 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphiContact: Pose-aware Human-Scene Robust Contact Perception for Interactive Systems
Mar 19, 2026Monocular vertex-level human-scene contact prediction is a fundamental capability for interactive systems such as assistive monitoring, embodied AI, and rehabilitation analysis. In this work, we study this task jointly with single-image 3D human mesh reconstruction, using reconstructed body geometry as a scaffold for contact reasoning. Existing approaches either focus on contact prediction without sufficiently exploiting explicit 3D human priors, or emphasize pose/mesh reconstruction without directly optimizing robust vertex-level contact inference under occlusion and perceptual noise. To address this gap, we propose GraphiContact, a pose-aware framework that transfers complementary human priors from two pretrained Transformer encoders and predicts per-vertex human-scene contact on the reconstructed mesh. To improve robustness in real-world scenarios, we further introduce a Single-Image Multi-Infer Uncertainty (SIMU) training strategy with token-level adaptive routing, which simulates occlusion and noisy observations during training while preserving efficient single-branch inference at test time. Experiments on five benchmark datasets show that GraphiContact achieves consistent gains on both contact prediction and 3D human reconstruction. Our code, based on the GraphiContact method, provides comprehensive 3D human reconstruction and interaction analysis, and will be publicly available at https://github.com/Aveiro-Lin/GraphiContact.
Distilling Latent Manifolds: Resolution Extrapolation by Variational Autoencoders
Mar 15, 2026Variational Autoencoder (VAE) encoders play a critical role in modern generative models, yet their computational cost often motivates the use of knowledge distillation or quantification to obtain compact alternatives. Existing studies typically believe that the model work better on the samples closed to their training data distribution than unseen data distribution. In this work, we report a counter-intuitive phenomenon in VAE encoder distillation: a compact encoder distilled only at low resolutions exhibits poor reconstruction performance at its native resolution, but achieves dramatically improved results when evaluated at higher, unseen input resolutions. Despite never being trained beyond $256^2$ resolution, the distilled encoder generalizes effectively to $512^2$ resolution inputs, partially inheriting the teacher model's resolution preference.We further analyze latent distributions across resolutions and find that higher-resolution inputs produce latent representations more closely aligned with the teacher's manifold. Through extensive experiments on ImageNet-256, we show that simple resolution remapping-upsampling inputs before encoding and downsampling reconstructions for evaluation-leads to substantial gains across PSNR, MSE, SSIM, LPIPS, and rFID metrics. These findings suggest that VAE encoder distillation learns resolution-consistent latent manifolds rather than resolution-specific pixel mappings. This also means that the high training cost on memory, time and high-resolution datasets are not necessary conditions for distilling a VAE with high-resolution image reconstruction capabilities. On low resolution datasets, the distillation model still could learn the detailed knowledge of the teacher model in high-resolution image reconstruction.
DemoTuner: Efficient DBMS Knobs Tuning via LLM-Assisted Demonstration Reinforcement Learning
Nov 13, 2025The performance of modern DBMSs such as MySQL and PostgreSQL heavily depends on the configuration of performance-critical knobs. Manual tuning these knobs is laborious and inefficient due to the complex and high-dimensional nature of the configuration space. Among the automated tuning methods, reinforcement learning (RL)-based methods have recently sought to improve the DBMS knobs tuning process from several different perspectives. However, they still encounter challenges with slow convergence speed during offline training. In this paper, we mainly focus on how to leverage the valuable tuning hints contained in various textual documents such as DBMS manuals and web forums to improve the offline training of RL-based methods. To this end, we propose an efficient DBMS knobs tuning framework named DemoTuner via a novel LLM-assisted demonstration reinforcement learning method. Specifically, to comprehensively and accurately mine tuning hints from documents, we design a structured chain of thought prompt to employ LLMs to conduct a condition-aware tuning hints extraction task. To effectively integrate the mined tuning hints into RL agent training, we propose a hint-aware demonstration reinforcement learning algorithm HA-DDPGfD in DemoTuner. As far as we know, DemoTuner is the first work to introduce the demonstration reinforcement learning algorithm for DBMS knobs tuning. Experimental evaluations conducted on MySQL and PostgreSQL across various workloads demonstrate the significant advantages of DemoTuner in both performance improvement and online tuning cost reduction over three representative baselines including DB-BERT, GPTuner and CDBTune. Additionally, DemoTuner also exhibits superior adaptability to application scenarios with unknown workloads.
ERF-BA-TFD+: A Multimodal Model for Audio-Visual Deepfake Detection
Aug 24, 2025



Deepfake detection is a critical task in identifying manipulated multimedia content. In real-world scenarios, deepfake content can manifest across multiple modalities, including audio and video. To address this challenge, we present ERF-BA-TFD+, a novel multimodal deepfake detection model that combines enhanced receptive field (ERF) and audio-visual fusion. Our model processes both audio and video features simultaneously, leveraging their complementary information to improve detection accuracy and robustness. The key innovation of ERF-BA-TFD+ lies in its ability to model long-range dependencies within the audio-visual input, allowing it to better capture subtle discrepancies between real and fake content. In our experiments, we evaluate ERF-BA-TFD+ on the DDL-AV dataset, which consists of both segmented and full-length video clips. Unlike previous benchmarks, which focused primarily on isolated segments, the DDL-AV dataset allows us to assess the model's performance in a more comprehensive and realistic setting. Our method achieves state-of-the-art results on this dataset, outperforming existing techniques in terms of both accuracy and processing speed. The ERF-BA-TFD+ model demonstrated its effectiveness in the "Workshop on Deepfake Detection, Localization, and Interpretability," Track 2: Audio-Visual Detection and Localization (DDL-AV), and won first place in this competition.
StickMotion: Generating 3D Human Motions by Drawing a Stickman
Mar 05, 2025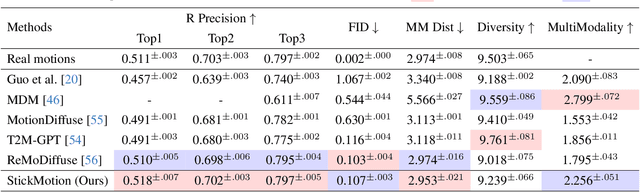
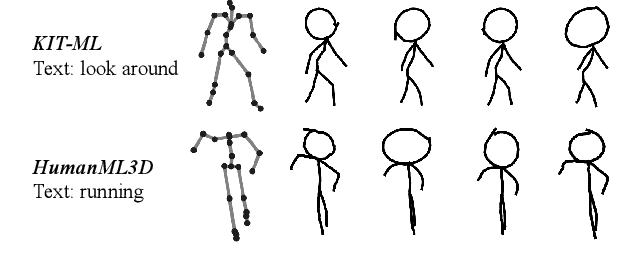
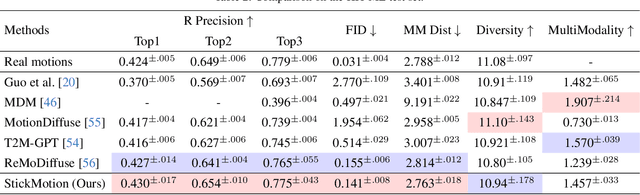
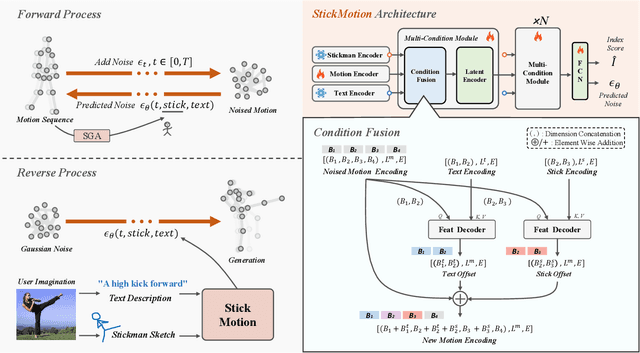
Text-to-motion generation, which translates textual descriptions into human motions, has been challenging in accurately capturing detailed user-imagined motions from simple text inputs. This paper introduces StickMotion, an efficient diffusion-based network designed for multi-condition scenarios, which generates desired motions based on traditional text and our proposed stickman conditions for global and local control of these motions, respectively. We address the challenges introduced by the user-friendly stickman from three perspectives: 1) Data generation. We develop an algorithm to generate hand-drawn stickmen automatically across different dataset formats. 2) Multi-condition fusion. We propose a multi-condition module that integrates into the diffusion process and obtains outputs of all possible condition combinations, reducing computational complexity and enhancing StickMotion's performance compared to conventional approaches with the self-attention module. 3) Dynamic supervision. We empower StickMotion to make minor adjustments to the stickman's position within the output sequences, generating more natural movements through our proposed dynamic supervision strategy. Through quantitative experiments and user studies, sketching stickmen saves users about 51.5% of their time generating motions consistent with their imagination. Our codes, demos, and relevant data will be released to facilitate further research and validation within the scientific community.
DiffBrush:Just Painting the Art by Your Hands
Feb 28, 2025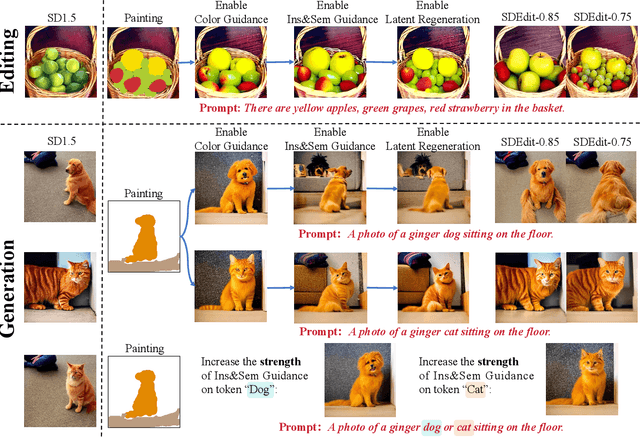
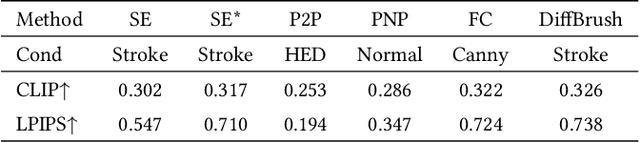
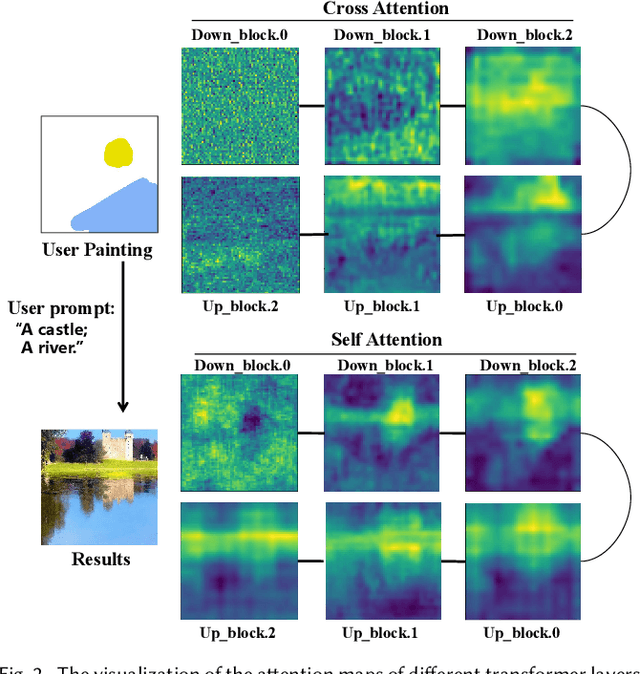
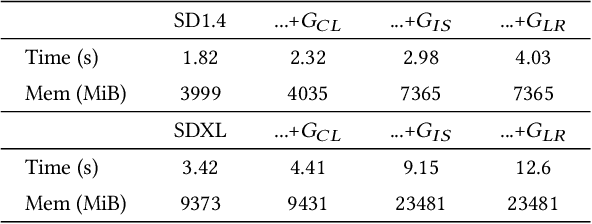
The rapid development of image generation and editing algorithms in recent years has enabled ordinary user to produce realistic images. However, the current AI painting ecosystem predominantly relies on text-driven diffusion models (T2I), which pose challenges in accurately capturing user requirements. Furthermore, achieving compatibility with other modalities incurs substantial training costs. To this end, we introduce DiffBrush, which is compatible with T2I models and allows users to draw and edit images. By manipulating and adapting the internal representation of the diffusion model, DiffBrush guides the model-generated images to converge towards the user's hand-drawn sketches for user's specific needs without additional training. DiffBrush achieves control over the color, semantic, and instance of objects in images by continuously guiding the latent and instance-level attention map during the denoising process of the diffusion model. Besides, we propose a latent regeneration, which refines the randomly sampled noise in the diffusion model, obtaining a better image generation layout. Finally, users only need to roughly draw the mask of the instance (acceptable colors) on the canvas, DiffBrush can naturally generate the corresponding instance at the corresponding location.
Adapting Vision Foundation Models for Robust Cloud Segmentation in Remote Sensing Images
Nov 20, 2024



Cloud segmentation is a critical challenge in remote sensing image interpretation, as its accuracy directly impacts the effectiveness of subsequent data processing and analysis. Recently, vision foundation models (VFM) have demonstrated powerful generalization capabilities across various visual tasks. In this paper, we present a parameter-efficient adaptive approach, termed Cloud-Adapter, designed to enhance the accuracy and robustness of cloud segmentation. Our method leverages a VFM pretrained on general domain data, which remains frozen, eliminating the need for additional training. Cloud-Adapter incorporates a lightweight spatial perception module that initially utilizes a convolutional neural network (ConvNet) to extract dense spatial representations. These multi-scale features are then aggregated and serve as contextual inputs to an adapting module, which modulates the frozen transformer layers within the VFM. Experimental results demonstrate that the Cloud-Adapter approach, utilizing only 0.6% of the trainable parameters of the frozen backbone, achieves substantial performance gains. Cloud-Adapter consistently attains state-of-the-art (SOTA) performance across a wide variety of cloud segmentation datasets from multiple satellite sources, sensor series, data processing levels, land cover scenarios, and annotation granularities. We have released the source code and pretrained models at https://github.com/XavierJiezou/Cloud-Adapter to support further research.
Autonomous Driving in Unstructured Environments: How Far Have We Come?
Oct 10, 2024

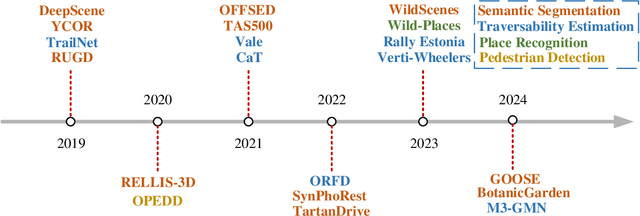

Research on autonomous driving in unstructured outdoor environments is less advanced than in structured urban settings due to challenges like environmental diversities and scene complexity. These environments-such as rural areas and rugged terrains-pose unique obstacles that are not common in structured urban areas. Despite these difficulties, autonomous driving in unstructured outdoor environments is crucial for applications in agriculture, mining, and military operations. Our survey reviews over 250 papers for autonomous driving in unstructured outdoor environments, covering offline mapping, pose estimation, environmental perception, path planning, end-to-end autonomous driving, datasets, and relevant challenges. We also discuss emerging trends and future research directions. This review aims to consolidate knowledge and encourage further research for autonomous driving in unstructured environments. To support ongoing work, we maintain an active repository with up-to-date literature and open-source projects at: https://github.com/chaytonmin/Survey-Autonomous-Driving-in-Unstructured-Environments.
A Multimodal Dangerous State Recognition and Early Warning System for Elderly with Intermittent Dementia
May 30, 2024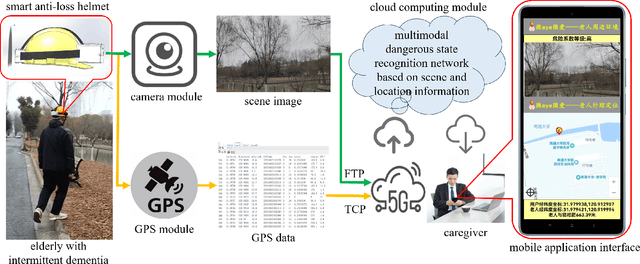
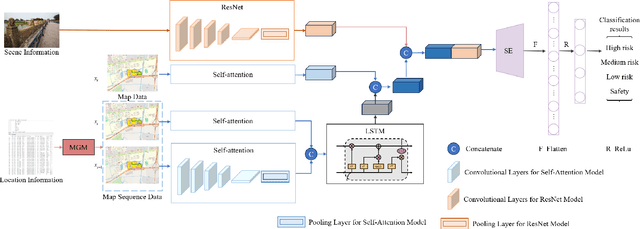
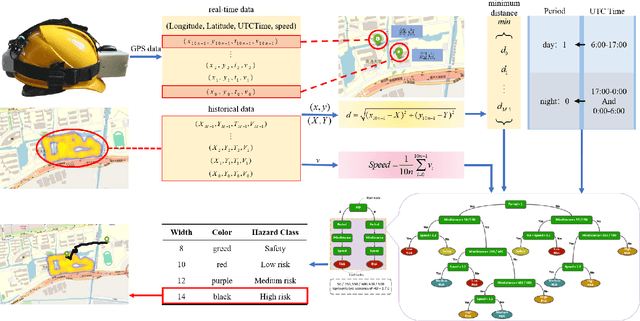
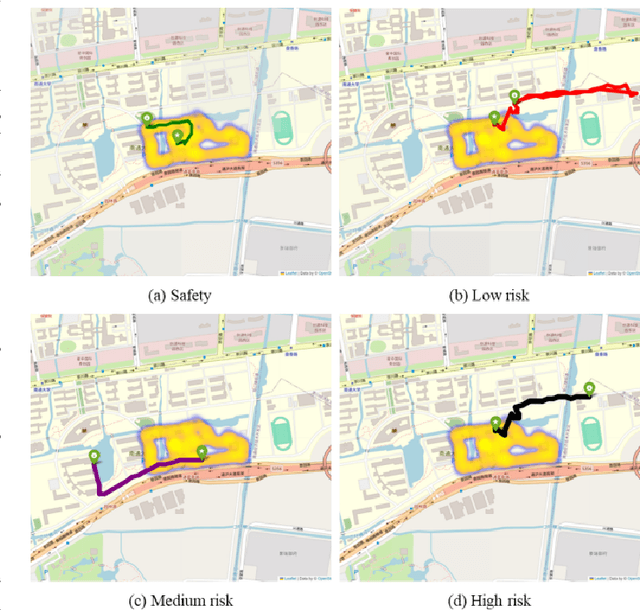
In response to the social issue of the increasing number of elderly vulnerable groups going missing due to the aggravating aging population in China, our team has developed a wearable anti-loss device and intelligent early warning system for elderly individuals with intermittent dementia using artificial intelligence and IoT technology. This system comprises an anti-loss smart helmet, a cloud computing module, and an intelligent early warning application on the caregiver's mobile device. The smart helmet integrates a miniature camera module, a GPS module, and a 5G communication module to collect first-person images and location information of the elderly. Data is transmitted remotely via 5G, FTP, and TCP protocols. In the cloud computing module, our team has proposed for the first time a multimodal dangerous state recognition network based on scene and location information to accurately assess the risk of elderly individuals going missing. Finally, the application software interface designed for the caregiver's mobile device implements multi-level early warnings. The system developed by our team requires no operation or response from the elderly, achieving fully automatic environmental perception, risk assessment, and proactive alarming. This overcomes the limitations of traditional monitoring devices, which require active operation and response, thus avoiding the issue of the digital divide for the elderly. It effectively prevents accidental loss and potential dangers for elderly individuals with dementia.
The SkatingVerse Workshop & Challenge: Methods and Results
May 27, 2024

The SkatingVerse Workshop & Challenge aims to encourage research in developing novel and accurate methods for human action understanding. The SkatingVerse dataset used for the SkatingVerse Challenge has been publicly released. There are two subsets in the dataset, i.e., the training subset and testing subset. The training subsets consists of 19,993 RGB video sequences, and the testing subsets consists of 8,586 RGB video sequences. Around 10 participating teams from the globe competed in the SkatingVerse Challenge. In this paper, we provide a brief summary of the SkatingVerse Workshop & Challenge including brief introductions to the top three methods. The submission leaderboard will be reopened for researchers that are interested in the human action understanding challenge. The benchmark dataset and other information can be found at: https://skatingverse.github.io/.