 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoleyDirector: Fine-Grained Temporal Steering for Video-to-Audio Generation via Structured Scripts
Mar 20, 2026Recent Video-to-Audio (V2A) methods have achieved remarkable progress, enabling the synthesis of realistic, high-quality audio. However, they struggle with fine-grained temporal control in multi-event scenarios or when visual cues are insufficient, such as small regions, off-screen sounds, or occluded or partially visible objects. In this paper, we propose FoleyDirector, a framework that, for the first time, enables precise temporal guidance in DiT-based V2A generation while preserving the base model's audio quality and allowing seamless switching between V2A generation and temporally controlled synthesis. FoleyDirector introduces Structured Temporal Scripts (STS), a set of captions corresponding to short temporal segments, to provide richer temporal information. These features are integrated via the Script-Guided Temporal Fusion Module, which employs Temporal Script Attention to fuse STS features coherently. To handle complex multi-event scenarios, we further propose Bi-Frame Sound Synthesis, enabling parallel in-frame and out-of-frame audio generation and improving controllability. To support training and evaluation, we construct the DirectorSound dataset and introduce VGGSoundDirector and DirectorBench. Experiments demonstrate that FoleyDirector substantially enhances temporal controllability while maintaining high audio fidelity, empowering users to act as Foley directors and advancing V2A toward more expressive and controllable generation.
VCoME: Verbal Video Composition with Multimodal Editing Effects
Jul 05, 2024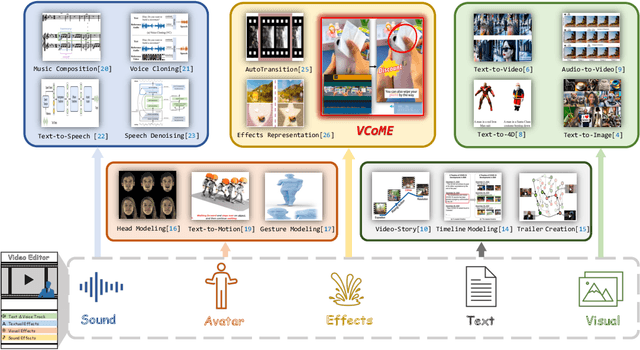
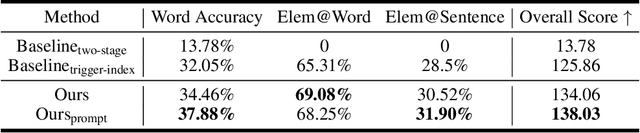
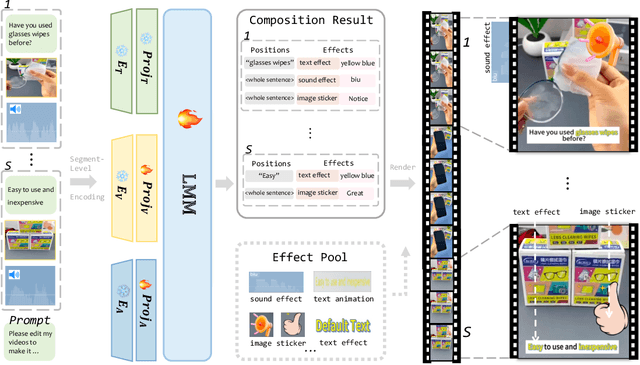

Verbal videos, featuring voice-overs or text overlays, provide valuable content but present significant challenges in composition, especially when incorporating editing effects to enhance clarity and visual appeal. In this paper, we introduce the novel task of verbal video composition with editing effects. This task aims to generate coherent and visually appealing verbal videos by integrating multimodal editing effects across textual, visual, and audio categories. To achieve this, we curate a large-scale dataset of video effects compositions from publicly available sources. We then formulate this task as a generative problem, involving the identification of appropriate positions in the verbal content and the recommendation of editing effects for these positions. To address this task, we propose VCoME, a general framework that employs a large multimodal model to generate editing effects for video composition. Specifically, VCoME takes in the multimodal video context and autoregressively outputs where to apply effects within the verbal content and which effects are most appropriate for each position. VCoME also supports prompt-based control of composition density and style, providing substantial flexibility for diverse applications. Through extensive quantitative and qualitative evaluations, we clearly demonstrate the effectiveness of VCoME. A comprehensive user study shows that our method produces videos of professional quality while being 85$\times$ more efficient than professional editors.
Vision Transformer with Attention Map Hallucination and FFN Compaction
Jun 19, 2023Vision Transformer(ViT) is now dominating many vision tasks. The drawback of quadratic complexity of its token-wise multi-head self-attention (MHSA), is extensively addressed via either token sparsification or dimension reduction (in spatial or channel). However, the therein redundancy of MHSA is usually overlooked and so is the feed-forward network (FFN). To this end, we propose attention map hallucination and FFN compaction to fill in the blank. Specifically, we observe similar attention maps exist in vanilla ViT and propose to hallucinate half of the attention maps from the rest with much cheaper operations, which is called hallucinated-MHSA (hMHSA). As for FFN, we factorize its hidden-to-output projection matrix and leverage the re-parameterization technique to strengthen its capability, making it compact-FFN (cFFN). With our proposed modules, a 10$\%$-20$\%$ reduction of floating point operations (FLOPs) and parameters (Params) is achieved for various ViT-based backbones, including straight (DeiT), hybrid (NextViT) and hierarchical (PVT) structures, meanwhile, the performances are quite competitive.
StyleSync: High-Fidelity Generalized and Personalized Lip Sync in Style-based Generator
May 09, 2023



Despite recent advances in syncing lip movements with any audio waves, current methods still struggle to balance generation quality and the model's generalization ability. Previous studies either require long-term data for training or produce a similar movement pattern on all subjects with low quality. In this paper, we propose StyleSync, an effective framework that enables high-fidelity lip synchronization. We identify that a style-based generator would sufficiently enable such a charming property on both one-shot and few-shot scenarios. Specifically, we design a mask-guided spatial information encoding module that preserves the details of the given face. The mouth shapes are accurately modified by audio through modulated convolutions. Moreover, our design also enables personalized lip-sync by introducing style space and generator refinement on only limited frames. Thus the identity and talking style of a target person could be accurately preserved. Extensive experiments demonstrate the effectiveness of our method in producing high-fidelity results on a variety of scenes. Resources can be found at https://hangz-nju-cuhk.github.io/projects/StyleSync.
Master: Meta Style Transformer for Controllable Zero-Shot and Few-Shot Artistic Style Transfer
Apr 24, 2023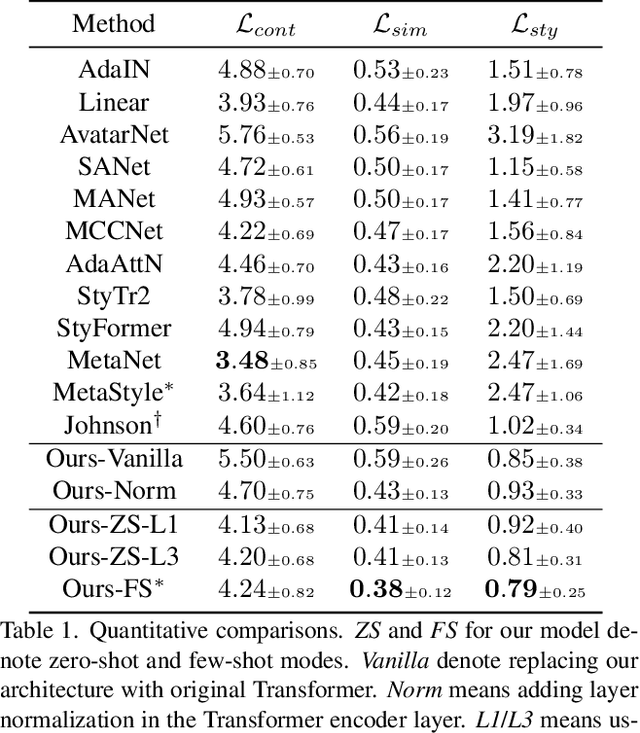
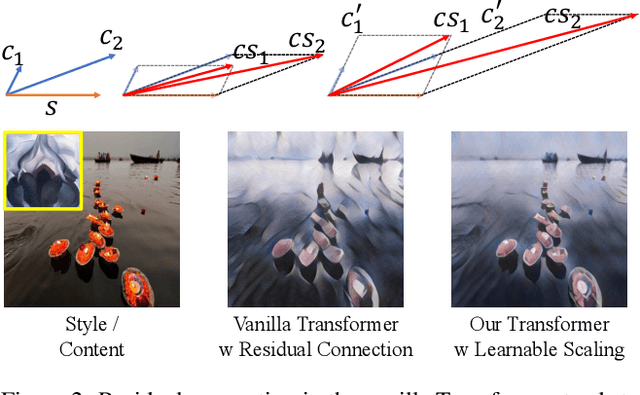
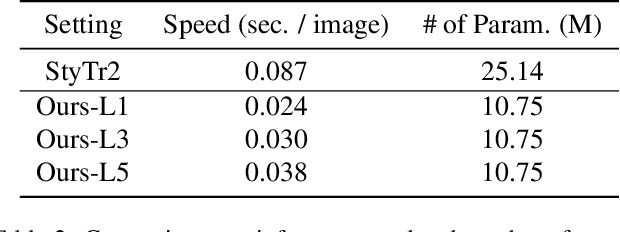
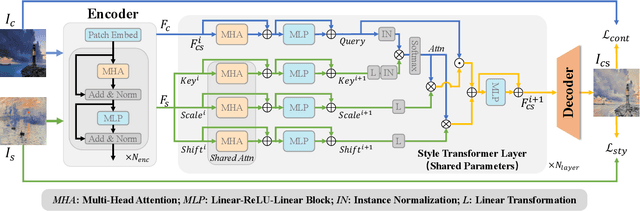
Transformer-based models achieve favorable performance in artistic style transfer recently thanks to its global receptive field and powerful multi-head/layer attention operations. Nevertheless, the over-paramerized multi-layer structure increases parameters significantly and thus presents a heavy burden for training. Moreover, for the task of style transfer, vanilla Transformer that fuses content and style features by residual connections is prone to content-wise distortion. In this paper, we devise a novel Transformer model termed as \emph{Master} specifically for style transfer. On the one hand, in the proposed model, different Transformer layers share a common group of parameters, which (1) reduces the total number of parameters, (2) leads to more robust training convergence, and (3) is readily to control the degree of stylization via tuning the number of stacked layers freely during inference. On the other hand, different from the vanilla version, we adopt a learnable scaling operation on content features before content-style feature interaction, which better preserves the original similarity between a pair of content features while ensuring the stylization quality. We also propose a novel meta learning scheme for the proposed model so that it can not only work in the typical setting of arbitrary style transfer, but also adaptable to the few-shot setting, by only fine-tuning the Transformer encoder layer in the few-shot stage for one specific style. Text-guided few-shot style transfer is firstly achieved with the proposed framework. Extensive experiments demonstrate the superiority of Master under both zero-shot and few-shot style transfer settings.
DeltaEdit: Exploring Text-free Training for Text-Driven Image Manipulation
Mar 11, 2023
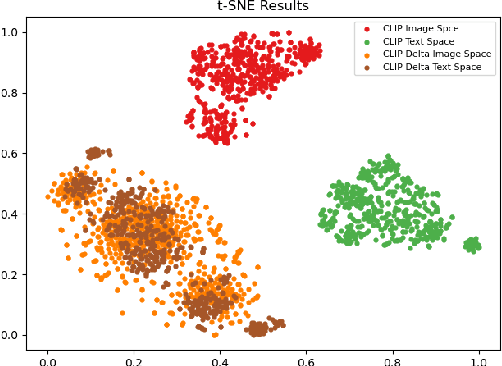

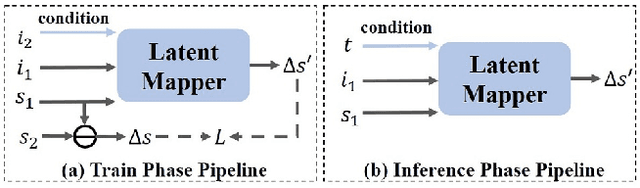
Text-driven image manipulation remains challenging in training or inference flexibility. Conditional generative models depend heavily on expensive annotated training data. Meanwhile, recent frameworks, which leverage pre-trained vision-language models, are limited by either per text-prompt optimization or inference-time hyper-parameters tuning. In this work, we propose a novel framework named \textit{DeltaEdit} to address these problems. Our key idea is to investigate and identify a space, namely delta image and text space that has well-aligned distribution between CLIP visual feature differences of two images and CLIP textual embedding differences of source and target texts. Based on the CLIP delta space, the DeltaEdit network is designed to map the CLIP visual features differences to the editing directions of StyleGAN at training phase. Then, in inference phase, DeltaEdit predicts the StyleGAN's editing directions from the differences of the CLIP textual features. In this way, DeltaEdit is trained in a text-free manner. Once trained, it can well generalize to various text prompts for zero-shot inference without bells and whistles. Code is available at https://github.com/Yueming6568/DeltaEdit.
LMR: A Large-Scale Multi-Reference Dataset for Reference-based Super-Resolution
Mar 09, 2023It is widely agreed that reference-based super-resolution (RefSR) achieves superior results by referring to similar high quality images, compared to single image super-resolution (SISR). Intuitively, the more references, the better performance. However, previous RefSR methods have all focused on single-reference image training, while multiple reference images are often available in testing or practical applications. The root cause of such training-testing mismatch is the absence of publicly available multi-reference SR training datasets, which greatly hinders research efforts on multi-reference super-resolution. To this end, we construct a large-scale, multi-reference super-resolution dataset, named LMR. It contains 112,142 groups of 300x300 training images, which is 10x of the existing largest RefSR dataset. The image size is also much larger. More importantly, each group is equipped with 5 reference images with different similarity levels. Furthermore, we propose a new baseline method for multi-reference super-resolution: MRefSR, including a Multi-Reference Attention Module (MAM) for feature fusion of an arbitrary number of reference images, and a Spatial Aware Filtering Module (SAFM) for the fused feature selection. The proposed MRefSR achieves significant improvements over state-of-the-art approaches on both quantitative and qualitative evaluations. Our code and data would be made available soon.
Make Your Brief Stroke Real and Stereoscopic: 3D-Aware Simplified Sketch to Portrait Generation
Feb 14, 2023



Creating the photo-realistic version of people sketched portraits is useful to various entertainment purposes. Existing studies only generate portraits in the 2D plane with fixed views, making the results less vivid. In this paper, we present Stereoscopic Simplified Sketch-to-Portrait (SSSP), which explores the possibility of creating Stereoscopic 3D-aware portraits from simple contour sketches by involving 3D generative models. Our key insight is to design sketch-aware constraints that can fully exploit the prior knowledge of a tri-plane-based 3D-aware generative model. Specifically, our designed region-aware volume rendering strategy and global consistency constraint further enhance detail correspondences during sketch encoding. Moreover, in order to facilitate the usage of layman users, we propose a Contour-to-Sketch module with vector quantized representations, so that easily drawn contours can directly guide the generation of 3D portraits. Extensive comparisons show that our method generates high-quality results that match the sketch. Our usability study verifies that our system is greatly preferred by user.
AdaCM: Adaptive ColorMLP for Real-Time Universal Photo-realistic Style Transfer
Dec 03, 2022Photo-realistic style transfer aims at migrating the artistic style from an exemplar style image to a content image, producing a result image without spatial distortions or unrealistic artifacts. Impressive results have been achieved by recent deep models. However, deep neural network based methods are too expensive to run in real-time. Meanwhile, bilateral grid based methods are much faster but still contain artifacts like overexposure. In this work, we propose the \textbf{Adaptive ColorMLP (AdaCM)}, an effective and efficient framework for universal photo-realistic style transfer. First, we find the complex non-linear color mapping between input and target domain can be efficiently modeled by a small multi-layer perceptron (ColorMLP) model. Then, in \textbf{AdaCM}, we adopt a CNN encoder to adaptively predict all parameters for the ColorMLP conditioned on each input content and style image pair. Experimental results demonstrate that AdaCM can generate vivid and high-quality stylization results. Meanwhile, our AdaCM is ultrafast and can process a 4K resolution image in 6ms on one V100 GPU.
Real-time Neural Radiance Talking Portrait Synthesis via Audio-spatial Decomposition
Nov 22, 2022



While dynamic Neural Radiance Fields (NeRF) have shown success in high-fidelity 3D modeling of talking portraits, the slow training and inference speed severely obstruct their potential usage. In this paper, we propose an efficient NeRF-based framework that enables real-time synthesizing of talking portraits and faster convergence by leveraging the recent success of grid-based NeRF. Our key insight is to decompose the inherently high-dimensional talking portrait representation into three low-dimensional feature grids. Specifically, a Decomposed Audio-spatial Encoding Module models the dynamic head with a 3D spatial grid and a 2D audio grid. The torso is handled with another 2D grid in a lightweight Pseudo-3D Deformable Module. Both modules focus on efficiency under the premise of good rendering quality. Extensive experiments demonstrate that our method can generate realistic and audio-lips synchronized talking portrait videos, while also being highly efficient compared to previous methods.