 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECHO: Efficient Chest X-ray Report Generation with One-step Block Diffusion
Apr 10, 2026Chest X-ray report generation (CXR-RG) has the potential to substantially alleviate radiologists' workload. However, conventional autoregressive vision--language models (VLMs) suffer from high inference latency due to sequential token decoding. Diffusion-based models offer a promising alternative through parallel generation, but they still require multiple denoising iterations. Compressing multi-step denoising to a single step could further reduce latency, but often degrades textual coherence due to the mean-field bias introduced by token-factorized denoisers. To address this challenge, we propose \textbf{ECHO}, an efficient diffusion-based VLM (dVLM) for chest X-ray report generation. ECHO enables stable one-step-per-block inference via a novel Direct Conditional Distillation (DCD) framework, which mitigates the mean-field limitation by constructing unfactorized supervision from on-policy diffusion trajectories to encode joint token dependencies. In addition, we introduce a Response-Asymmetric Diffusion (RAD) training strategy that further improves training efficiency while maintaining model effectiveness. Extensive experiments demonstrate that ECHO surpasses state-of-the-art autoregressive methods, improving RaTE and SemScore by \textbf{64.33\%} and \textbf{60.58\%} respectively, while achieving an \textbf{$8\times$} inference speedup without compromising clinical accuracy.
VideoWorld 2: Learning Transferable Knowledge from Real-world Videos
Feb 10, 2026Learning transferable knowledge from unlabeled video data and applying it in new environments is a fundamental capability of intelligent agents. This work presents VideoWorld 2, which extends VideoWorld and offers the first investigation into learning transferable knowledge directly from raw real-world videos. At its core, VideoWorld 2 introduces a dynamic-enhanced Latent Dynamics Model (dLDM) that decouples action dynamics from visual appearance: a pretrained video diffusion model handles visual appearance modeling, enabling the dLDM to learn latent codes that focus on compact and meaningful task-related dynamics. These latent codes are then modeled autoregressively to learn task policies and support long-horizon reasoning. We evaluate VideoWorld 2 on challenging real-world handcraft making tasks, where prior video generation and latent-dynamics models struggle to operate reliably. Remarkably, VideoWorld 2 achieves up to 70% improvement in task success rate and produces coherent long execution videos. In robotics, we show that VideoWorld 2 can acquire effective manipulation knowledge from the Open-X dataset, which substantially improves task performance on CALVIN. This study reveals the potential of learning transferable world knowledge directly from raw videos, with all code, data, and models to be open-sourced for further research.
StereoWorld: Geometry-Aware Monocular-to-Stereo Video Generation
Dec 11, 2025The growing adoption of XR devices has fueled strong demand for high-quality stereo video, yet its production remains costly and artifact-prone. To address this challenge, we present StereoWorld, an end-to-end framework that repurposes a pretrained video generator for high-fidelity monocular-to-stereo video generation. Our framework jointly conditions the model on the monocular video input while explicitly supervising the generation with a geometry-aware regularization to ensure 3D structural fidelity. A spatio-temporal tiling scheme is further integrated to enable efficient, high-resolution synthesis. To enable large-scale training and evaluation, we curate a high-definition stereo video dataset containing over 11M frames aligned to natural human interpupillary distance (IPD). Extensive experiments demonstrate that StereoWorld substantially outperforms prior methods, generating stereo videos with superior visual fidelity and geometric consistency. The project webpage is available at https://ke-xing.github.io/StereoWorld/.
PreFM: Online Audio-Visual Event Parsing via Predictive Future Modeling
May 29, 2025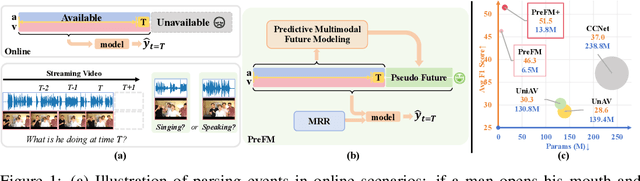
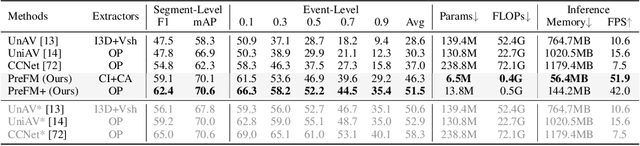
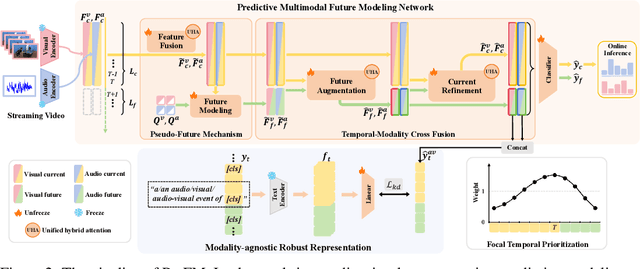
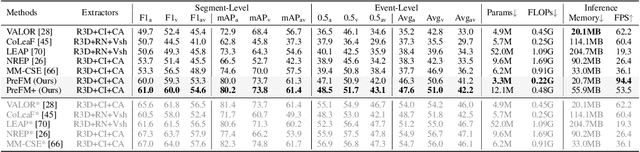
Audio-visual event parsing plays a crucial role in understanding multimodal video content, but existing methods typically rely on offline processing of entire videos with huge model sizes, limiting their real-time applicability. We introduce Online Audio-Visual Event Parsing (On-AVEP), a novel paradigm for parsing audio, visual, and audio-visual events by sequentially analyzing incoming video streams. The On-AVEP task necessitates models with two key capabilities: (1) Accurate online inference, to effectively distinguish events with unclear and limited context in online settings, and (2) Real-time efficiency, to balance high performance with computational constraints. To cultivate these, we propose the Predictive Future Modeling (PreFM) framework featured by (a) predictive multimodal future modeling to infer and integrate beneficial future audio-visual cues, thereby enhancing contextual understanding and (b) modality-agnostic robust representation along with focal temporal prioritization to improve precision and generalization. Extensive experiments on the UnAV-100 and LLP datasets show PreFM significantly outperforms state-of-the-art methods by a large margin with significantly fewer parameters, offering an insightful approach for real-time multimodal video understanding. Code is available at https://github.com/XiaoYu-1123/PreFM.
ScaleLong: A Multi-Timescale Benchmark for Long Video Understanding
May 29, 2025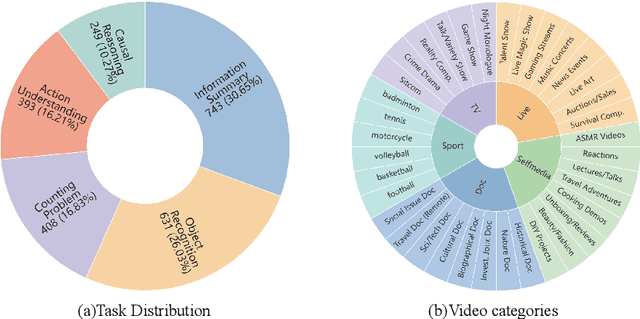



Although long-video understanding demands that models capture hierarchical temporal information -- from clip (seconds) and shot (tens of seconds) to event (minutes) and story (hours) -- existing benchmarks either neglect this multi-scale design or scatter scale-specific questions across different videos, preventing direct comparison of model performance across timescales on the same content. To address this, we introduce ScaleLong, the first benchmark to disentangle these factors by embedding questions targeting four hierarchical timescales -- clip (seconds), shot (tens of seconds), event (minutes), and story (hours) -- all within the same video content. This within-content multi-timescale questioning design enables direct comparison of model performance across timescales on identical videos. ScaleLong features 269 long videos (avg.\ 86\,min) from 5 main categories and 36 sub-categories, with 4--8 carefully designed questions, including at least one question for each timescale. Evaluating 23 MLLMs reveals a U-shaped performance curve, with higher accuracy at the shortest and longest timescales and a dip at intermediate levels. Furthermore, ablation studies show that increased visual token capacity consistently enhances reasoning across all timescales. ScaleLong offers a fine-grained, multi-timescale benchmark for advancing MLLM capabilities in long-video understanding. The code and dataset are available https://github.com/multimodal-art-projection/ScaleLong.
IV-Bench: A Benchmark for Image-Grounded Video Perception and Reasoning in Multimodal LLMs
Apr 21, 2025Existing evaluation frameworks for Multimodal Large Language Models (MLLMs) primarily focus on image reasoning or general video understanding tasks, largely overlooking the significant role of image context in video comprehension. To bridge this gap, we propose IV-Bench, the first comprehensive benchmark for evaluating Image-Grounded Video Perception and Reasoning. IV-Bench consists of 967 videos paired with 2,585 meticulously annotated image-text queries across 13 tasks (7 perception and 6 reasoning tasks) and 5 representative categories. Extensive evaluations of state-of-the-art open-source (e.g., InternVL2.5, Qwen2.5-VL) and closed-source (e.g., GPT-4o, Gemini2-Flash and Gemini2-Pro) MLLMs demonstrate that current models substantially underperform in image-grounded video Perception and Reasoning, merely achieving at most 28.9% accuracy. Further analysis reveals key factors influencing model performance on IV-Bench, including inference pattern, frame number, and resolution. Additionally, through a simple data synthesis approach, we demonstratethe challenges of IV- Bench extend beyond merely aligning the data format in the training proecss. These findings collectively provide valuable insights for future research. Our codes and data are released in https://github.com/multimodal-art-projection/IV-Bench.
COCONut-PanCap: Joint Panoptic Segmentation and Grounded Captions for Fine-Grained Understanding and Generation
Feb 04, 2025This paper introduces the COCONut-PanCap dataset, created to enhance panoptic segmentation and grounded image captioning. Building upon the COCO dataset with advanced COCONut panoptic masks, this dataset aims to overcome limitations in existing image-text datasets that often lack detailed, scene-comprehensive descriptions. The COCONut-PanCap dataset incorporates fine-grained, region-level captions grounded in panoptic segmentation masks, ensuring consistency and improving the detail of generated captions. Through human-edited, densely annotated descriptions, COCONut-PanCap supports improved training of vision-language models (VLMs) for image understanding and generative models for text-to-image tasks. Experimental results demonstrate that COCONut-PanCap significantly boosts performance across understanding and generation tasks, offering complementary benefits to large-scale datasets. This dataset sets a new benchmark for evaluating models on joint panoptic segmentation and grounded captioning tasks, addressing the need for high-quality, detailed image-text annotations in multi-modal learning.
VideoWorld: Exploring Knowledge Learning from Unlabeled Videos
Jan 16, 2025This work explores whether a deep generative model can learn complex knowledge solely from visual input, in contrast to the prevalent focus on text-based models like large language models (LLMs). We develop VideoWorld, an auto-regressive video generation model trained on unlabeled video data, and test its knowledge acquisition abilities in video-based Go and robotic control tasks. Our experiments reveal two key findings: (1) video-only training provides sufficient information for learning knowledge, including rules, reasoning and planning capabilities, and (2) the representation of visual change is crucial for knowledge acquisition. To improve both the efficiency and efficacy of this process, we introduce the Latent Dynamics Model (LDM) as a key component of VideoWorld. Remarkably, VideoWorld reaches a 5-dan professional level in the Video-GoBench with just a 300-million-parameter model, without relying on search algorithms or reward mechanisms typical in reinforcement learning. In robotic tasks, VideoWorld effectively learns diverse control operations and generalizes across environments, approaching the performance of oracle models in CALVIN and RLBench. This study opens new avenues for knowledge acquisition from visual data, with all code, data, and models open-sourced for further research.
VCoME: Verbal Video Composition with Multimodal Editing Effects
Jul 05, 2024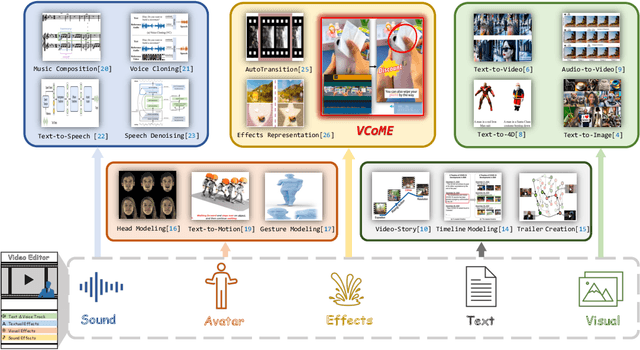
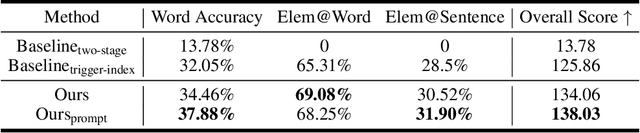
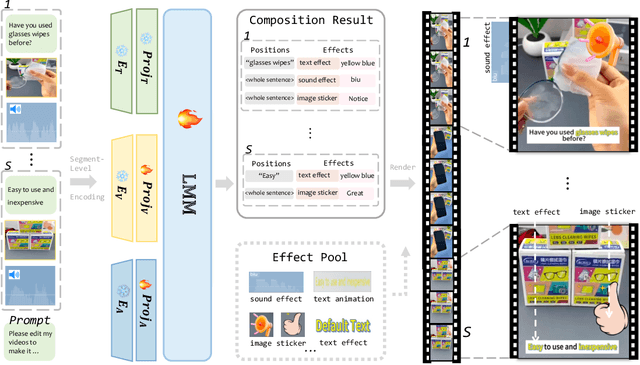

Verbal videos, featuring voice-overs or text overlays, provide valuable content but present significant challenges in composition, especially when incorporating editing effects to enhance clarity and visual appeal. In this paper, we introduce the novel task of verbal video composition with editing effects. This task aims to generate coherent and visually appealing verbal videos by integrating multimodal editing effects across textual, visual, and audio categories. To achieve this, we curate a large-scale dataset of video effects compositions from publicly available sources. We then formulate this task as a generative problem, involving the identification of appropriate positions in the verbal content and the recommendation of editing effects for these positions. To address this task, we propose VCoME, a general framework that employs a large multimodal model to generate editing effects for video composition. Specifically, VCoME takes in the multimodal video context and autoregressively outputs where to apply effects within the verbal content and which effects are most appropriate for each position. VCoME also supports prompt-based control of composition density and style, providing substantial flexibility for diverse applications. Through extensive quantitative and qualitative evaluations, we clearly demonstrate the effectiveness of VCoME. A comprehensive user study shows that our method produces videos of professional quality while being 85$\times$ more efficient than professional editors.
Hierarchical Memory for Long Video QA
Jun 30, 2024


This paper describes our champion solution to the LOVEU Challenge @ CVPR'24, Track 1 (Long Video VQA). Processing long sequences of visual tokens is computationally expensive and memory-intensive, making long video question-answering a challenging task. The key is to compress visual tokens effectively, reducing memory footprint and decoding latency, while preserving the essential information for accurate question-answering. We adopt a hierarchical memory mechanism named STAR Memory, proposed in Flash-VStream, that is capable of processing long videos with limited GPU memory (VRAM). We further utilize the video and audio data of MovieChat-1K training set to fine-tune the pretrained weight released by Flash-VStream, achieving 1st place in the challenge. Code is available at project homepage https://invinciblewyq.github.io/vstream-page