 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCA-HFP: Curvature-Aware Heterogeneous Federated Pruning with Model Reconstruction
Mar 13, 2026Federated learning on heterogeneous edge devices requires personalized compression while preserving aggregation compatibility and stable convergence. We present Curvature-Aware Heterogeneous Federated Pruning (CA-HFP), a practical framework that enables each client perform structured, device-specific pruning guided by a curvature-informed significance score, and subsequently maps its compact submodel back into a common global parameter space via a lightweight reconstruction. We derive a convergence bound for federated optimization with multiple local SGD steps that explicitly accounts for local computation, data heterogeneity, and pruning-induced perturbations; from which a principled loss-based pruning criterion is derived. Extensive experiments on FMNIST, CIFAR-10, and CIFAR-100 using VGG and ResNet architectures under varying degrees of data heterogeneity demonstrate that CA-HFP preserves model accuracy while significantly reducing per-client computation and communication costs, outperforming standard federated training and existing pruning-based baselines.
FFT-MoE: Efficient Federated Fine-Tuning for Foundation Models via Large-scale Sparse MoE under Heterogeneous Edge
Aug 26, 2025As FMs drive progress toward Artificial General Intelligence (AGI), fine-tuning them under privacy and resource constraints has become increasingly critical particularly when highquality training data resides on distributed edge devices. Federated Learning (FL) offers a compelling solution through Federated Fine-Tuning (FFT), which enables collaborative model adaptation without sharing raw data. Recent approaches incorporate Parameter-Efficient Fine-Tuning (PEFT) techniques such as Low Rank Adaptation (LoRA) to reduce computational overhead. However, LoRA-based FFT faces two major limitations in heterogeneous FL environments: structural incompatibility across clients with varying LoRA configurations and limited adaptability to non-IID data distributions, which hinders convergence and generalization. To address these challenges, we propose FFT MoE, a novel FFT framework that replaces LoRA with sparse Mixture of Experts (MoE) adapters. Each client trains a lightweight gating network to selectively activate a personalized subset of experts, enabling fine-grained adaptation to local resource budgets while preserving aggregation compatibility. To further combat the expert load imbalance caused by device and data heterogeneity, we introduce a heterogeneity-aware auxiliary loss that dynamically regularizes the routing distribution to ensure expert diversity and balanced utilization. Extensive experiments spanning both IID and non-IID conditions demonstrate that FFT MoE consistently outperforms state of the art FFT baselines in generalization performance and training efficiency.
Split Federated Learning Over Heterogeneous Edge Devices: Algorithm and Optimization
Nov 21, 2024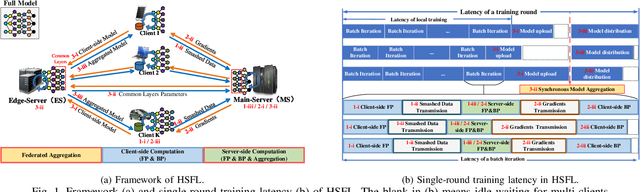
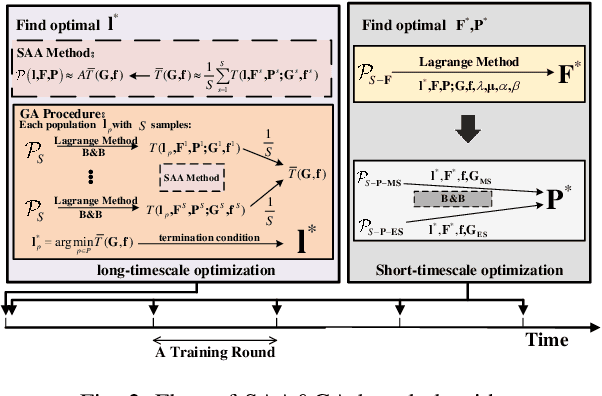
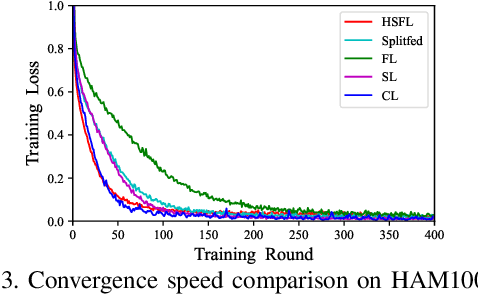
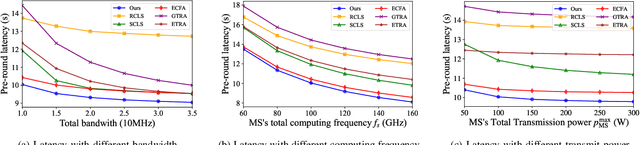
Split Learning (SL) is a promising collaborative machine learning approach, enabling resource-constrained devices to train models without sharing raw data, while reducing computational load and preserving privacy simultaneously. However, current SL algorithms face limitations in training efficiency and suffer from prolonged latency, particularly in sequential settings, where the slowest device can bottleneck the entire process due to heterogeneous resources and frequent data exchanges between clients and servers. To address these challenges, we propose the Heterogeneous Split Federated Learning (HSFL) framework, which allows resource-constrained clients to train their personalized client-side models in parallel, utilizing different cut layers. Aiming to mitigate the impact of heterogeneous environments and accelerate the training process, we formulate a latency minimization problem that optimizes computational and transmission resources jointly. Additionally, we design a resource allocation algorithm that combines the Sample Average Approximation (SAA), Genetic Algorithm (GA), Lagrangian relaxation and Branch and Bound (B\&B) methods to efficiently solve this problem. Simulation results demonstrate that HSFL outperforms other frameworks in terms of both convergence rate and model accuracy on heterogeneous devices with non-iid data, while the optimization algorithm is better than other baseline methods in reducing latency.
Faster Convergence on Heterogeneous Federated Edge Learning: An Adaptive Sidelink-Assisted Data Multicasting Approach
Jun 14, 2024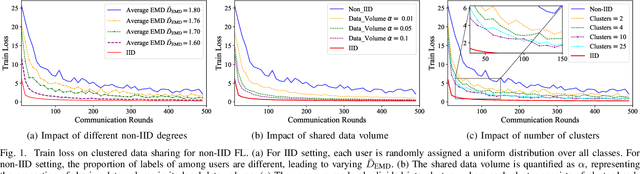


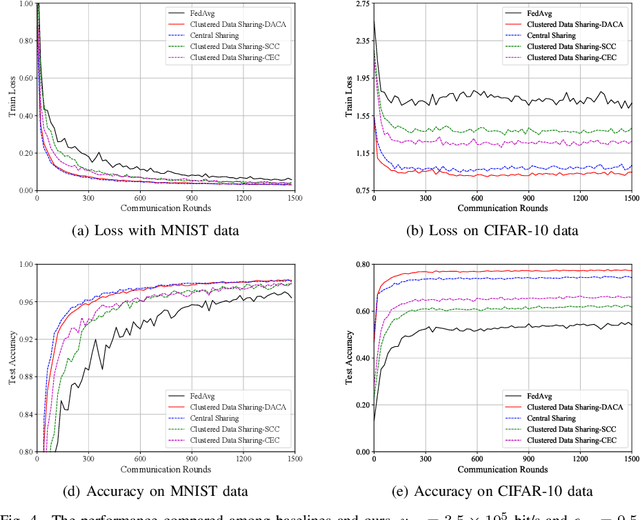
Federated Edge Learning (FEEL) emerges as a pioneering distributed machine learning paradigm for the 6G Hyper-Connectivity, harnessing data from the Internet of Things (IoT) devices while upholding data privacy. However, current FEEL algorithms struggle with non-independent and non-identically distributed (non-IID) data, leading to elevated communication costs and compromised model accuracy. To address these statistical imbalances within FEEL, we introduce a clustered data sharing framework, mitigating data heterogeneity by selectively sharing partial data from cluster heads to trusted associates through sidelink-aided multicasting. The collective communication pattern is integral to FEEL training, where both cluster formation and the efficiency of communication and computation impact training latency and accuracy simultaneously. To tackle the strictly coupled data sharing and resource optimization, we decompose the overall optimization problem into the clients clustering and effective data sharing subproblems. Specifically, a distribution-based adaptive clustering algorithm (DACA) is devised basing on three deductive cluster forming conditions, which ensures the maximum sharing yield. Meanwhile, we design a stochastic optimization based joint computed frequency and shared data volume optimization (JFVO) algorithm, determining the optimal resource allocation with an uncertain objective function. The experiments show that the proposed framework facilitates FEEL on non-IID datasets with faster convergence rate and higher model accuracy in a limited communication environment.
The SkatingVerse Workshop & Challenge: Methods and Results
May 27, 2024

The SkatingVerse Workshop & Challenge aims to encourage research in developing novel and accurate methods for human action understanding. The SkatingVerse dataset used for the SkatingVerse Challenge has been publicly released. There are two subsets in the dataset, i.e., the training subset and testing subset. The training subsets consists of 19,993 RGB video sequences, and the testing subsets consists of 8,586 RGB video sequences. Around 10 participating teams from the globe competed in the SkatingVerse Challenge. In this paper, we provide a brief summary of the SkatingVerse Workshop & Challenge including brief introductions to the top three methods. The submission leaderboard will be reopened for researchers that are interested in the human action understanding challenge. The benchmark dataset and other information can be found at: https://skatingverse.github.io/.
Clustered Data Sharing for Non-IID Federated Learning over Wireless Networks
Mar 01, 2023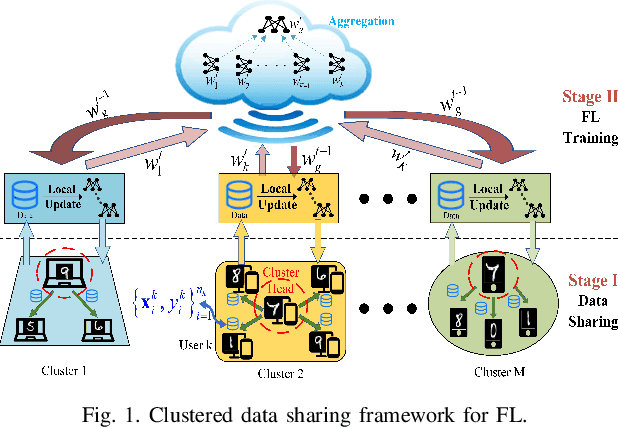
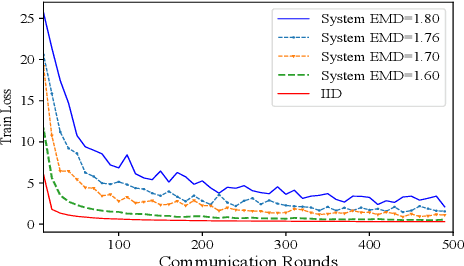
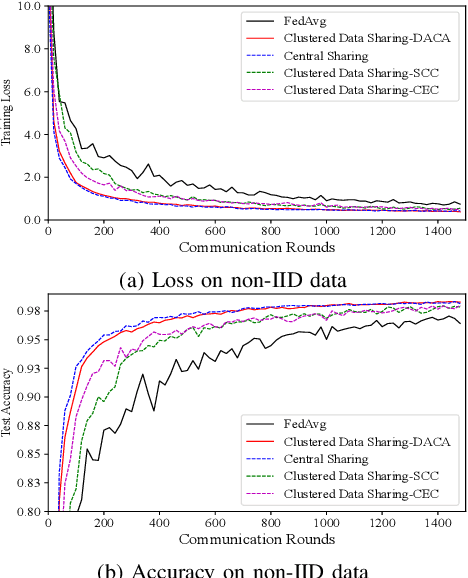
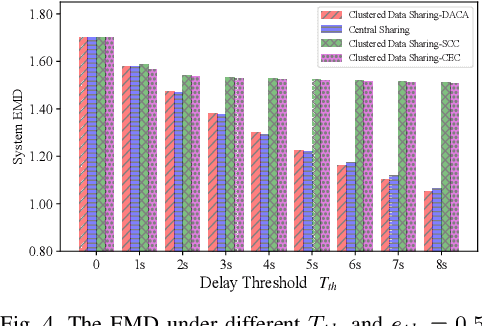
Federated Learning (FL) is a novel distributed machine learning approach to leverage data from Internet of Things (IoT) devices while maintaining data privacy. However, the current FL algorithms face the challenges of non-independent and identically distributed (non-IID) data, which causes high communication costs and model accuracy declines. To address the statistical imbalances in FL, we propose a clustered data sharing framework which spares the partial data from cluster heads to credible associates through device-to-device (D2D) communication. Moreover, aiming at diluting the data skew on nodes, we formulate the joint clustering and data sharing problem based on the privacy-preserving constrained graph. To tackle the serious coupling of decisions on the graph, we devise a distribution-based adaptive clustering algorithm (DACA) basing on three deductive cluster-forming conditions, which ensures the maximum yield of data sharing. The experiments show that the proposed framework facilitates FL on non-IID datasets with better convergence and model accuracy under a limited communication environment.
Multi scale Feature Extraction and Fusion for Online Knowledge Distillation
Jun 16, 2022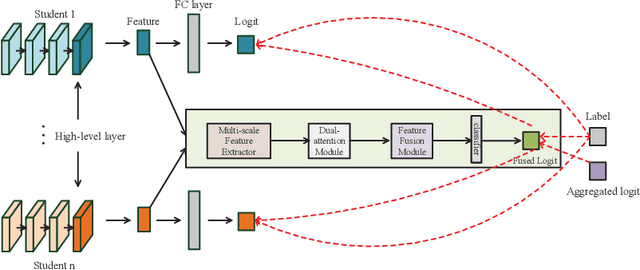
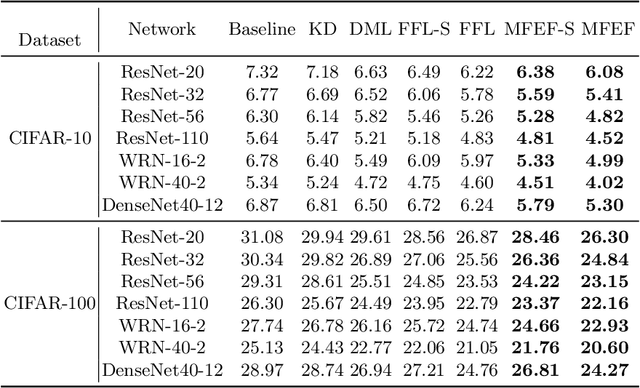
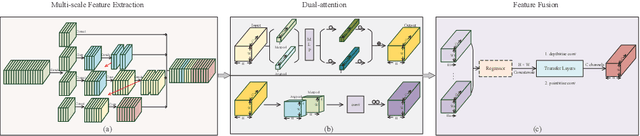

Online knowledge distillation conducts knowledge transfer among all student models to alleviate the reliance on pre-trained models. However, existing online methods rely heavily on the prediction distributions and neglect the further exploration of the representational knowledge. In this paper, we propose a novel Multi-scale Feature Extraction and Fusion method (MFEF) for online knowledge distillation, which comprises three key components: Multi-scale Feature Extraction, Dual-attention and Feature Fusion, towards generating more informative feature maps for distillation. The multiscale feature extraction exploiting divide-and-concatenate in channel dimension is proposed to improve the multi-scale representation ability of feature maps. To obtain more accurate information, we design a dual-attention to strengthen the important channel and spatial regions adaptively. Moreover, we aggregate and fuse the former processed feature maps via feature fusion to assist the training of student models. Extensive experiments on CIF AR-10, CIF AR-100, and CINIC-10 show that MFEF transfers more beneficial representational knowledge for distillation and outperforms alternative methods among various network architectures
Asymptotic Soft Cluster Pruning for Deep Neural Networks
Jun 16, 2022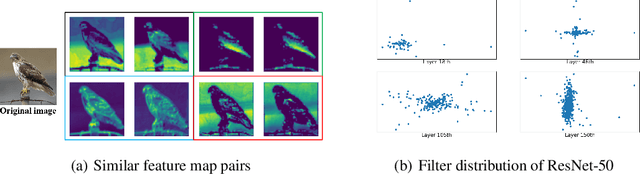
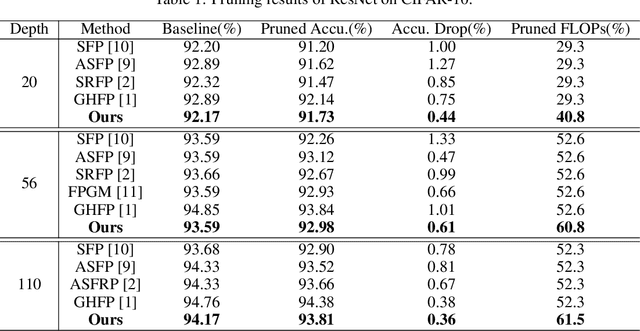
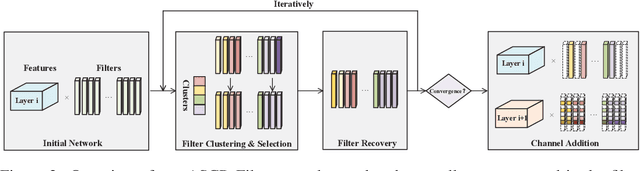
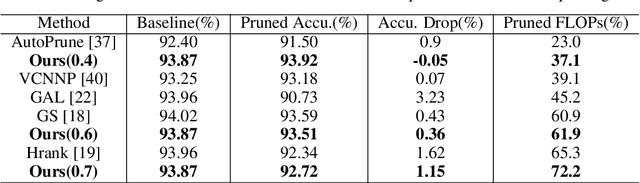
Filter pruning method introduces structural sparsity by removing selected filters and is thus particularly effective for reducing complexity. Previous works empirically prune networks from the point of view that filter with smaller norm contributes less to the final results. However, such criteria has been proven sensitive to the distribution of filters, and the accuracy may hard to recover since the capacity gap is fixed once pruned. In this paper, we propose a novel filter pruning method called Asymptotic Soft Cluster Pruning (ASCP), to identify the redundancy of network based on the similarity of filters. Each filter from over-parameterized network is first distinguished by clustering, and then reconstructed to manually introduce redundancy into it. Several guidelines of clustering are proposed to better preserve feature extraction ability. After reconstruction, filters are allowed to be updated to eliminate the effect caused by mistakenly selected. Besides, various decaying strategies of the pruning rate are adopted to stabilize the pruning process and improve the final performance as well. By gradually generating more identical filters within each cluster, ASCP can remove them through channel addition operation with almost no accuracy drop. Extensive experiments on CIFAR-10 and ImageNet datasets show that our method can achieve competitive results compared with many state-of-the-art algorithms.
An Adaptive Device-Edge Co-Inference Framework Based on Soft Actor-Critic
Jan 09, 2022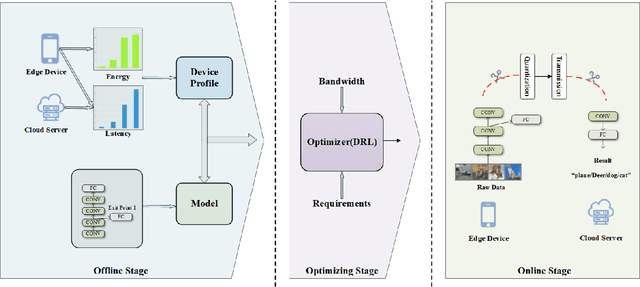
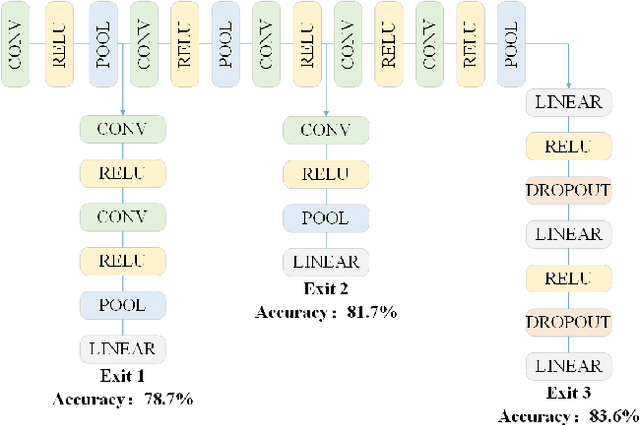
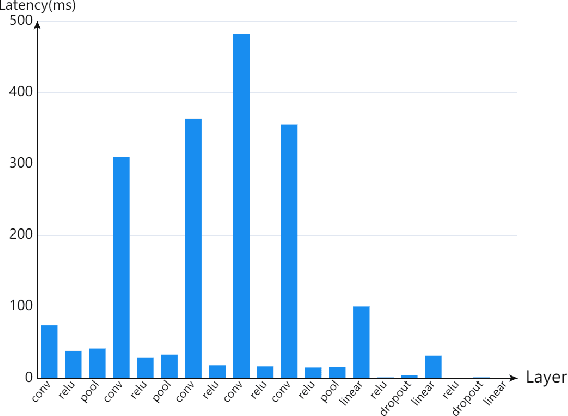
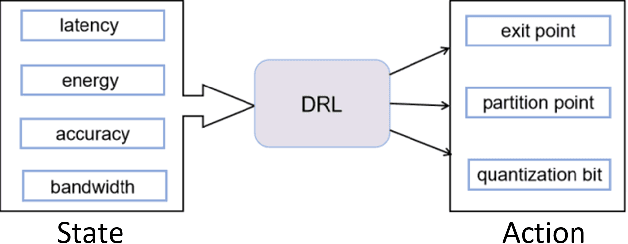
Recently, the applications of deep neural network (DNN) have been very prominent in many fields such as computer vision (CV) and natural language processing (NLP) due to its superior feature extraction performance. However, the high-dimension parameter model and large-scale mathematical calculation restrict the execution efficiency, especially for Internet of Things (IoT) devices. Different from the previous cloud/edge-only pattern that brings huge pressure for uplink communication and device-only fashion that undertakes unaffordable calculation strength, we highlight the collaborative computation between the device and edge for DNN models, which can achieve a good balance between the communication load and execution accuracy. Specifically, a systematic on-demand co-inference framework is proposed to exploit the multi-branch structure, in which the pre-trained Alexnet is right-sized through \emph{early-exit} and partitioned at an intermediate DNN layer. The integer quantization is enforced to further compress transmission bits. As a result, we establish a new Deep Reinforcement Learning (DRL) optimizer-Soft Actor Critic for discrete (SAC-d), which generates the \emph{exit point}, \emph{partition point}, and \emph{compressing bits} by soft policy iterations. Based on the latency and accuracy aware reward design, such an optimizer can well adapt to the complex environment like dynamic wireless channel and arbitrary CPU processing, and is capable of supporting the 5G URLLC. Real-world experiment on Raspberry Pi 4 and PC shows the outperformance of the proposed solution.