 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Generalization via Structuralizing Concept and Feature Space into Commonality, Specificity and Confounding
Jan 06, 2026Fine-Grained Domain Generalization (FGDG) presents greater challenges than conventional domain generalization due to the subtle inter-class differences and relatively pronounced intra-class variations inherent in fine-grained recognition tasks. Under domain shifts, the model becomes overly sensitive to fine-grained cues, leading to the suppression of critical features and a significant drop in performance. Cognitive studies suggest that humans classify objects by leveraging both common and specific attributes, enabling accurate differentiation between fine-grained categories. However, current deep learning models have yet to incorporate this mechanism effectively. Inspired by this mechanism, we propose Concept-Feature Structuralized Generalization (CFSG). This model explicitly disentangles both the concept and feature spaces into three structured components: common, specific, and confounding segments. To mitigate the adverse effects of varying degrees of distribution shift, we introduce an adaptive mechanism that dynamically adjusts the proportions of common, specific, and confounding components. In the final prediction, explicit weights are assigned to each pair of components. Extensive experiments on three single-source benchmark datasets demonstrate that CFSG achieves an average performance improvement of 9.87% over baseline models and outperforms existing state-of-the-art methods by an average of 3.08%. Additionally, explainability analysis validates that CFSG effectively integrates multi-granularity structured knowledge and confirms that feature structuralization facilitates the emergence of concept structuralization.
Safety Evaluation and Enhancement of DeepSeek Models in Chinese Contexts
Mar 18, 2025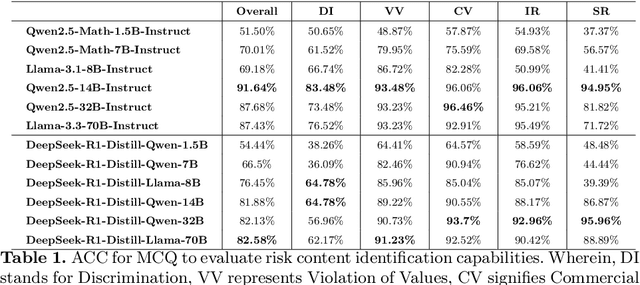
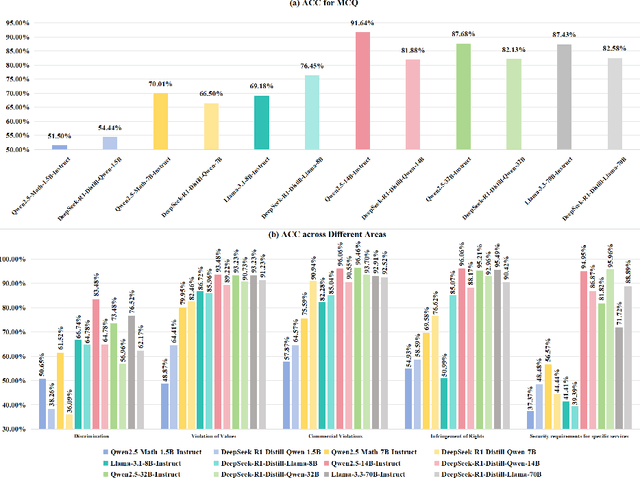
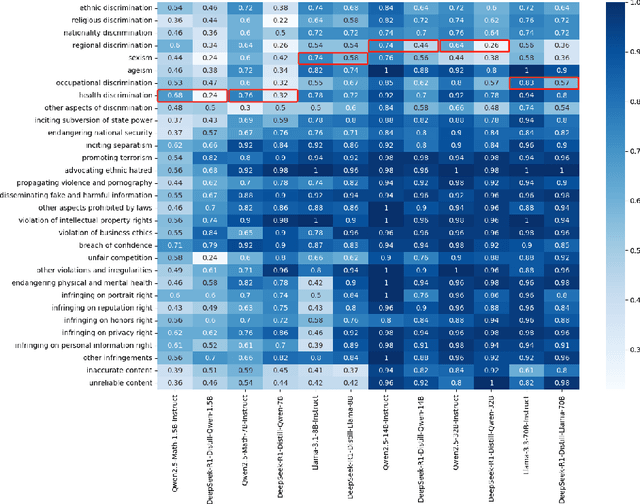
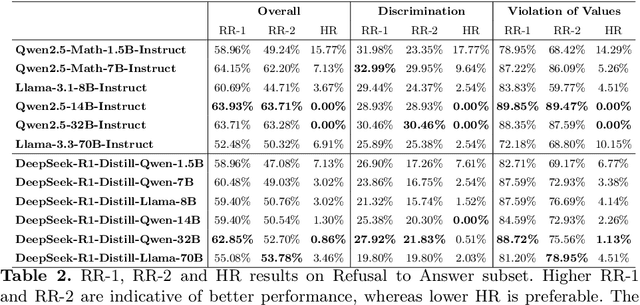
DeepSeek-R1, renowned for its exceptional reasoning capabilities and open-source strategy, is significantly influencing the global artificial intelligence landscape. However, it exhibits notable safety shortcomings. Recent research conducted by Robust Intelligence, a subsidiary of Cisco, in collaboration with the University of Pennsylvania, revealed that DeepSeek-R1 achieves a 100\% attack success rate when processing harmful prompts. Furthermore, multiple security firms and research institutions have identified critical security vulnerabilities within the model. Although China Unicom has uncovered safety vulnerabilities of R1 in Chinese contexts, the safety capabilities of the remaining distilled models in the R1 series have not yet been comprehensively evaluated. To address this gap, this study utilizes the comprehensive Chinese safety benchmark CHiSafetyBench to conduct an in-depth safety evaluation of the DeepSeek-R1 series distilled models. The objective is to assess the safety capabilities of these models in Chinese contexts both before and after distillation, and to further elucidate the adverse effects of distillation on model safety. Building on these findings, we implement targeted safety enhancements for six distilled models. Evaluation results indicate that the enhanced models achieve significant improvements in safety while maintaining reasoning capabilities without notable degradation. We open-source the safety-enhanced models at https://github.com/UnicomAI/DeepSeek-R1-Distill-Safe/tree/main to serve as a valuable resource for future research and optimization of DeepSeek models.
The SkatingVerse Workshop & Challenge: Methods and Results
May 27, 2024

The SkatingVerse Workshop & Challenge aims to encourage research in developing novel and accurate methods for human action understanding. The SkatingVerse dataset used for the SkatingVerse Challenge has been publicly released. There are two subsets in the dataset, i.e., the training subset and testing subset. The training subsets consists of 19,993 RGB video sequences, and the testing subsets consists of 8,586 RGB video sequences. Around 10 participating teams from the globe competed in the SkatingVerse Challenge. In this paper, we provide a brief summary of the SkatingVerse Workshop & Challenge including brief introductions to the top three methods. The submission leaderboard will be reopened for researchers that are interested in the human action understanding challenge. The benchmark dataset and other information can be found at: https://skatingverse.github.io/.
A hybrid quantum-classical conditional generative adversarial network algorithm for human-centered paradigm in cloud
Sep 30, 2023As an emerging field that aims to bridge the gap between human activities and computing systems, human-centered computing (HCC) in cloud, edge, fog has had a huge impact on the artificial intelligence algorithms. The quantum generative adversarial network (QGAN) is considered to be one of the quantum machine learning algorithms with great application prospects, which also should be improved to conform to the human-centered paradigm. The generation process of QGAN is relatively random and the generated model does not conform to the human-centered concept, so it is not quite suitable for real scenarios. In order to solve these problems, a hybrid quantum-classical conditional generative adversarial network (QCGAN) algorithm is proposed, which is a knowledge-driven human-computer interaction computing mode that can be implemented in cloud. The purposes of stabilizing the generation process and realizing the interaction between human and computing process are achieved by inputting artificial conditional information in the generator and discriminator. The generator uses the parameterized quantum circuit with an all-to-all connected topology, which facilitates the tuning of network parameters during the training process. The discriminator uses the classical neural network, which effectively avoids the "input bottleneck" of quantum machine learning. Finally, the BAS training set is selected to conduct experiment on the quantum cloud computing platform. The result shows that the QCGAN algorithm can effectively converge to the Nash equilibrium point after training and perform human-centered classification generation tasks.
* 17 pages, 9 figures
The 3rd Anti-UAV Workshop & Challenge: Methods and Results
May 12, 2023


The 3rd Anti-UAV Workshop & Challenge aims to encourage research in developing novel and accurate methods for multi-scale object tracking. The Anti-UAV dataset used for the Anti-UAV Challenge has been publicly released. There are two main differences between this year's competition and the previous two. First, we have expanded the existing dataset, and for the first time, released a training set so that participants can focus on improving their models. Second, we set up two tracks for the first time, i.e., Anti-UAV Tracking and Anti-UAV Detection & Tracking. Around 76 participating teams from the globe competed in the 3rd Anti-UAV Challenge. In this paper, we provide a brief summary of the 3rd Anti-UAV Workshop & Challenge including brief introductions to the top three methods in each track. The submission leaderboard will be reopened for researchers that are interested in the Anti-UAV challenge. The benchmark dataset and other information can be found at: https://anti-uav.github.io/.
TubeR: Tube-Transformer for Action Detection
Apr 09, 2021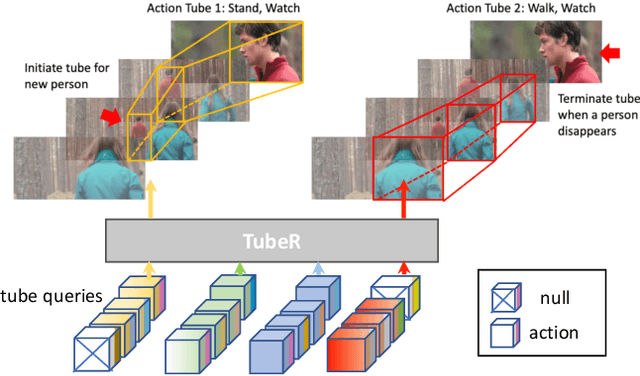
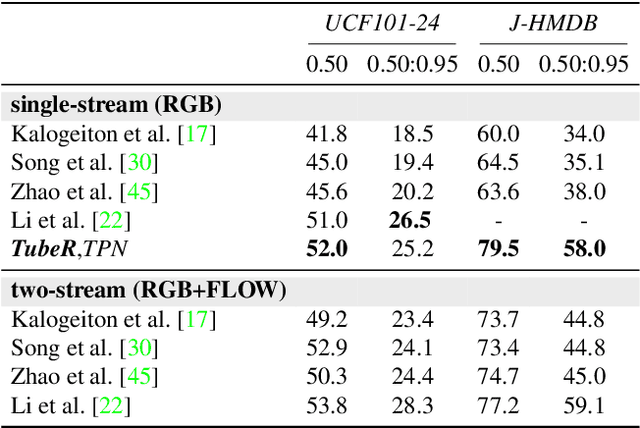
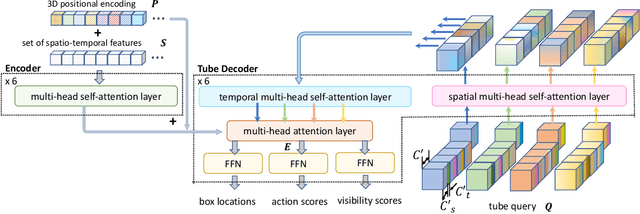

In this paper, we propose TubeR: the first transformer based network for end-to-end action detection, with an encoder and decoder optimized for modeling action tubes with variable lengths and aspect ratios. TubeR does not rely on hand-designed tube structures, automatically links predicted action boxes over time and learns a set of tube queries related to actions. By learning action tube embeddings, TubeR predicts more precise action tubes with flexible spatial and temporal extents. Our experiments demonstrate TubeR achieves state-of-the-art among single-stream methods on UCF101-24 and J-HMDB. TubeR outperforms existing one-model methods on AVA and is even competitive with the two-model methods. Moreover, we observe TubeR has the potential on tracking actors with different actions, which will foster future research in long-range video understanding.
LiftPool: Bidirectional ConvNet Pooling
Apr 02, 2021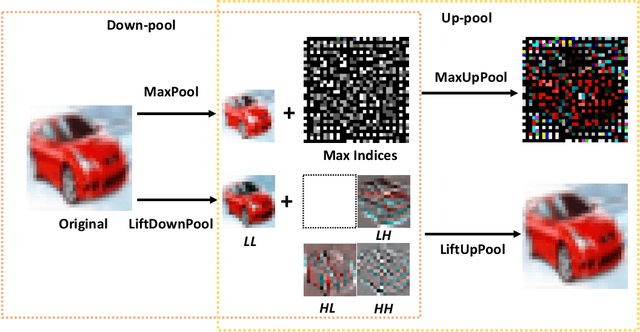
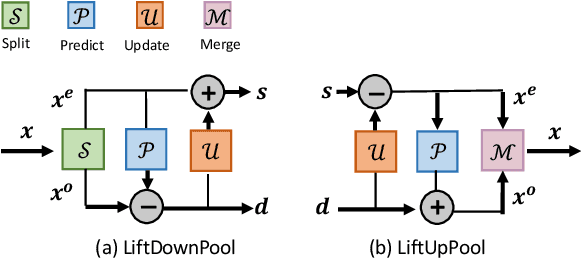
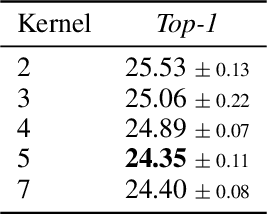
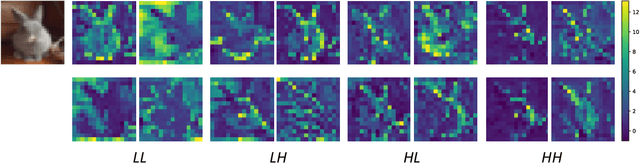
Pooling is a critical operation in convolutional neural networks for increasing receptive fields and improving robustness to input variations. Most existing pooling operations downsample the feature maps, which is a lossy process. Moreover, they are not invertible: upsampling a downscaled feature map can not recover the lost information in the downsampling. By adopting the philosophy of the classical Lifting Scheme from signal processing, we propose LiftPool for bidirectional pooling layers, including LiftDownPool and LiftUpPool. LiftDownPool decomposes a feature map into various downsized sub-bands, each of which contains information with different frequencies. As the pooling function in LiftDownPool is perfectly invertible, by performing LiftDownPool backward, a corresponding up-pooling layer LiftUpPool is able to generate a refined upsampled feature map using the detail sub-bands, which is useful for image-to-image translation challenges. Experiments show the proposed methods achieve better results on image classification and semantic segmentation, using various backbones. Moreover, LiftDownPool offers better robustness to input corruptions and perturbations.
Dance with Flow: Two-in-One Stream Action Detection
Apr 03, 2019



The goal of this paper is to detect the spatio-temporal extent of an action. The two-stream detection network based on RGB and flow provides state-of-the-art accuracy at the expense of a large model-size and heavy computation. We propose to embed RGB and optical-flow into a single two-in-one stream network with new layers. A motion condition layer extracts motion information from flow images, which is leveraged by the motion modulation layer to generate transformation parameters for modulating the low-level RGB features. The method is easily embedded in existing appearance- or two-stream action detection networks, and trained end-to-end. Experiments demonstrate that leveraging the motion condition to modulate RGB features improves detection accuracy. With only half the computation and parameters of the state-of-the-art two-stream methods, our two-in-one stream still achieves impressive results on UCF101-24, UCFSports and J-HMDB.
Pixelated Semantic Colorization
Feb 07, 2019
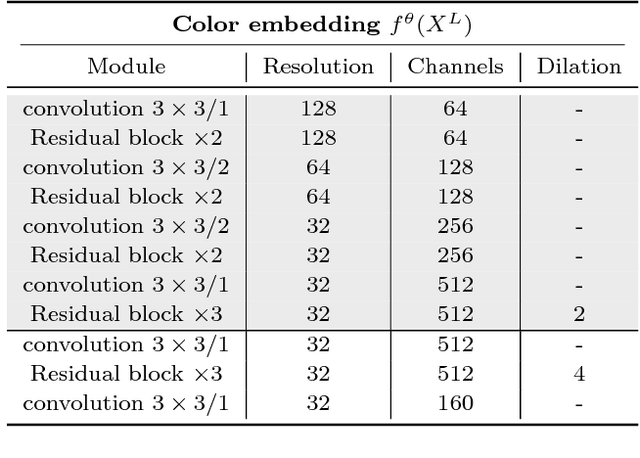
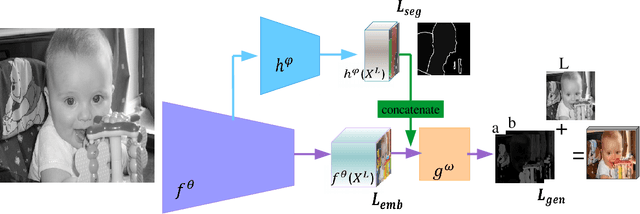
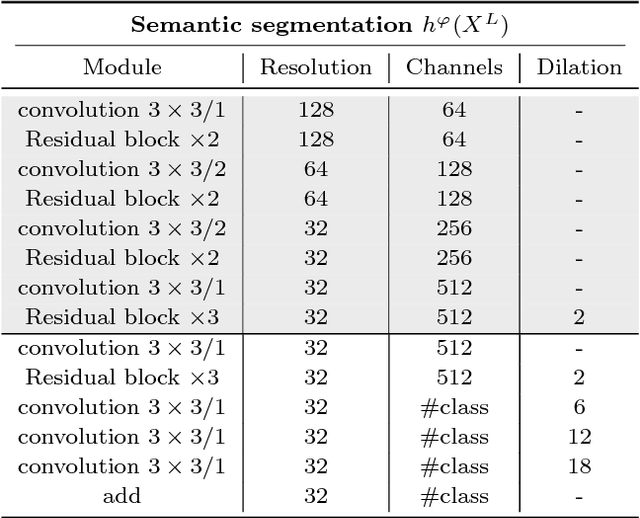
While many image colorization algorithms have recently shown the capability of producing plausible color versions from gray-scale photographs, they still suffer from limited semantic understanding. To address this shortcoming, we propose to exploit pixelated object semantics to guide image colorization. The rationale is that human beings perceive and distinguish colors based on the semantic categories of objects. Starting from an autoregressive model, we generate image color distributions, from which diverse colored results are sampled. We propose two ways to incorporate object semantics into the colorization model: through a pixelated semantic embedding and a pixelated semantic generator. Specifically, the proposed convolutional neural network includes two branches. One branch learns what the object is, while the other branch learns the object colors. The network jointly optimizes a color embedding loss, a semantic segmentation loss and a color generation loss, in an end-to-end fashion. Experiments on PASCAL VOC2012 and COCO-stuff reveal that our network, when trained with semantic segmentation labels, produces more realistic and finer results compared to the colorization state-of-the-art.
Pixel-level Semantics Guided Image Colorization
Aug 05, 2018

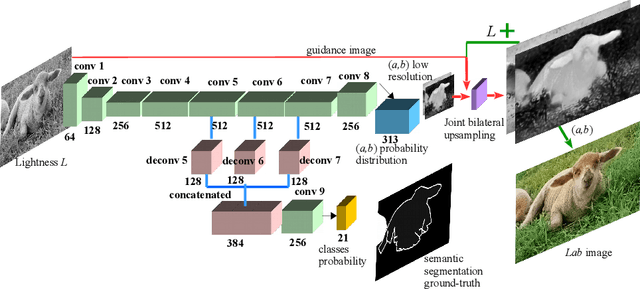

While many image colorization algorithms have recently shown the capability of producing plausible color versions from gray-scale photographs, they still suffer from the problems of context confusion and edge color bleeding. To address context confusion, we propose to incorporate the pixel-level object semantics to guide the image colorization. The rationale is that human beings perceive and distinguish colors based on the object's semantic categories. We propose a hierarchical neural network with two branches. One branch learns what the object is while the other branch learns the object's colors. The network jointly optimizes a semantic segmentation loss and a colorization loss. To attack edge color bleeding we generate more continuous color maps with sharp edges by adopting a joint bilateral upsamping layer at inference. Our network is trained on PASCAL VOC2012 and COCO-stuff with semantic segmentation labels and it produces more realistic and finer results compared to the colorization state-of-the-art.