods, 3D object detection in the Bird's Eye View (BEV) has emerged as the mainstream framework. To guarantee a safe, robust and trustworthy 3D object detection, 3D adversarial attacks are investigated, where attacks are placed in 3D environments to evaluate the model performance, e.g. putting a film on a car, clothing a pedestrian. The vulnerability of 3D object detection models to 3D adversarial attacks serves as an important indicator to evaluate the robustness of the model against perturbations. To investigate this vulnerability, we generate non-invasive 3D adversarial objects tailored for real-world attack scenarios. Our method verifies the existence of universal adversarial objects that are spatially consistent across time and camera views. Specifically, we employ differentiable rendering techniques to accurately model the spatial relationship between adversarial objects and the target vehicle. Furthermore, we introduce an occlusion-aware module to enhance visual consistency and realism under different viewpoints. To maintain attack effectiveness across multiple frames, we design a BEV spatial feature-guided optimization strategy. Experimental results demonstrate that our approach can reliably suppress vehicle predictions from state-of-the-art 3D object detectors, serving as an important tool to test robustness of 3D object detection models before deployment. Moreover, the generated adversarial objects exhibit strong generalization capabilities, retaining its effectiveness at various positions and distances in the scene.
One RL to See Them All: Visual Triple Unified Reinforcement Learning
May 23, 2025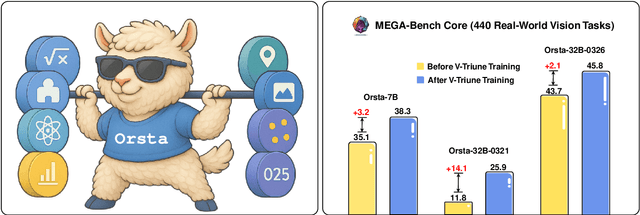
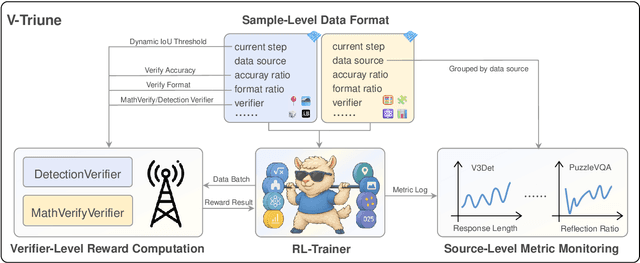
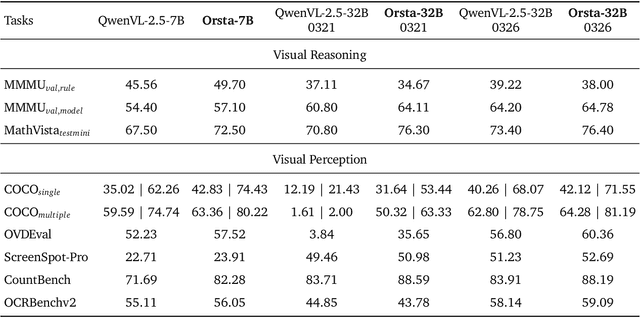
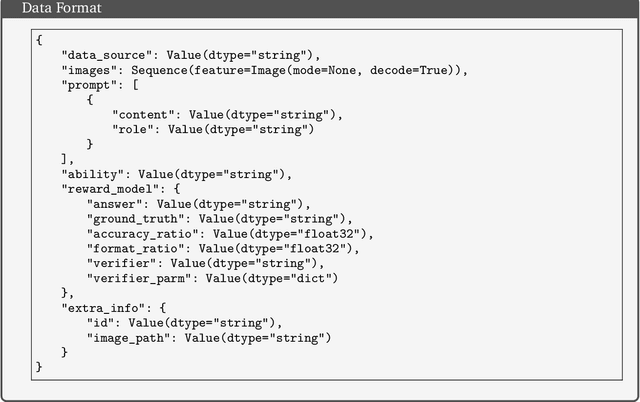
Reinforcement learning (RL) has significantly advanced the reasoning capabilities of vision-language models (VLMs). However, the use of RL beyond reasoning tasks remains largely unexplored, especially for perceptionintensive tasks like object detection and grounding. We propose V-Triune, a Visual Triple Unified Reinforcement Learning system that enables VLMs to jointly learn visual reasoning and perception tasks within a single training pipeline. V-Triune comprises triple complementary components: Sample-Level Data Formatting (to unify diverse task inputs), Verifier-Level Reward Computation (to deliver custom rewards via specialized verifiers) , and Source-Level Metric Monitoring (to diagnose problems at the data-source level). We further introduce a novel Dynamic IoU reward, which provides adaptive, progressive, and definite feedback for perception tasks handled by V-Triune. Our approach is instantiated within off-the-shelf RL training framework using open-source 7B and 32B backbone models. The resulting model, dubbed Orsta (One RL to See Them All), demonstrates consistent improvements across both reasoning and perception tasks. This broad capability is significantly shaped by its training on a diverse dataset, constructed around four representative visual reasoning tasks (Math, Puzzle, Chart, and Science) and four visual perception tasks (Grounding, Detection, Counting, and OCR). Subsequently, Orsta achieves substantial gains on MEGA-Bench Core, with improvements ranging from +2.1 to an impressive +14.1 across its various 7B and 32B model variants, with performance benefits extending to a wide range of downstream tasks. These results highlight the effectiveness and scalability of our unified RL approach for VLMs. The V-Triune system, along with the Orsta models, is publicly available at https://github.com/MiniMax-AI.
CMD: Constraining Multimodal Distribution for Domain Adaptation in Stereo Matching
Apr 30, 2025Recently, learning-based stereo matching methods have achieved great improvement in public benchmarks, where soft argmin and smooth L1 loss play a core contribution to their success. However, in unsupervised domain adaptation scenarios, we observe that these two operations often yield multimodal disparity probability distributions in target domains, resulting in degraded generalization. In this paper, we propose a novel approach, Constrain Multi-modal Distribution (CMD), to address this issue. Specifically, we introduce \textit{uncertainty-regularized minimization} and \textit{anisotropic soft argmin} to encourage the network to produce predominantly unimodal disparity distributions in the target domain, thereby improving prediction accuracy. Experimentally, we apply the proposed method to multiple representative stereo-matching networks and conduct domain adaptation from synthetic data to unlabeled real-world scenes. Results consistently demonstrate improved generalization in both top-performing and domain-adaptable stereo-matching models. The code for CMD will be available at: \href{https://github.com/gallenszl/CMD}{https://github.com/gallenszl/CMD}.
DPMambaIR:All-in-One Image Restoration via Degradation-Aware Prompt State Space Model
Apr 24, 2025All-in-One image restoration aims to address multiple image degradation problems using a single model, significantly reducing training costs and deployment complexity compared to traditional methods that design dedicated models for each degradation type. Existing approaches typically rely on Degradation-specific models or coarse-grained degradation prompts to guide image restoration. However, they lack fine-grained modeling of degradation information and face limitations in balancing multi-task conflicts. To overcome these limitations, we propose DPMambaIR, a novel All-in-One image restoration framework. By integrating a Degradation-Aware Prompt State Space Model (DP-SSM) and a High-Frequency Enhancement Block (HEB), DPMambaIR enables fine-grained modeling of complex degradation information and efficient global integration, while mitigating the loss of high-frequency details caused by task competition. Specifically, the DP-SSM utilizes a pre-trained degradation extractor to capture fine-grained degradation features and dynamically incorporates them into the state space modeling process, enhancing the model's adaptability to diverse degradation types. Concurrently, the HEB supplements high-frequency information, effectively addressing the loss of critical details, such as edges and textures, in multi-task image restoration scenarios. Extensive experiments on a mixed dataset containing seven degradation types show that DPMambaIR achieves the best performance, with 27.69dB and 0.893 in PSNR and SSIM, respectively. These results highlight the potential and superiority of DPMambaIR as a unified solution for All-in-One image restoration.