 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVCoME: Verbal Video Composition with Multimodal Editing Effects
Jul 05, 2024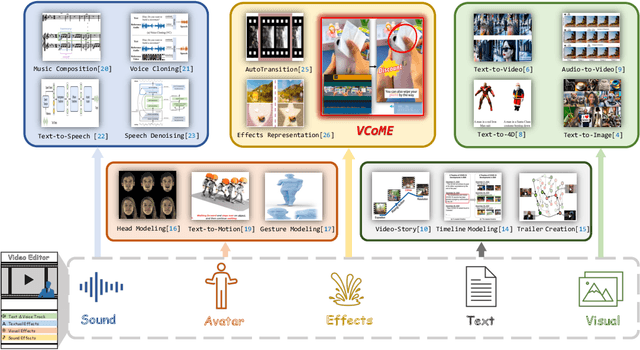
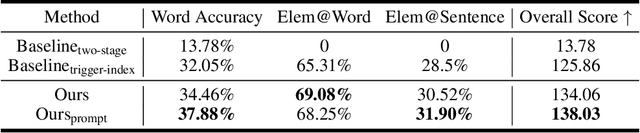
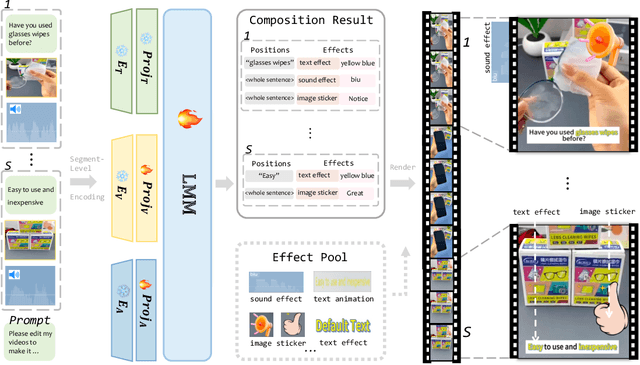

Verbal videos, featuring voice-overs or text overlays, provide valuable content but present significant challenges in composition, especially when incorporating editing effects to enhance clarity and visual appeal. In this paper, we introduce the novel task of verbal video composition with editing effects. This task aims to generate coherent and visually appealing verbal videos by integrating multimodal editing effects across textual, visual, and audio categories. To achieve this, we curate a large-scale dataset of video effects compositions from publicly available sources. We then formulate this task as a generative problem, involving the identification of appropriate positions in the verbal content and the recommendation of editing effects for these positions. To address this task, we propose VCoME, a general framework that employs a large multimodal model to generate editing effects for video composition. Specifically, VCoME takes in the multimodal video context and autoregressively outputs where to apply effects within the verbal content and which effects are most appropriate for each position. VCoME also supports prompt-based control of composition density and style, providing substantial flexibility for diverse applications. Through extensive quantitative and qualitative evaluations, we clearly demonstrate the effectiveness of VCoME. A comprehensive user study shows that our method produces videos of professional quality while being 85$\times$ more efficient than professional editors.
Relative coordinates are crucial for Ulam's "trick to the train of thought"
Mar 15, 2023Spatial signal processing algorithms often use pre-given coordinate systems to label pixel positions. These processing algorithms are thus burdened by an external reference grid, making the acquisition of relative, intrinsic features difficult. This is in contrast to animal vision and cognition: animals recognize features without an external coordinate system. We show that a coordinate system-independent algorithm for visual signal processing is not only important for animal vision, but also fundamental for concept formation. In this paper we start with a visual object deformation transfer experiment. We then formulate an algorithm that achieves deformation-invariance with relative coordinates. The paper concludes with implications for general concept formation.
Multimodal Video Adapter for Parameter Efficient Video Text Retrieval
Jan 19, 2023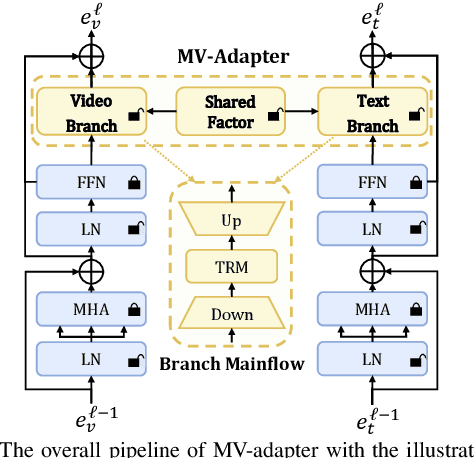



State-of-the-art video-text retrieval (VTR) methods usually fully fine-tune the pre-trained model (e.g. CLIP) on specific datasets, which may suffer from substantial storage costs in practical applications since a separate model per task needs to be stored. To overcome this issue, we present the premier work on performing parameter-efficient VTR from the pre-trained model, i.e., only a small number of parameters are tunable while freezing the backbone. Towards this goal, we propose a new method dubbed Multimodal Video Adapter (MV-Adapter) for efficiently transferring the knowledge in the pre-trained CLIP from image-text to video-text. Specifically, MV-Adapter adopts bottleneck structures in both video and text branches and introduces two novel components. The first is a Temporal Adaptation Module employed in the video branch to inject global and local temporal contexts. We also learn weights calibrations to adapt to the dynamic variations across frames. The second is a Cross-Modal Interaction Module that generates weights for video/text branches through a shared parameter space, for better aligning between modalities. Thanks to above innovations, MV-Adapter can achieve on-par or better performance than standard fine-tuning with negligible parameters overhead. Notably, on five widely used VTR benchmarks (MSR-VTT, MSVD, LSMDC, DiDemo, and ActivityNet), MV-Adapter consistently outperforms various competing methods in V2T/T2V tasks with large margins. Codes will be released.