 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Speculative Decoding: Rethinking Draft Training from Token Likelihood to Sequence Acceptance
Feb 05, 2026Speculative decoding accelerates inference for (M)LLMs, yet a training-decoding discrepancy persists: while existing methods optimize single greedy trajectories, decoding involves verifying and ranking multiple sampled draft paths. We propose Variational Speculative Decoding (VSD), formulating draft training as variational inference over latent proposals (draft paths). VSD maximizes the marginal probability of target-model acceptance, yielding an ELBO that promotes high-quality latent proposals while minimizing divergence from the target distribution. To enhance quality and reduce variance, we incorporate a path-level utility and optimize via an Expectation-Maximization procedure. The E-step draws MCMC samples from an oracle-filtered posterior, while the M-step maximizes weighted likelihood using Adaptive Rejection Weighting (ARW) and Confidence-Aware Regularization (CAR). Theoretical analysis confirms that VSD increases expected acceptance length and speedup. Extensive experiments across LLMs and MLLMs show that VSD achieves up to a 9.6% speedup over EAGLE-3 and 7.9% over ViSpec, significantly improving decoding efficiency.
LogicLens: Visual-Logical Co-Reasoning for Text-Centric Forgery Analysis
Dec 25, 2025Sophisticated text-centric forgeries, fueled by rapid AIGC advancements, pose a significant threat to societal security and information authenticity. Current methods for text-centric forgery analysis are often limited to coarse-grained visual analysis and lack the capacity for sophisticated reasoning. Moreover, they typically treat detection, grounding, and explanation as discrete sub-tasks, overlooking their intrinsic relationships for holistic performance enhancement. To address these challenges, we introduce LogicLens, a unified framework for Visual-Textual Co-reasoning that reformulates these objectives into a joint task. The deep reasoning of LogicLens is powered by our novel Cross-Cues-aware Chain of Thought (CCT) mechanism, which iteratively cross-validates visual cues against textual logic. To ensure robust alignment across all tasks, we further propose a weighted multi-task reward function for GRPO-based optimization. Complementing this framework, we first designed the PR$^2$ (Perceiver, Reasoner, Reviewer) pipeline, a hierarchical and iterative multi-agent system that generates high-quality, cognitively-aligned annotations. Then, we constructed RealText, a diverse dataset comprising 5,397 images with fine-grained annotations, including textual explanations, pixel-level segmentation, and authenticity labels for model training. Extensive experiments demonstrate the superiority of LogicLens across multiple benchmarks. In a zero-shot evaluation on T-IC13, it surpasses the specialized framework by 41.4% and GPT-4o by 23.4% in macro-average F1 score. Moreover, on the challenging dense-text T-SROIE dataset, it establishes a significant lead over other MLLM-based methods in mF1, CSS, and the macro-average F1. Our dataset, model, and code will be made publicly available.
Dual-Flow: Transferable Multi-Target, Instance-Agnostic Attacks via In-the-wild Cascading Flow Optimization
Feb 05, 2025



Adversarial attacks are widely used to evaluate model robustness, and in black-box scenarios, the transferability of these attacks becomes crucial. Existing generator-based attacks have excellent generalization and transferability due to their instance-agnostic nature. However, when training generators for multi-target tasks, the success rate of transfer attacks is relatively low due to the limitations of the model's capacity. To address these challenges, we propose a novel Dual-Flow framework for multi-target instance-agnostic adversarial attacks, utilizing Cascading Distribution Shift Training to develop an adversarial velocity function. Extensive experiments demonstrate that Dual-Flow significantly improves transferability over previous multi-target generative attacks. For example, it increases the success rate from Inception-v3 to ResNet-152 by 34.58%. Furthermore, our attack method shows substantially stronger robustness against defense mechanisms, such as adversarially trained models.
Inclusion 2024 Global Multimedia Deepfake Detection: Towards Multi-dimensional Facial Forgery Detection
Dec 30, 2024



In this paper, we present the Global Multimedia Deepfake Detection held concurrently with the Inclusion 2024. Our Multimedia Deepfake Detection aims to detect automatic image and audio-video manipulations including but not limited to editing, synthesis, generation, Photoshop,etc. Our challenge has attracted 1500 teams from all over the world, with about 5000 valid result submission counts. We invite the top 20 teams to present their solutions to the challenge, from which the top 3 teams are awarded prizes in the grand finale. In this paper, we present the solutions from the top 3 teams of the two tracks, to boost the research work in the field of image and audio-video forgery detection. The methodologies developed through the challenge will contribute to the development of next-generation deepfake detection systems and we encourage participants to open source their methods.
The SkatingVerse Workshop & Challenge: Methods and Results
May 27, 2024

The SkatingVerse Workshop & Challenge aims to encourage research in developing novel and accurate methods for human action understanding. The SkatingVerse dataset used for the SkatingVerse Challenge has been publicly released. There are two subsets in the dataset, i.e., the training subset and testing subset. The training subsets consists of 19,993 RGB video sequences, and the testing subsets consists of 8,586 RGB video sequences. Around 10 participating teams from the globe competed in the SkatingVerse Challenge. In this paper, we provide a brief summary of the SkatingVerse Workshop & Challenge including brief introductions to the top three methods. The submission leaderboard will be reopened for researchers that are interested in the human action understanding challenge. The benchmark dataset and other information can be found at: https://skatingverse.github.io/.
DriveWorld: 4D Pre-trained Scene Understanding via World Models for Autonomous Driving
May 07, 2024Vision-centric autonomous driving has recently raised wide attention due to its lower cost. Pre-training is essential for extracting a universal representation. However, current vision-centric pre-training typically relies on either 2D or 3D pre-text tasks, overlooking the temporal characteristics of autonomous driving as a 4D scene understanding task. In this paper, we address this challenge by introducing a world model-based autonomous driving 4D representation learning framework, dubbed \emph{DriveWorld}, which is capable of pre-training from multi-camera driving videos in a spatio-temporal fashion. Specifically, we propose a Memory State-Space Model for spatio-temporal modelling, which consists of a Dynamic Memory Bank module for learning temporal-aware latent dynamics to predict future changes and a Static Scene Propagation module for learning spatial-aware latent statics to offer comprehensive scene contexts. We additionally introduce a Task Prompt to decouple task-aware features for various downstream tasks. The experiments demonstrate that DriveWorld delivers promising results on various autonomous driving tasks. When pre-trained with the OpenScene dataset, DriveWorld achieves a 7.5% increase in mAP for 3D object detection, a 3.0% increase in IoU for online mapping, a 5.0% increase in AMOTA for multi-object tracking, a 0.1m decrease in minADE for motion forecasting, a 3.0% increase in IoU for occupancy prediction, and a 0.34m reduction in average L2 error for planning.
Adaptive Hybrid Masking Strategy for Privacy-Preserving Face Recognition Against Model Inversion Attack
Mar 14, 2024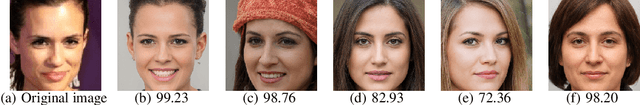

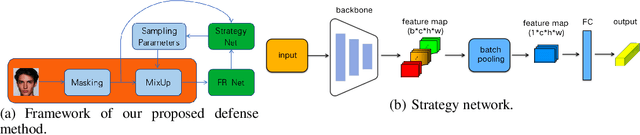
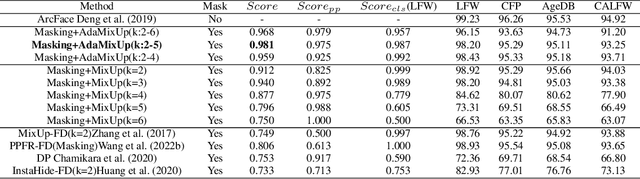
The utilization of personal sensitive data in training face recognition (FR) models poses significant privacy concerns, as adversaries can employ model inversion attacks (MIA) to infer the original training data. Existing defense methods, such as data augmentation and differential privacy, have been employed to mitigate this issue. However, these methods often fail to strike an optimal balance between privacy and accuracy. To address this limitation, this paper introduces an adaptive hybrid masking algorithm against MIA. Specifically, face images are masked in the frequency domain using an adaptive MixUp strategy. Unlike the traditional MixUp algorithm, which is predominantly used for data augmentation, our modified approach incorporates frequency domain mixing. Previous studies have shown that increasing the number of images mixed in MixUp can enhance privacy preservation but at the expense of reduced face recognition accuracy. To overcome this trade-off, we develop an enhanced adaptive MixUp strategy based on reinforcement learning, which enables us to mix a larger number of images while maintaining satisfactory recognition accuracy. To optimize privacy protection, we propose maximizing the reward function (i.e., the loss function of the FR system) during the training of the strategy network. While the loss function of the FR network is minimized in the phase of training the FR network. The strategy network and the face recognition network can be viewed as antagonistic entities in the training process, ultimately reaching a more balanced trade-off. Experimental results demonstrate that our proposed hybrid masking scheme outperforms existing defense algorithms in terms of privacy preservation and recognition accuracy against MIA.
Machine Learning Insides OptVerse AI Solver: Design Principles and Applications
Jan 17, 2024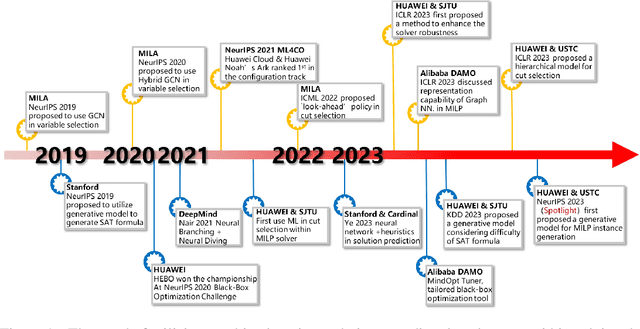
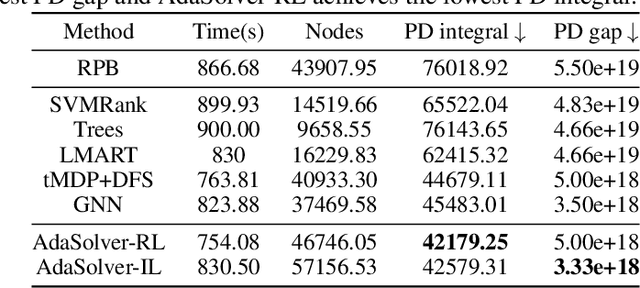

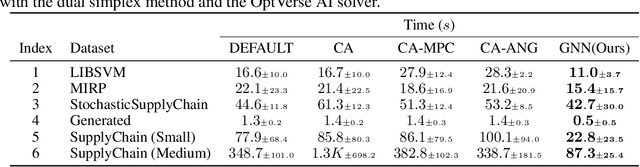
In an era of digital ubiquity, efficient resource management and decision-making are paramount across numerous industries. To this end, we present a comprehensive study on the integration of machine learning (ML) techniques into Huawei Cloud's OptVerse AI Solver, which aims to mitigate the scarcity of real-world mathematical programming instances, and to surpass the capabilities of traditional optimization techniques. We showcase our methods for generating complex SAT and MILP instances utilizing generative models that mirror multifaceted structures of real-world problem. Furthermore, we introduce a training framework leveraging augmentation policies to maintain solvers' utility in dynamic environments. Besides the data generation and augmentation, our proposed approaches also include novel ML-driven policies for personalized solver strategies, with an emphasis on applications like graph convolutional networks for initial basis selection and reinforcement learning for advanced presolving and cut selection. Additionally, we detail the incorporation of state-of-the-art parameter tuning algorithms which markedly elevate solver performance. Compared with traditional solvers such as Cplex and SCIP, our ML-augmented OptVerse AI Solver demonstrates superior speed and precision across both established benchmarks and real-world scenarios, reinforcing the practical imperative and effectiveness of machine learning techniques in mathematical programming solvers.
Fast Propagation is Better: Accelerating Single-Step Adversarial Training via Sampling Subnetworks
Oct 24, 2023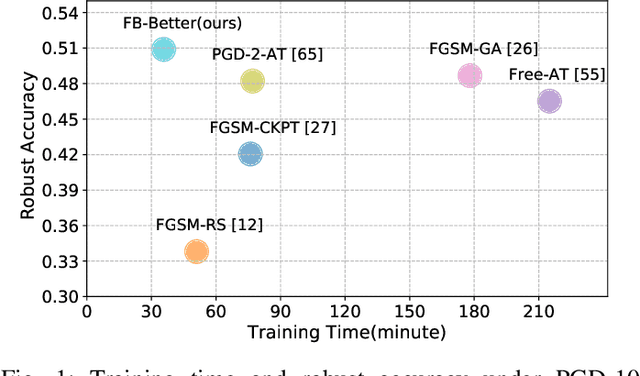
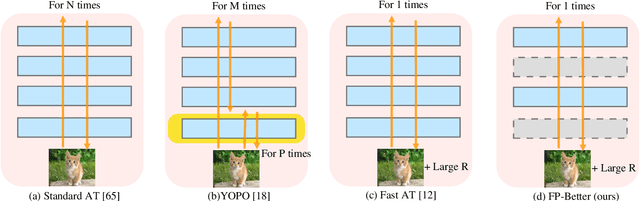
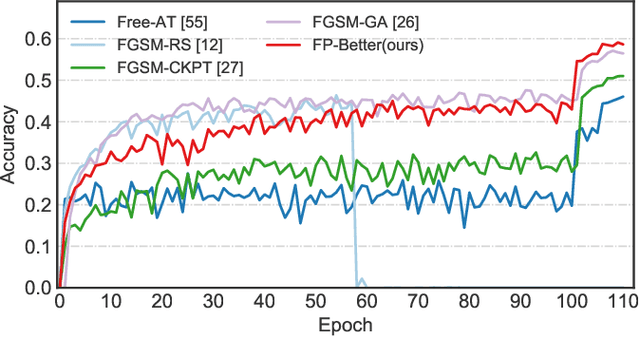
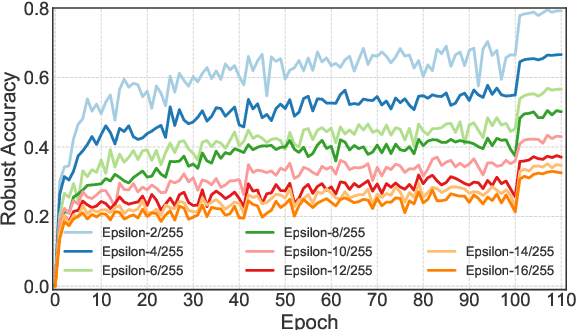
Adversarial training has shown promise in building robust models against adversarial examples. A major drawback of adversarial training is the computational overhead introduced by the generation of adversarial examples. To overcome this limitation, adversarial training based on single-step attacks has been explored. Previous work improves the single-step adversarial training from different perspectives, e.g., sample initialization, loss regularization, and training strategy. Almost all of them treat the underlying model as a black box. In this work, we propose to exploit the interior building blocks of the model to improve efficiency. Specifically, we propose to dynamically sample lightweight subnetworks as a surrogate model during training. By doing this, both the forward and backward passes can be accelerated for efficient adversarial training. Besides, we provide theoretical analysis to show the model robustness can be improved by the single-step adversarial training with sampled subnetworks. Furthermore, we propose a novel sampling strategy where the sampling varies from layer to layer and from iteration to iteration. Compared with previous methods, our method not only reduces the training cost but also achieves better model robustness. Evaluations on a series of popular datasets demonstrate the effectiveness of the proposed FB-Better. Our code has been released at https://github.com/jiaxiaojunQAQ/FP-Better.
Point2Mask: Point-supervised Panoptic Segmentation via Optimal Transport
Aug 03, 2023



Weakly-supervised image segmentation has recently attracted increasing research attentions, aiming to avoid the expensive pixel-wise labeling. In this paper, we present an effective method, namely Point2Mask, to achieve high-quality panoptic prediction using only a single random point annotation per target for training. Specifically, we formulate the panoptic pseudo-mask generation as an Optimal Transport (OT) problem, where each ground-truth (gt) point label and pixel sample are defined as the label supplier and consumer, respectively. The transportation cost is calculated by the introduced task-oriented maps, which focus on the category-wise and instance-wise differences among the various thing and stuff targets. Furthermore, a centroid-based scheme is proposed to set the accurate unit number for each gt point supplier. Hence, the pseudo-mask generation is converted into finding the optimal transport plan at a globally minimal transportation cost, which can be solved via the Sinkhorn-Knopp Iteration. Experimental results on Pascal VOC and COCO demonstrate the promising performance of our proposed Point2Mask approach to point-supervised panoptic segmentation. Source code is available at: https://github.com/LiWentomng/Point2Mask.