 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMD: Constraining Multimodal Distribution for Domain Adaptation in Stereo Matching
Apr 30, 2025Recently, learning-based stereo matching methods have achieved great improvement in public benchmarks, where soft argmin and smooth L1 loss play a core contribution to their success. However, in unsupervised domain adaptation scenarios, we observe that these two operations often yield multimodal disparity probability distributions in target domains, resulting in degraded generalization. In this paper, we propose a novel approach, Constrain Multi-modal Distribution (CMD), to address this issue. Specifically, we introduce \textit{uncertainty-regularized minimization} and \textit{anisotropic soft argmin} to encourage the network to produce predominantly unimodal disparity distributions in the target domain, thereby improving prediction accuracy. Experimentally, we apply the proposed method to multiple representative stereo-matching networks and conduct domain adaptation from synthetic data to unlabeled real-world scenes. Results consistently demonstrate improved generalization in both top-performing and domain-adaptable stereo-matching models. The code for CMD will be available at: \href{https://github.com/gallenszl/CMD}{https://github.com/gallenszl/CMD}.
Digging Into Uncertainty-based Pseudo-label for Robust Stereo Matching
Jul 31, 2023
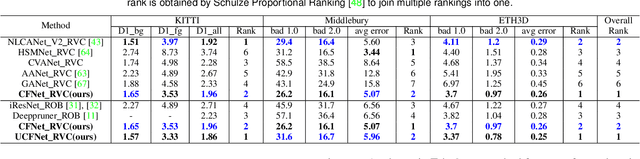

Due to the domain differences and unbalanced disparity distribution across multiple datasets, current stereo matching approaches are commonly limited to a specific dataset and generalize poorly to others. Such domain shift issue is usually addressed by substantial adaptation on costly target-domain ground-truth data, which cannot be easily obtained in practical settings. In this paper, we propose to dig into uncertainty estimation for robust stereo matching. Specifically, to balance the disparity distribution, we employ a pixel-level uncertainty estimation to adaptively adjust the next stage disparity searching space, in this way driving the network progressively prune out the space of unlikely correspondences. Then, to solve the limited ground truth data, an uncertainty-based pseudo-label is proposed to adapt the pre-trained model to the new domain, where pixel-level and area-level uncertainty estimation are proposed to filter out the high-uncertainty pixels of predicted disparity maps and generate sparse while reliable pseudo-labels to align the domain gap. Experimentally, our method shows strong cross-domain, adapt, and joint generalization and obtains \textbf{1st} place on the stereo task of Robust Vision Challenge 2020. Additionally, our uncertainty-based pseudo-labels can be extended to train monocular depth estimation networks in an unsupervised way and even achieves comparable performance with the supervised methods. The code will be available at https://github.com/gallenszl/UCFNet.
CFNet: Cascade and Fused Cost Volume for Robust Stereo Matching
Apr 09, 2021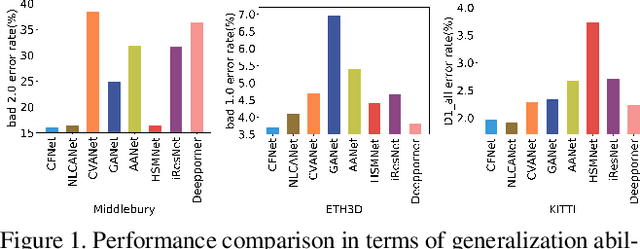
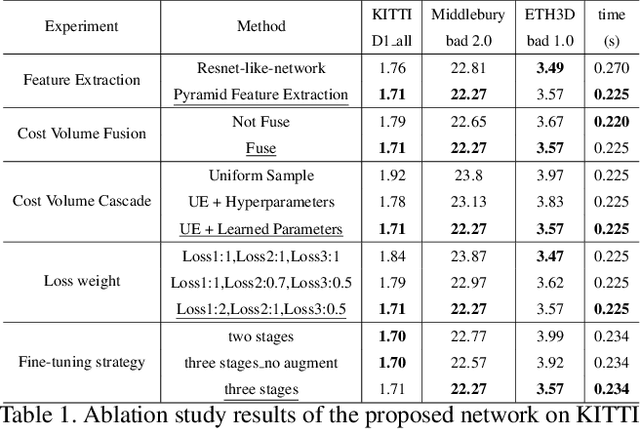
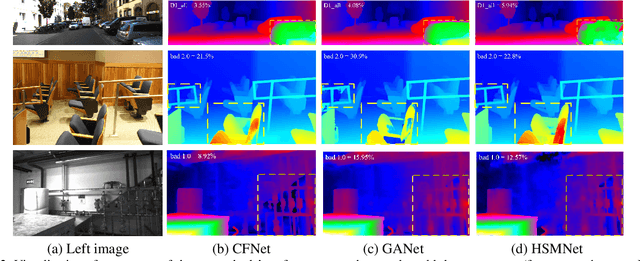
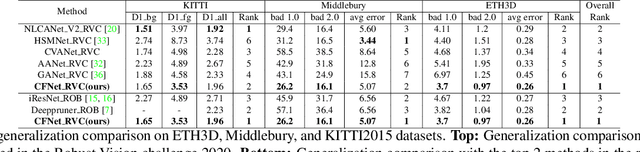
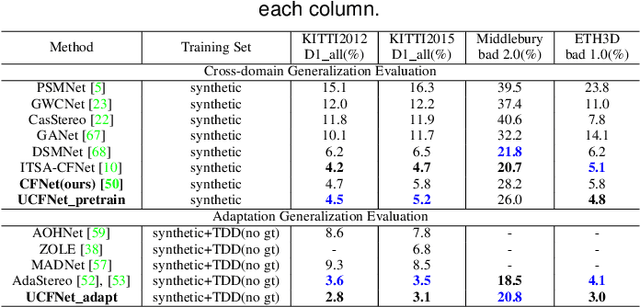
Recently, the ever-increasing capacity of large-scale annotated datasets has led to profound progress in stereo matching. However, most of these successes are limited to a specific dataset and cannot generalize well to other datasets. The main difficulties lie in the large domain differences and unbalanced disparity distribution across a variety of datasets, which greatly limit the real-world applicability of current deep stereo matching models. In this paper, we propose CFNet, a Cascade and Fused cost volume based network to improve the robustness of the stereo matching network. First, we propose a fused cost volume representation to deal with the large domain difference. By fusing multiple low-resolution dense cost volumes to enlarge the receptive field, we can extract robust structural representations for initial disparity estimation. Second, we propose a cascade cost volume representation to alleviate the unbalanced disparity distribution. Specifically, we employ a variance-based uncertainty estimation to adaptively adjust the next stage disparity search space, in this way driving the network progressively prune out the space of unlikely correspondences. By iteratively narrowing down the disparity search space and improving the cost volume resolution, the disparity estimation is gradually refined in a coarse-to-fine manner. When trained on the same training images and evaluated on KITTI, ETH3D, and Middlebury datasets with the fixed model parameters and hyperparameters, our proposed method achieves the state-of-the-art overall performance and obtains the 1st place on the stereo task of Robust Vision Challenge 2020. The code will be available at https://github.com/gallenszl/CFNet.
MSMD-Net: Deep Stereo Matching with Multi-scale and Multi-dimension Cost Volume
Jun 23, 2020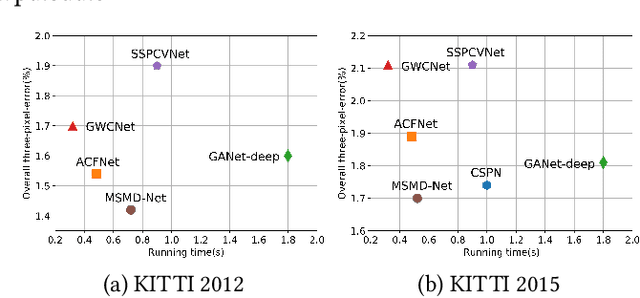
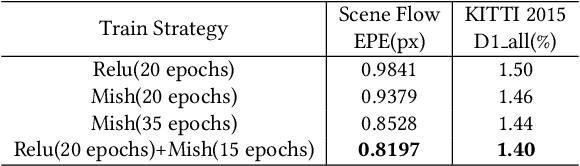

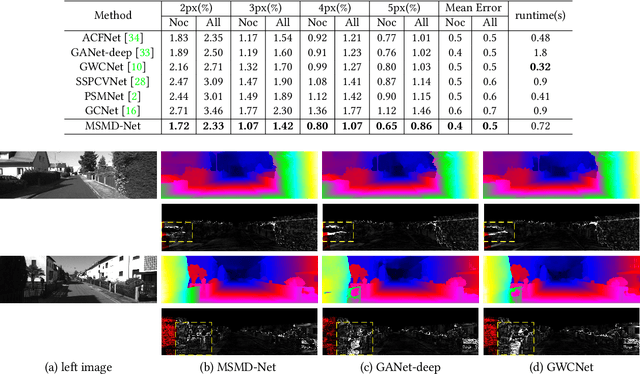
Deep end-to-end learning based stereo matching methods have achieved great success as witnessed by the leaderboards across different benchmarking datasets (KITTI, Middlebury, ETH3D, etc), where the cost volume representation is an indispensable step to the success. However, most existing work only employs a single cost volume, which cannot fully exploit the multi-scale cues in stereo matching and provide guidance for disparity refinement. What's more, the single cost volume representation also limits the disparity range and the resolution of the disparity estimation. In this paper, we propose MSMD-Net (Multi-Scale and Multi-Dimension) to construct multi-scale and multi-dimension cost volume. At the multi-scale level, we generate four 4D combination volumes at different scales and integrate them in 3D cost aggregation to predict an initial disparity estimation. At the multi-dimension level, we construct a 3D warped correlation volume and use it to refine the initial disparity map with residual learning. These two dimensional cost volumes are complementary to each other and can boost the performance of disparity estimation. Additionally, we propose a switch training strategy to further improve the accuracy of disparity estimation, where we switch two kinds of different activation functions to alleviate the overfitting issue in the pre-training process. Our proposed method was evaluated on several benchmark datasets and ranked first on KITTI 2012 leaderboard and second on KITTI 2015 leaderboard as of June 23.The code of MSMD-Net is available at https://github.com/gallenszl/MSMD-Net.
MVS^2: Deep Unsupervised Multi-view Stereo with Multi-View Symmetry
Aug 30, 2019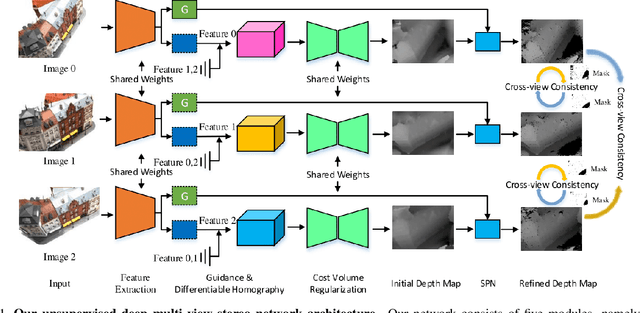
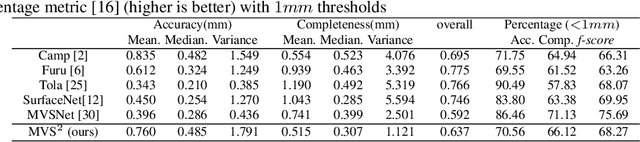


The success of existing deep-learning based multi-view stereo (MVS) approaches greatly depends on the availability of large-scale supervision in the form of dense depth maps. Such supervision, while not always possible, tends to hinder the generalization ability of the learned models in never-seen-before scenarios. In this paper, we propose the first unsupervised learning based MVS network, which learns the multi-view depth maps from the input multi-view images and does not need ground-truth 3D training data. Our network is symmetric in predicting depth maps for all views simultaneously, where we enforce cross-view consistency of multi-view depth maps during both training and testing stages. Thus, the learned multi-view depth maps naturally comply with the underlying 3D scene geometry. Besides, our network also learns the multi-view occlusion maps, which further improves the robustness of our network in handling real-world occlusions. Experimental results on multiple benchmarking datasets demonstrate the effectiveness of our network and the excellent generalization ability.
Multi-scale Cross-form Pyramid Network for Stereo Matching
Jun 04, 2019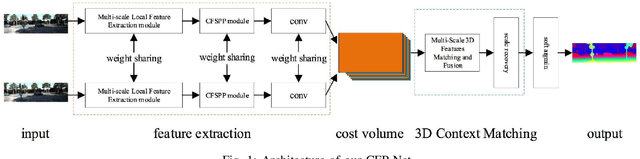

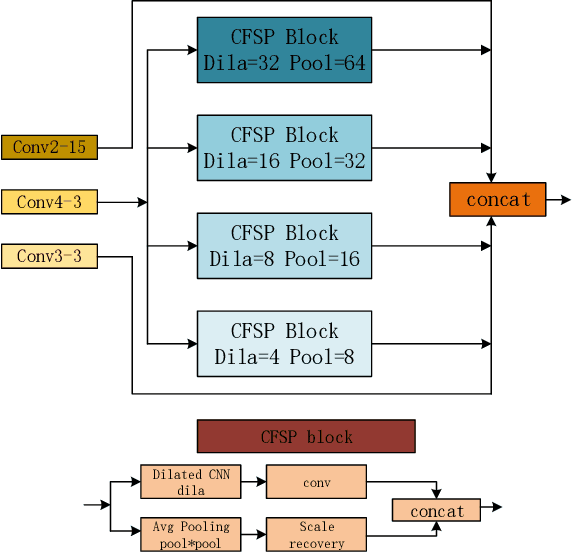
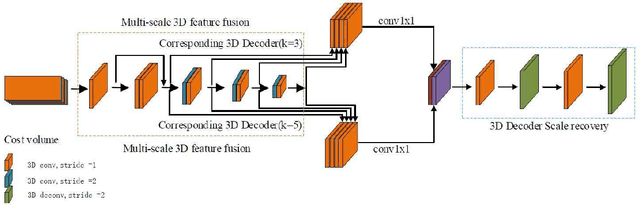
Stereo matching plays an indispensable part in autonomous driving, robotics and 3D scene reconstruction. We propose a novel deep learning architecture, which called CFP-Net, a Cross-Form Pyramid stereo matching network for regressing disparity from a rectified pair of stereo images. The network consists of three modules: Multi-Scale 2D local feature extraction module, Cross-form spatial pyramid module and Multi-Scale 3D Feature Matching and Fusion module. The Multi-Scale 2D local feature extraction module can extract enough multi-scale features. The Cross-form spatial pyramid module aggregates the context information in different scales and locations to form a cost volume. Moreover, it is proved to be more effective than SPP and ASPP in ill-posed regions. The Multi-Scale 3D feature matching and fusion module is proved to regularize the cost volume using two parallel 3D deconvolution structure with two different receptive fields. Our proposed method has been evaluated on the Scene Flow and KITTI datasets. It achieves state-of-the-art performance on the KITTI 2012 and 2015 benchmarks.
MSDC-Net: Multi-Scale Dense and Contextual Networks for Automated Disparity Map for Stereo Matching
Apr 30, 2019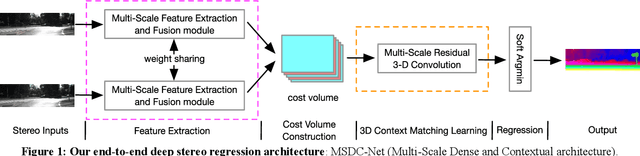

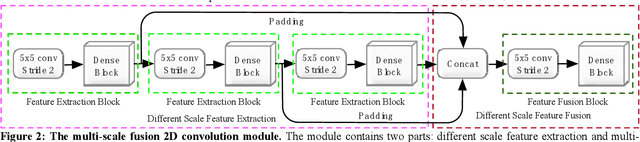
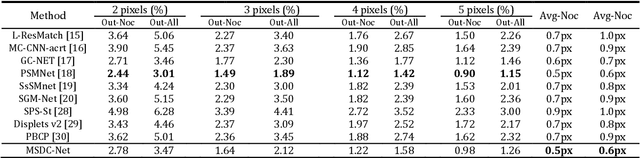
Disparity prediction from stereo images is essential to computer vision applications including autonomous driving, 3D model reconstruction, and object detection. To predict accurate disparity map, we propose a novel deep learning architecture for detectingthe disparity map from a rectified pair of stereo images, called MSDC-Net. Our MSDC-Net contains two modules: multi-scale fusion 2D convolution and multi-scale residual 3D convolution modules. The multi-scale fusion 2D convolution module exploits the potential multi-scale features, which extracts and fuses the different scale features by Dense-Net. The multi-scale residual 3D convolution module learns the different scale geometry context from the cost volume which aggregated by the multi-scale fusion 2D convolution module. Experimental results on Scene Flow and KITTI datasets demonstrate that our MSDC-Net significantly outperforms other approaches in the non-occluded region.