 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti scale Feature Extraction and Fusion for Online Knowledge Distillation
Jun 16, 2022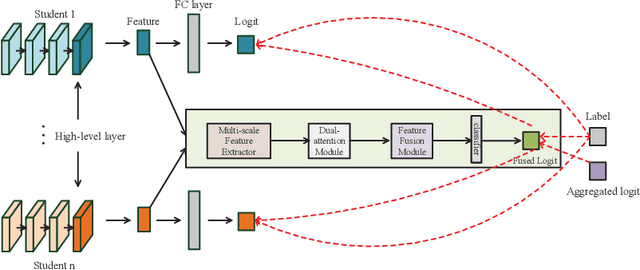
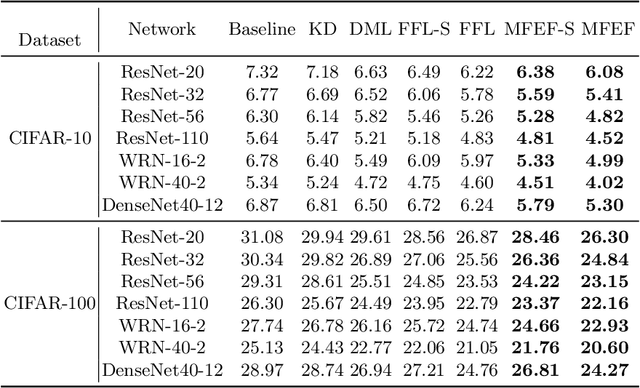
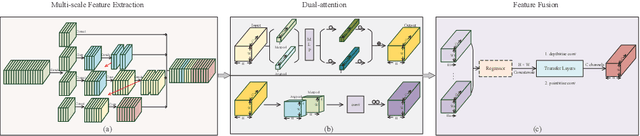

Online knowledge distillation conducts knowledge transfer among all student models to alleviate the reliance on pre-trained models. However, existing online methods rely heavily on the prediction distributions and neglect the further exploration of the representational knowledge. In this paper, we propose a novel Multi-scale Feature Extraction and Fusion method (MFEF) for online knowledge distillation, which comprises three key components: Multi-scale Feature Extraction, Dual-attention and Feature Fusion, towards generating more informative feature maps for distillation. The multiscale feature extraction exploiting divide-and-concatenate in channel dimension is proposed to improve the multi-scale representation ability of feature maps. To obtain more accurate information, we design a dual-attention to strengthen the important channel and spatial regions adaptively. Moreover, we aggregate and fuse the former processed feature maps via feature fusion to assist the training of student models. Extensive experiments on CIF AR-10, CIF AR-100, and CINIC-10 show that MFEF transfers more beneficial representational knowledge for distillation and outperforms alternative methods among various network architectures
Asymptotic Soft Cluster Pruning for Deep Neural Networks
Jun 16, 2022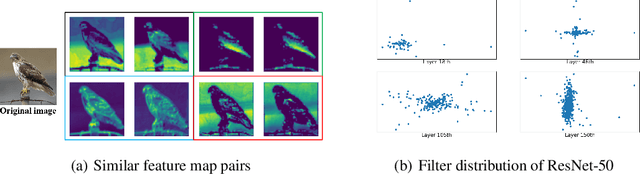
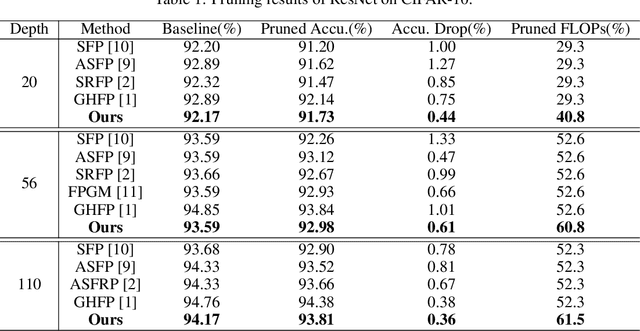
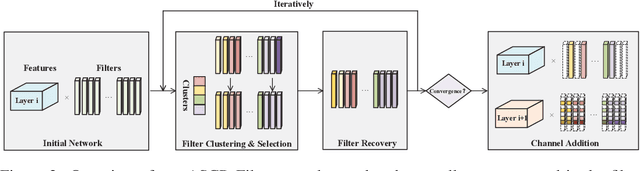
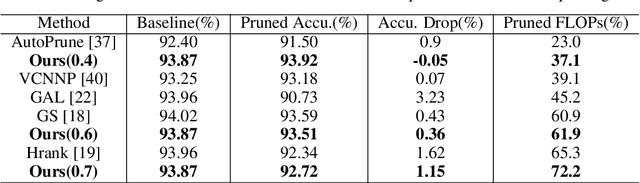
Filter pruning method introduces structural sparsity by removing selected filters and is thus particularly effective for reducing complexity. Previous works empirically prune networks from the point of view that filter with smaller norm contributes less to the final results. However, such criteria has been proven sensitive to the distribution of filters, and the accuracy may hard to recover since the capacity gap is fixed once pruned. In this paper, we propose a novel filter pruning method called Asymptotic Soft Cluster Pruning (ASCP), to identify the redundancy of network based on the similarity of filters. Each filter from over-parameterized network is first distinguished by clustering, and then reconstructed to manually introduce redundancy into it. Several guidelines of clustering are proposed to better preserve feature extraction ability. After reconstruction, filters are allowed to be updated to eliminate the effect caused by mistakenly selected. Besides, various decaying strategies of the pruning rate are adopted to stabilize the pruning process and improve the final performance as well. By gradually generating more identical filters within each cluster, ASCP can remove them through channel addition operation with almost no accuracy drop. Extensive experiments on CIFAR-10 and ImageNet datasets show that our method can achieve competitive results compared with many state-of-the-art algorithms.
An Adaptive Device-Edge Co-Inference Framework Based on Soft Actor-Critic
Jan 09, 2022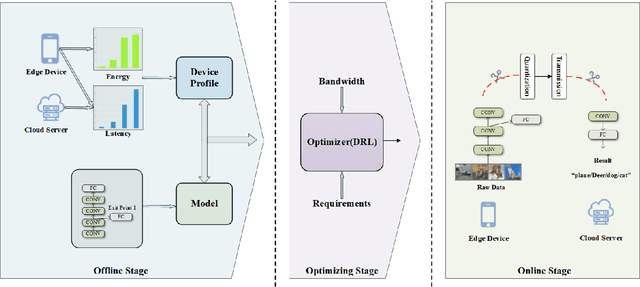
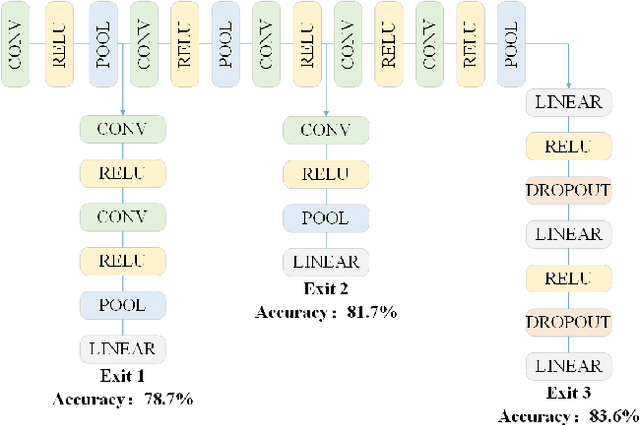
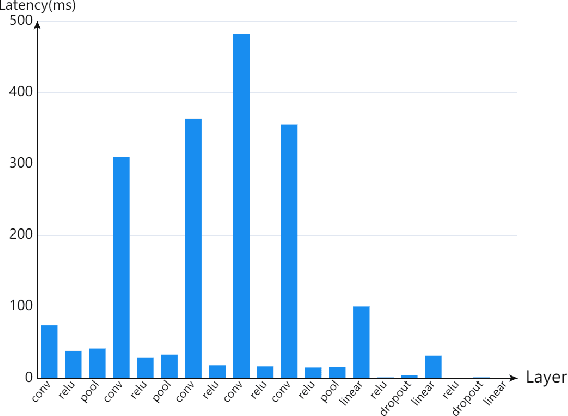
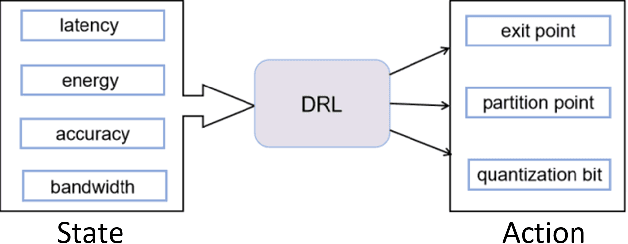
Recently, the applications of deep neural network (DNN) have been very prominent in many fields such as computer vision (CV) and natural language processing (NLP) due to its superior feature extraction performance. However, the high-dimension parameter model and large-scale mathematical calculation restrict the execution efficiency, especially for Internet of Things (IoT) devices. Different from the previous cloud/edge-only pattern that brings huge pressure for uplink communication and device-only fashion that undertakes unaffordable calculation strength, we highlight the collaborative computation between the device and edge for DNN models, which can achieve a good balance between the communication load and execution accuracy. Specifically, a systematic on-demand co-inference framework is proposed to exploit the multi-branch structure, in which the pre-trained Alexnet is right-sized through \emph{early-exit} and partitioned at an intermediate DNN layer. The integer quantization is enforced to further compress transmission bits. As a result, we establish a new Deep Reinforcement Learning (DRL) optimizer-Soft Actor Critic for discrete (SAC-d), which generates the \emph{exit point}, \emph{partition point}, and \emph{compressing bits} by soft policy iterations. Based on the latency and accuracy aware reward design, such an optimizer can well adapt to the complex environment like dynamic wireless channel and arbitrary CPU processing, and is capable of supporting the 5G URLLC. Real-world experiment on Raspberry Pi 4 and PC shows the outperformance of the proposed solution.