 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVHOI: Bridge Multi-view Condition to Complex Human-Object Interaction Video Reenactment via 3D Foundation Model
Mar 16, 2026Human-Object Interaction (HOI) video reenactment with realistic motion remains a frontier in expressive digital human creation. Existing approaches primarily handle simple image-plane motion (e.g., in-plane translations), struggling with complex non-planar manipulations like out-of-plane reorientation. In this paper, we propose MVHOI, a two-stage HOI video reenactment framework that bridges multi-view reference conditions and video foundation models via a 3D Foundation Model (3DFM). The 3DFM first produces view-consistent object priors conditioned on implicit motion dynamics across novel viewpoints. A controllable video generation model then synthesizes high-fidelity object texture by incorporating multi-view reference images, ensuring appearance consistency via a reasonable retrieval mechanism. By enabling these two stages to mutually reinforce one another during the inference phase, our framework shows superior performance in generating long-duration HOI videos with intricate object manipulations. Extensive experiments show substantial improvements over prior approaches, especially for HOI with complex 3D object manipulations.
RnG: A Unified Transformer for Complete 3D Modeling from Partial Observations
Mar 01, 2026Human perceive the 3D world through 2D observations from limited viewpoints. While recent feed-forward generalizable 3D reconstruction models excel at recovering 3D structures from sparse images, their representations are often confined to observed regions, leaving unseen geometry un-modeled. This raises a key, fundamental challenge: Can we infer a complete 3D structure from partial 2D observations? We present RnG (Reconstruction and Generation), a novel feed-forward Transformer that unifies these two tasks by predicting an implicit, complete 3D representation. At the core of RnG, we propose a reconstruction-guided causal attention mechanism that separates reconstruction and generation at the attention level, and treats the KV-cache as an implicit 3D representation. Then, arbitrary poses can efficiently query this cache to render high-fidelity, novel-view RGBD outputs. As a result, RnG not only accurately reconstructs visible geometry but also generates plausible, coherent unseen geometry and appearance. Our method achieves state-of-the-art performance in both generalizable 3D reconstruction and novel view generation, while operating efficiently enough for real-time interactive applications. Project page: https://npucvr.github.io/RnG
iDiT-HOI: Inpainting-based Hand Object Interaction Reenactment via Video Diffusion Transformer
Jun 15, 2025Digital human video generation is gaining traction in fields like education and e-commerce, driven by advancements in head-body animation and lip-syncing technologies. However, realistic Hand-Object Interaction (HOI) - the complex dynamics between human hands and objects - continues to pose challenges. Generating natural and believable HOI reenactments is difficult due to issues such as occlusion between hands and objects, variations in object shapes and orientations, and the necessity for precise physical interactions, and importantly, the ability to generalize to unseen humans and objects. This paper presents a novel framework iDiT-HOI that enables in-the-wild HOI reenactment generation. Specifically, we propose a unified inpainting-based token process method, called Inp-TPU, with a two-stage video diffusion transformer (DiT) model. The first stage generates a key frame by inserting the designated object into the hand region, providing a reference for subsequent frames. The second stage ensures temporal coherence and fluidity in hand-object interactions. The key contribution of our method is to reuse the pretrained model's context perception capabilities without introducing additional parameters, enabling strong generalization to unseen objects and scenarios, and our proposed paradigm naturally supports long video generation. Comprehensive evaluations demonstrate that our approach outperforms existing methods, particularly in challenging real-world scenes, offering enhanced realism and more seamless hand-object interactions.
CMD: Constraining Multimodal Distribution for Domain Adaptation in Stereo Matching
Apr 30, 2025Recently, learning-based stereo matching methods have achieved great improvement in public benchmarks, where soft argmin and smooth L1 loss play a core contribution to their success. However, in unsupervised domain adaptation scenarios, we observe that these two operations often yield multimodal disparity probability distributions in target domains, resulting in degraded generalization. In this paper, we propose a novel approach, Constrain Multi-modal Distribution (CMD), to address this issue. Specifically, we introduce \textit{uncertainty-regularized minimization} and \textit{anisotropic soft argmin} to encourage the network to produce predominantly unimodal disparity distributions in the target domain, thereby improving prediction accuracy. Experimentally, we apply the proposed method to multiple representative stereo-matching networks and conduct domain adaptation from synthetic data to unlabeled real-world scenes. Results consistently demonstrate improved generalization in both top-performing and domain-adaptable stereo-matching models. The code for CMD will be available at: \href{https://github.com/gallenszl/CMD}{https://github.com/gallenszl/CMD}.
Splatter-360: Generalizable 360$^{\circ}$ Gaussian Splatting for Wide-baseline Panoramic Images
Dec 09, 2024Wide-baseline panoramic images are frequently used in applications like VR and simulations to minimize capturing labor costs and storage needs. However, synthesizing novel views from these panoramic images in real time remains a significant challenge, especially due to panoramic imagery's high resolution and inherent distortions. Although existing 3D Gaussian splatting (3DGS) methods can produce photo-realistic views under narrow baselines, they often overfit the training views when dealing with wide-baseline panoramic images due to the difficulty in learning precise geometry from sparse 360$^{\circ}$ views. This paper presents \textit{Splatter-360}, a novel end-to-end generalizable 3DGS framework designed to handle wide-baseline panoramic images. Unlike previous approaches, \textit{Splatter-360} performs multi-view matching directly in the spherical domain by constructing a spherical cost volume through a spherical sweep algorithm, enhancing the network's depth perception and geometry estimation. Additionally, we introduce a 3D-aware bi-projection encoder to mitigate the distortions inherent in panoramic images and integrate cross-view attention to improve feature interactions across multiple viewpoints. This enables robust 3D-aware feature representations and real-time rendering capabilities. Experimental results on the HM3D~\cite{hm3d} and Replica~\cite{replica} demonstrate that \textit{Splatter-360} significantly outperforms state-of-the-art NeRF and 3DGS methods (e.g., PanoGRF, MVSplat, DepthSplat, and HiSplat) in both synthesis quality and generalization performance for wide-baseline panoramic images. Code and trained models are available at \url{https://3d-aigc.github.io/Splatter-360/}.
Digging into Depth Priors for Outdoor Neural Radiance Fields
Aug 08, 2023Neural Radiance Fields (NeRF) have demonstrated impressive performance in vision and graphics tasks, such as novel view synthesis and immersive reality. However, the shape-radiance ambiguity of radiance fields remains a challenge, especially in the sparse viewpoints setting. Recent work resorts to integrating depth priors into outdoor NeRF training to alleviate the issue. However, the criteria for selecting depth priors and the relative merits of different priors have not been thoroughly investigated. Moreover, the relative merits of selecting different approaches to use the depth priors is also an unexplored problem. In this paper, we provide a comprehensive study and evaluation of employing depth priors to outdoor neural radiance fields, covering common depth sensing technologies and most application ways. Specifically, we conduct extensive experiments with two representative NeRF methods equipped with four commonly-used depth priors and different depth usages on two widely used outdoor datasets. Our experimental results reveal several interesting findings that can potentially benefit practitioners and researchers in training their NeRF models with depth priors. Project Page: https://cwchenwang.github.io/outdoor-nerf-depth
MapNeRF: Incorporating Map Priors into Neural Radiance Fields for Driving View Simulation
Aug 06, 2023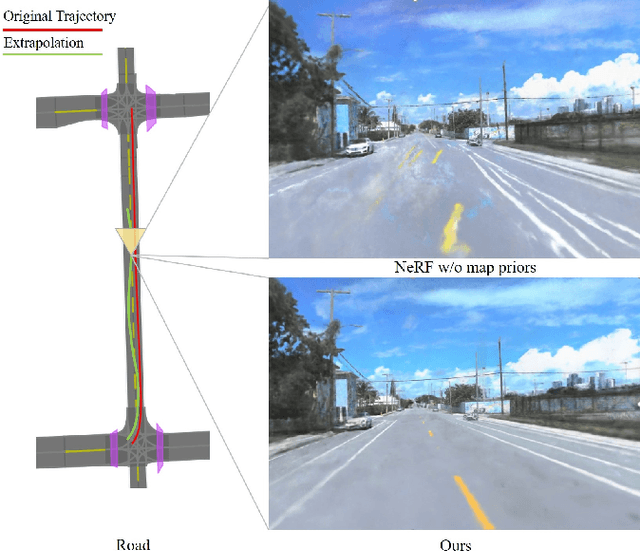
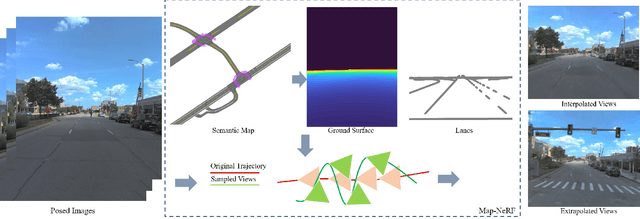
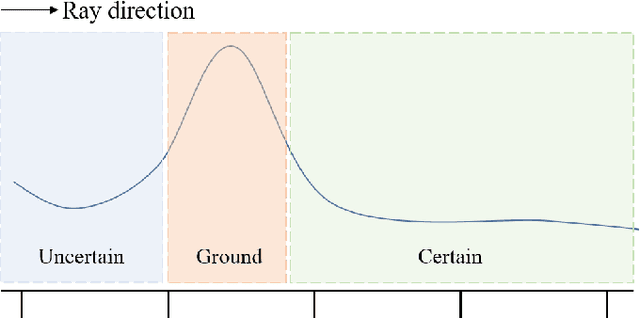

Simulating camera sensors is a crucial task in autonomous driving. Although neural radiance fields are exceptional at synthesizing photorealistic views in driving simulations, they still fail to generate extrapolated views. This paper proposes to incorporate map priors into neural radiance fields to synthesize out-of-trajectory driving views with semantic road consistency. The key insight is that map information can be utilized as a prior to guiding the training of the radiance fields with uncertainty. Specifically, we utilize the coarse ground surface as uncertain information to supervise the density field and warp depth with uncertainty from unknown camera poses to ensure multi-view consistency. Experimental results demonstrate that our approach can produce semantic consistency in deviated views for vehicle camera simulation. The supplementary video can be viewed at https://youtu.be/jEQWr-Rfh3A.
Digging Into Uncertainty-based Pseudo-label for Robust Stereo Matching
Jul 31, 2023
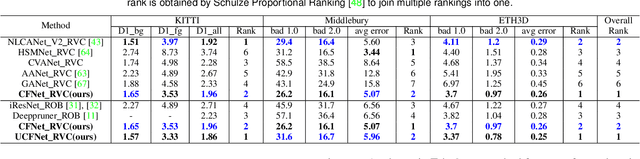

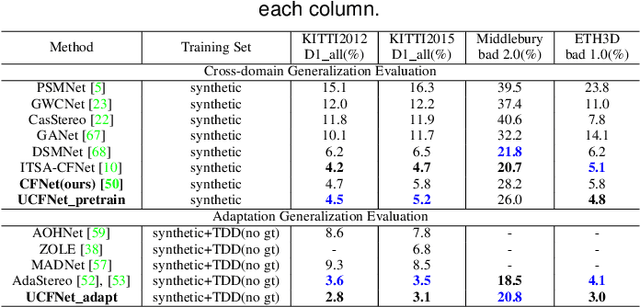
Due to the domain differences and unbalanced disparity distribution across multiple datasets, current stereo matching approaches are commonly limited to a specific dataset and generalize poorly to others. Such domain shift issue is usually addressed by substantial adaptation on costly target-domain ground-truth data, which cannot be easily obtained in practical settings. In this paper, we propose to dig into uncertainty estimation for robust stereo matching. Specifically, to balance the disparity distribution, we employ a pixel-level uncertainty estimation to adaptively adjust the next stage disparity searching space, in this way driving the network progressively prune out the space of unlikely correspondences. Then, to solve the limited ground truth data, an uncertainty-based pseudo-label is proposed to adapt the pre-trained model to the new domain, where pixel-level and area-level uncertainty estimation are proposed to filter out the high-uncertainty pixels of predicted disparity maps and generate sparse while reliable pseudo-labels to align the domain gap. Experimentally, our method shows strong cross-domain, adapt, and joint generalization and obtains \textbf{1st} place on the stereo task of Robust Vision Challenge 2020. Additionally, our uncertainty-based pseudo-labels can be extended to train monocular depth estimation networks in an unsupervised way and even achieves comparable performance with the supervised methods. The code will be available at https://github.com/gallenszl/UCFNet.
NeuS-PIR: Learning Relightable Neural Surface using Pre-Integrated Rendering
Jun 13, 2023Recent advances in neural implicit fields enables rapidly reconstructing 3D geometry from multi-view images. Beyond that, recovering physical properties such as material and illumination is essential for enabling more applications. This paper presents a new method that effectively learns relightable neural surface using pre-intergrated rendering, which simultaneously learns geometry, material and illumination within the neural implicit field. The key insight of our work is that these properties are closely related to each other, and optimizing them in a collaborative manner would lead to consistent improvements. Specifically, we propose NeuS-PIR, a method that factorizes the radiance field into a spatially varying material field and a differentiable environment cubemap, and jointly learns it with geometry represented by neural surface. Our experiments demonstrate that the proposed method outperforms the state-of-the-art method in both synthetic and real datasets.
CFNet: Cascade and Fused Cost Volume for Robust Stereo Matching
Apr 09, 2021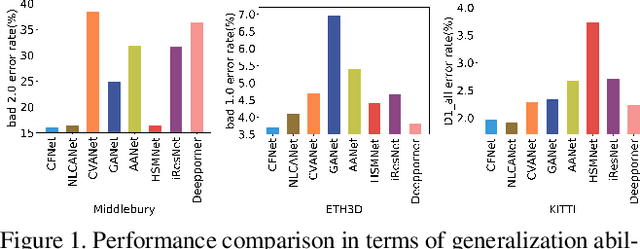
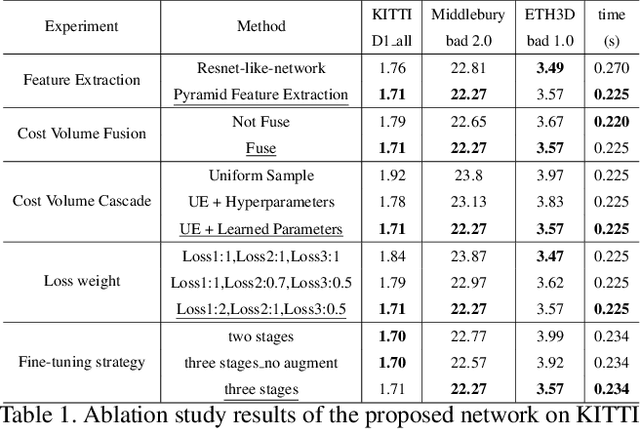
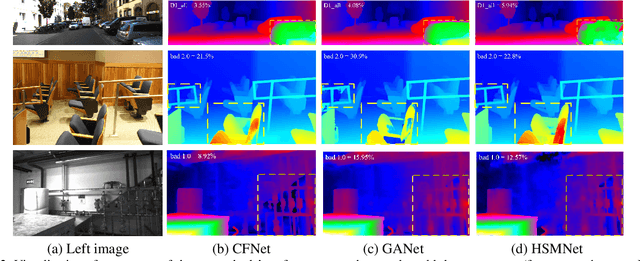
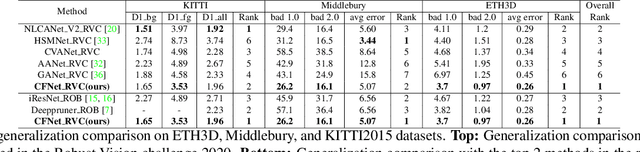
Recently, the ever-increasing capacity of large-scale annotated datasets has led to profound progress in stereo matching. However, most of these successes are limited to a specific dataset and cannot generalize well to other datasets. The main difficulties lie in the large domain differences and unbalanced disparity distribution across a variety of datasets, which greatly limit the real-world applicability of current deep stereo matching models. In this paper, we propose CFNet, a Cascade and Fused cost volume based network to improve the robustness of the stereo matching network. First, we propose a fused cost volume representation to deal with the large domain difference. By fusing multiple low-resolution dense cost volumes to enlarge the receptive field, we can extract robust structural representations for initial disparity estimation. Second, we propose a cascade cost volume representation to alleviate the unbalanced disparity distribution. Specifically, we employ a variance-based uncertainty estimation to adaptively adjust the next stage disparity search space, in this way driving the network progressively prune out the space of unlikely correspondences. By iteratively narrowing down the disparity search space and improving the cost volume resolution, the disparity estimation is gradually refined in a coarse-to-fine manner. When trained on the same training images and evaluated on KITTI, ETH3D, and Middlebury datasets with the fixed model parameters and hyperparameters, our proposed method achieves the state-of-the-art overall performance and obtains the 1st place on the stereo task of Robust Vision Challenge 2020. The code will be available at https://github.com/gallenszl/CFNet.