 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVCoME: Verbal Video Composition with Multimodal Editing Effects
Paper and Code
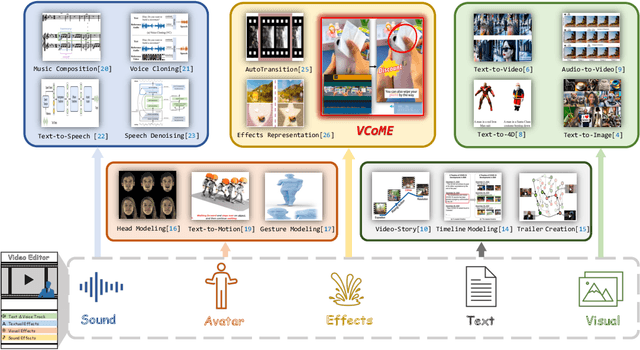
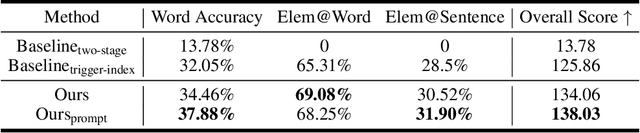
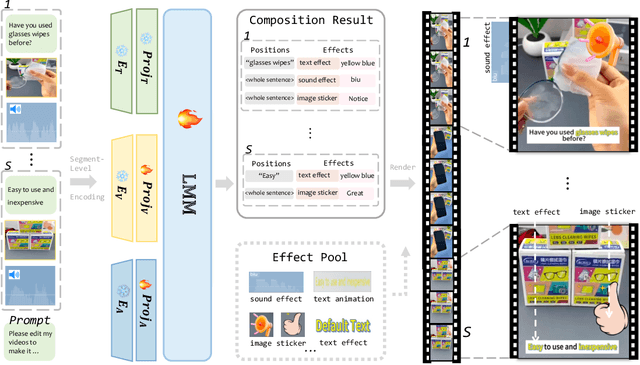

Verbal videos, featuring voice-overs or text overlays, provide valuable content but present significant challenges in composition, especially when incorporating editing effects to enhance clarity and visual appeal. In this paper, we introduce the novel task of verbal video composition with editing effects. This task aims to generate coherent and visually appealing verbal videos by integrating multimodal editing effects across textual, visual, and audio categories. To achieve this, we curate a large-scale dataset of video effects compositions from publicly available sources. We then formulate this task as a generative problem, involving the identification of appropriate positions in the verbal content and the recommendation of editing effects for these positions. To address this task, we propose VCoME, a general framework that employs a large multimodal model to generate editing effects for video composition. Specifically, VCoME takes in the multimodal video context and autoregressively outputs where to apply effects within the verbal content and which effects are most appropriate for each position. VCoME also supports prompt-based control of composition density and style, providing substantial flexibility for diverse applications. Through extensive quantitative and qualitative evaluations, we clearly demonstrate the effectiveness of VCoME. A comprehensive user study shows that our method produces videos of professional quality while being 85$\times$ more efficient than professional editors.