 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeONE-SHOT: Compositional Human-Environment Video Synthesis via Spatial-Decoupled Motion Injection and Hybrid Context Integration
Apr 01, 2026Recent advances in Video Foundation Models (VFMs) have revolutionized human-centric video synthesis, yet fine-grained and independent editing of subjects and scenes remains a critical challenge. Recent attempts to incorporate richer environment control through rigid 3D geometric compositions often encounter a stark trade-off between precise control and generative flexibility. Furthermore, the heavy 3D pre-processing still limits practical scalability. In this paper, we propose ONE-SHOT, a parameter-efficient framework for compositional human-environment video generation. Our key insight is to factorize the generative process into disentangled signals. Specifically, we introduce a canonical-space injection mechanism that decouples human dynamics from environmental cues via cross-attention. We also propose Dynamic-Grounded-RoPE, a novel positional embedding strategy that establishes spatial correspondences between disparate spatial domains without any heuristic 3D alignments. To support long-horizon synthesis, we introduce a Hybrid Context Integration mechanism to maintain subject and scene consistency across minute-level generations. Experiments demonstrate that our method significantly outperforms state-of-the-art methods, offering superior structural control and creative diversity for video synthesis. Our project has been available on: https://martayang.github.io/ONE-SHOT/.
InterDyad: Interactive Dyadic Speech-to-Video Generation by Querying Intermediate Visual Guidance
Mar 24, 2026Despite progress in speech-to-video synthesis, existing methods often struggle to capture cross-individual dependencies and provide fine-grained control over reactive behaviors in dyadic settings. To address these challenges, we propose InterDyad, a framework that enables naturalistic interactive dynamics synthesis via querying structural motion guidance. Specifically, we first design an Interactivity Injector that achieves video reenactment based on identity-agnostic motion priors extracted from reference videos. Building upon this, we introduce a MetaQuery-based modality alignment mechanism to bridge the gap between conversational audio and these motion priors. By leveraging a Multimodal Large Language Model (MLLM), our framework is able to distill linguistic intent from audio to dictate the precise timing and appropriateness of reactions. To further improve lip-sync quality under extreme head poses, we propose Role-aware Dyadic Gaussian Guidance (RoDG) for enhanced lip-synchronization and spatial consistency. Finally, we introduce a dedicated evaluation suite with novelly designed metrics to quantify dyadic interaction. Comprehensive experiments demonstrate that InterDyad significantly outperforms state-of-the-art methods in producing natural and contextually grounded two-person interactions. Please refer to our project page for demo videos: https://interdyad.github.io/.
MVHOI: Bridge Multi-view Condition to Complex Human-Object Interaction Video Reenactment via 3D Foundation Model
Mar 16, 2026Human-Object Interaction (HOI) video reenactment with realistic motion remains a frontier in expressive digital human creation. Existing approaches primarily handle simple image-plane motion (e.g., in-plane translations), struggling with complex non-planar manipulations like out-of-plane reorientation. In this paper, we propose MVHOI, a two-stage HOI video reenactment framework that bridges multi-view reference conditions and video foundation models via a 3D Foundation Model (3DFM). The 3DFM first produces view-consistent object priors conditioned on implicit motion dynamics across novel viewpoints. A controllable video generation model then synthesizes high-fidelity object texture by incorporating multi-view reference images, ensuring appearance consistency via a reasonable retrieval mechanism. By enabling these two stages to mutually reinforce one another during the inference phase, our framework shows superior performance in generating long-duration HOI videos with intricate object manipulations. Extensive experiments show substantial improvements over prior approaches, especially for HOI with complex 3D object manipulations.
DISPLAY: Directable Human-Object Interaction Video Generation via Sparse Motion Guidance and Multi-Task Auxiliary
Mar 10, 2026Human-centric video generation has advanced rapidly, yet existing methods struggle to produce controllable and physically consistent Human-Object Interaction (HOI) videos. Existing works rely on dense control signals, template videos, or carefully crafted text prompts, which limit flexibility and generalization to novel objects. We introduce a framework, namely DISPLAY, guided by Sparse Motion Guidance, composed only of wrist joint coordinates and a shape-agnostic object bounding box. This lightweight guidance alleviates the imbalance between human and object representations and enables intuitive user control. To enhance fidelity under such sparse conditions, we propose an Object-Stressed Attention mechanism that improves object robustness. To address the scarcity of high-quality HOI data, we further develop a Multi-Task Auxiliary Training strategy with a dedicated data curation pipeline, allowing the model to benefit from both reliable HOI samples and auxiliary tasks. Comprehensive experiments show that our method achieves high-fidelity, controllable HOI generation across diverse tasks. The project page can be found at \href{https://mumuwei.github.io/DISPLAY/}.
iDiT-HOI: Inpainting-based Hand Object Interaction Reenactment via Video Diffusion Transformer
Jun 15, 2025Digital human video generation is gaining traction in fields like education and e-commerce, driven by advancements in head-body animation and lip-syncing technologies. However, realistic Hand-Object Interaction (HOI) - the complex dynamics between human hands and objects - continues to pose challenges. Generating natural and believable HOI reenactments is difficult due to issues such as occlusion between hands and objects, variations in object shapes and orientations, and the necessity for precise physical interactions, and importantly, the ability to generalize to unseen humans and objects. This paper presents a novel framework iDiT-HOI that enables in-the-wild HOI reenactment generation. Specifically, we propose a unified inpainting-based token process method, called Inp-TPU, with a two-stage video diffusion transformer (DiT) model. The first stage generates a key frame by inserting the designated object into the hand region, providing a reference for subsequent frames. The second stage ensures temporal coherence and fluidity in hand-object interactions. The key contribution of our method is to reuse the pretrained model's context perception capabilities without introducing additional parameters, enabling strong generalization to unseen objects and scenarios, and our proposed paradigm naturally supports long video generation. Comprehensive evaluations demonstrate that our approach outperforms existing methods, particularly in challenging real-world scenes, offering enhanced realism and more seamless hand-object interactions.
AudCast: Audio-Driven Human Video Generation by Cascaded Diffusion Transformers
Mar 25, 2025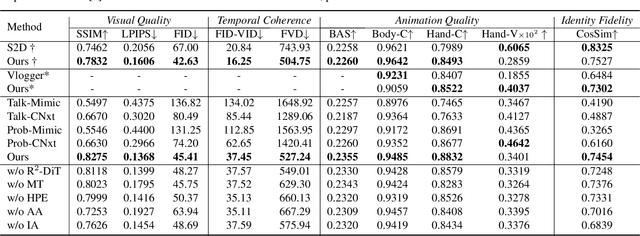
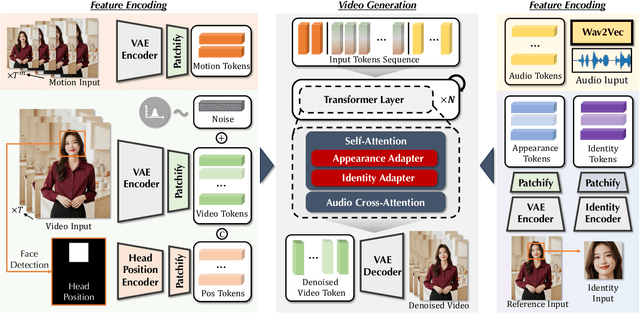
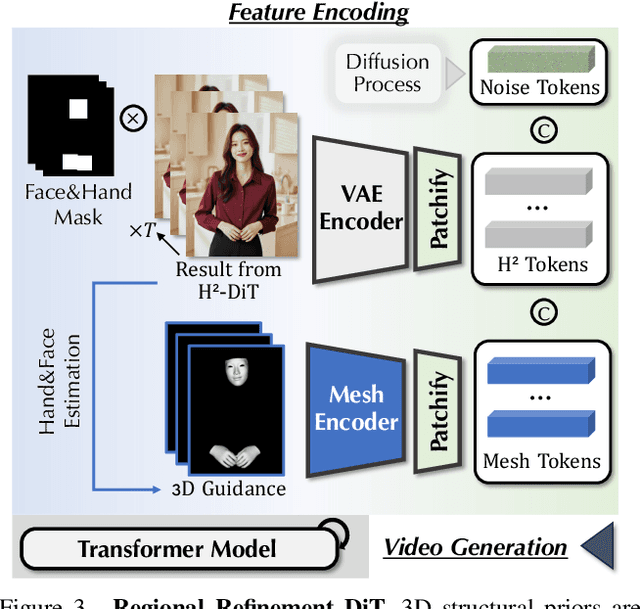

Despite the recent progress of audio-driven video generation, existing methods mostly focus on driving facial movements, leading to non-coherent head and body dynamics. Moving forward, it is desirable yet challenging to generate holistic human videos with both accurate lip-sync and delicate co-speech gestures w.r.t. given audio. In this work, we propose AudCast, a generalized audio-driven human video generation framework adopting a cascade Diffusion-Transformers (DiTs) paradigm, which synthesizes holistic human videos based on a reference image and a given audio. 1) Firstly, an audio-conditioned Holistic Human DiT architecture is proposed to directly drive the movements of any human body with vivid gesture dynamics. 2) Then to enhance hand and face details that are well-knownly difficult to handle, a Regional Refinement DiT leverages regional 3D fitting as the bridge to reform the signals, producing the final results. Extensive experiments demonstrate that our framework generates high-fidelity audio-driven holistic human videos with temporal coherence and fine facial and hand details. Resources can be found at https://guanjz20.github.io/projects/AudCast.
Cosh-DiT: Co-Speech Gesture Video Synthesis via Hybrid Audio-Visual Diffusion Transformers
Mar 13, 2025Co-speech gesture video synthesis is a challenging task that requires both probabilistic modeling of human gestures and the synthesis of realistic images that align with the rhythmic nuances of speech. To address these challenges, we propose Cosh-DiT, a Co-speech gesture video system with hybrid Diffusion Transformers that perform audio-to-motion and motion-to-video synthesis using discrete and continuous diffusion modeling, respectively. First, we introduce an audio Diffusion Transformer (Cosh-DiT-A) to synthesize expressive gesture dynamics synchronized with speech rhythms. To capture upper body, facial, and hand movement priors, we employ vector-quantized variational autoencoders (VQ-VAEs) to jointly learn their dependencies within a discrete latent space. Then, for realistic video synthesis conditioned on the generated speech-driven motion, we design a visual Diffusion Transformer (Cosh-DiT-V) that effectively integrates spatial and temporal contexts. Extensive experiments demonstrate that our framework consistently generates lifelike videos with expressive facial expressions and natural, smooth gestures that align seamlessly with speech.
TALK-Act: Enhance Textural-Awareness for 2D Speaking Avatar Reenactment with Diffusion Model
Oct 14, 2024

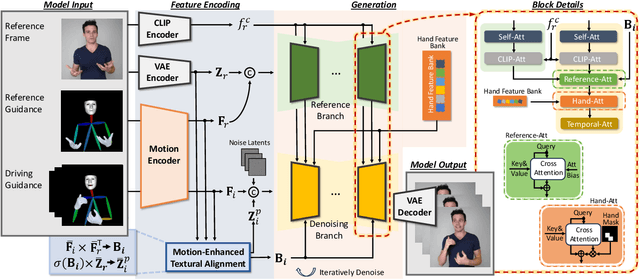

Recently, 2D speaking avatars have increasingly participated in everyday scenarios due to the fast development of facial animation techniques. However, most existing works neglect the explicit control of human bodies. In this paper, we propose to drive not only the faces but also the torso and gesture movements of a speaking figure. Inspired by recent advances in diffusion models, we propose the Motion-Enhanced Textural-Aware ModeLing for SpeaKing Avatar Reenactment (TALK-Act) framework, which enables high-fidelity avatar reenactment from only short footage of monocular video. Our key idea is to enhance the textural awareness with explicit motion guidance in diffusion modeling. Specifically, we carefully construct 2D and 3D structural information as intermediate guidance. While recent diffusion models adopt a side network for control information injection, they fail to synthesize temporally stable results even with person-specific fine-tuning. We propose a Motion-Enhanced Textural Alignment module to enhance the bond between driving and target signals. Moreover, we build a Memory-based Hand-Recovering module to help with the difficulties in hand-shape preserving. After pre-training, our model can achieve high-fidelity 2D avatar reenactment with only 30 seconds of person-specific data. Extensive experiments demonstrate the effectiveness and superiority of our proposed framework. Resources can be found at https://guanjz20.github.io/projects/TALK-Act.
ReSyncer: Rewiring Style-based Generator for Unified Audio-Visually Synced Facial Performer
Aug 06, 2024



Lip-syncing videos with given audio is the foundation for various applications including the creation of virtual presenters or performers. While recent studies explore high-fidelity lip-sync with different techniques, their task-orientated models either require long-term videos for clip-specific training or retain visible artifacts. In this paper, we propose a unified and effective framework ReSyncer, that synchronizes generalized audio-visual facial information. The key design is revisiting and rewiring the Style-based generator to efficiently adopt 3D facial dynamics predicted by a principled style-injected Transformer. By simply re-configuring the information insertion mechanisms within the noise and style space, our framework fuses motion and appearance with unified training. Extensive experiments demonstrate that ReSyncer not only produces high-fidelity lip-synced videos according to audio, but also supports multiple appealing properties that are suitable for creating virtual presenters and performers, including fast personalized fine-tuning, video-driven lip-syncing, the transfer of speaking styles, and even face swapping. Resources can be found at https://guanjz20.github.io/projects/ReSyncer.
AVI-Talking: Learning Audio-Visual Instructions for Expressive 3D Talking Face Generation
Feb 25, 2024While considerable progress has been made in achieving accurate lip synchronization for 3D speech-driven talking face generation, the task of incorporating expressive facial detail synthesis aligned with the speaker's speaking status remains challenging. Our goal is to directly leverage the inherent style information conveyed by human speech for generating an expressive talking face that aligns with the speaking status. In this paper, we propose AVI-Talking, an Audio-Visual Instruction system for expressive Talking face generation. This system harnesses the robust contextual reasoning and hallucination capability offered by Large Language Models (LLMs) to instruct the realistic synthesis of 3D talking faces. Instead of directly learning facial movements from human speech, our two-stage strategy involves the LLMs first comprehending audio information and generating instructions implying expressive facial details seamlessly corresponding to the speech. Subsequently, a diffusion-based generative network executes these instructions. This two-stage process, coupled with the incorporation of LLMs, enhances model interpretability and provides users with flexibility to comprehend instructions and specify desired operations or modifications. Extensive experiments showcase the effectiveness of our approach in producing vivid talking faces with expressive facial movements and consistent emotional status.