 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFMOcc: TPV-Driven Flow Matching for 3D Occupancy Prediction with Selective State Space Model
Jul 03, 2025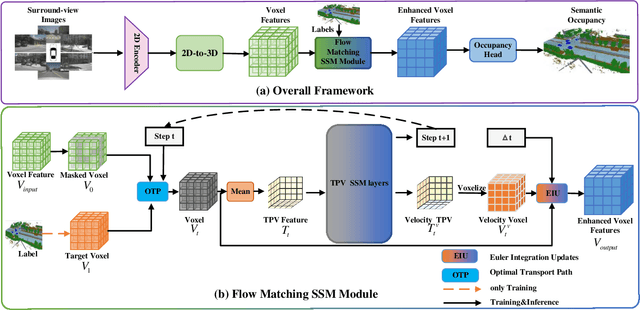
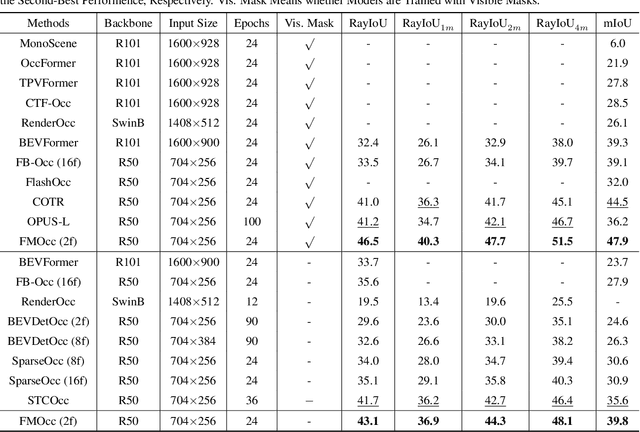
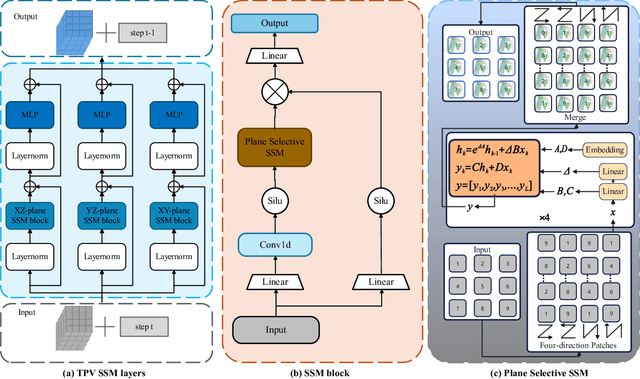

3D semantic occupancy prediction plays a pivotal role in autonomous driving. However, inherent limitations of fewframe images and redundancy in 3D space compromise prediction accuracy for occluded and distant scenes. Existing methods enhance performance by fusing historical frame data, which need additional data and significant computational resources. To address these issues, this paper propose FMOcc, a Tri-perspective View (TPV) refinement occupancy network with flow matching selective state space model for few-frame 3D occupancy prediction. Firstly, to generate missing features, we designed a feature refinement module based on a flow matching model, which is called Flow Matching SSM module (FMSSM). Furthermore, by designing the TPV SSM layer and Plane Selective SSM (PS3M), we selectively filter TPV features to reduce the impact of air voxels on non-air voxels, thereby enhancing the overall efficiency of the model and prediction capability for distant scenes. Finally, we design the Mask Training (MT) method to enhance the robustness of FMOcc and address the issue of sensor data loss. Experimental results on the Occ3D-nuScenes and OpenOcc datasets show that our FMOcc outperforms existing state-of-theart methods. Our FMOcc with two frame input achieves notable scores of 43.1% RayIoU and 39.8% mIoU on Occ3D-nuScenes validation, 42.6% RayIoU on OpenOcc with 5.4 G inference memory and 330ms inference time.
Unified Single-Stage Transformer Network for Efficient RGB-T Tracking
Aug 26, 2023



Most existing RGB-T tracking networks extract modality features in a separate manner, which lacks interaction and mutual guidance between modalities. This limits the network's ability to adapt to the diverse dual-modality appearances of targets and the dynamic relationships between the modalities. Additionally, the three-stage fusion tracking paradigm followed by these networks significantly restricts the tracking speed. To overcome these problems, we propose a unified single-stage Transformer RGB-T tracking network, namely USTrack, which unifies the above three stages into a single ViT (Vision Transformer) backbone with a dual embedding layer through self-attention mechanism. With this structure, the network can extract fusion features of the template and search region under the mutual interaction of modalities. Simultaneously, relation modeling is performed between these features, efficiently obtaining the search region fusion features with better target-background discriminability for prediction. Furthermore, we introduce a novel feature selection mechanism based on modality reliability to mitigate the influence of invalid modalities for prediction, further improving the tracking performance. Extensive experiments on three popular RGB-T tracking benchmarks demonstrate that our method achieves new state-of-the-art performance while maintaining the fastest inference speed 84.2FPS. In particular, MPR/MSR on the short-term and long-term subsets of VTUAV dataset increased by 11.1$\%$/11.7$\%$ and 11.3$\%$/9.7$\%$.
Non-exemplar Class-incremental Learning by Random Auxiliary Classes Augmentation and Mixed Features
Apr 16, 2023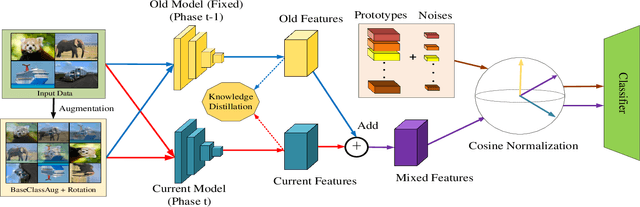
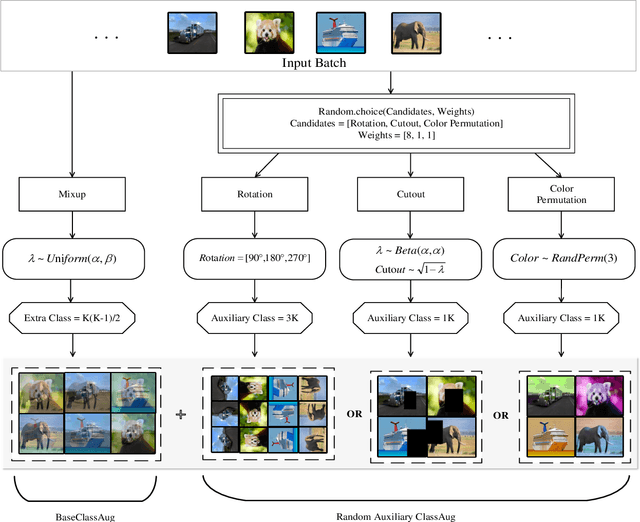
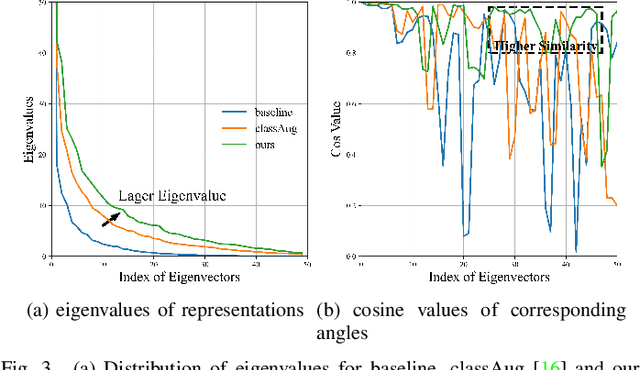
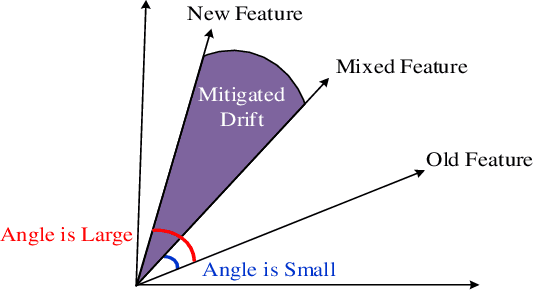
Non-exemplar class-incremental learning refers to classifying new and old classes without storing samples of old classes. Since only new class samples are available for optimization, it often occurs catastrophic forgetting of old knowledge. To alleviate this problem, many new methods are proposed such as model distillation, class augmentation. In this paper, we propose an effective non-exemplar method called RAMF consisting of Random Auxiliary classes augmentation and Mixed Feature. On the one hand, we design a novel random auxiliary classes augmentation method, where one augmentation is randomly selected from three augmentations and applied on the input to generate augmented samples and extra class labels. By extending data and label space, it allows the model to learn more diverse representations, which can prevent the model from being biased towards learning task-specific features. When learning new tasks, it will reduce the change of feature space and improve model generalization. On the other hand, we employ mixed feature to replace the new features since only using new feature to optimize the model will affect the representation that was previously embedded in the feature space. Instead, by mixing new and old features, old knowledge can be retained without increasing the computational complexity. Extensive experiments on three benchmarks demonstrate the superiority of our approach, which outperforms the state-of-the-art non-exemplar methods and is comparable to high-performance replay-based methods.
FPGA-based Acceleration System for Visual Tracking
Oct 15, 2018



Visual tracking is one of the most important application areas of computer vision. At present, most algorithms are mainly implemented on PCs, and it is difficult to ensure real-time performance when applied in the real scenario. In order to improve the tracking speed and reduce the overall power consumption of visual tracking, this paper proposes a real-time visual tracking algorithm based on DSST(Discriminative Scale Space Tracking) approach. We implement a hardware system on Xilinx XC7K325T FPGA platform based on our proposed visual tracking algorithm. Our hardware system can run at more than 153 frames per second. In order to reduce the resource occupation, our system adopts the batch processing method in the feature extraction module. In the filter processing module, the FFT IP core is time-division multiplexed. Therefore, our hardware system utilizes LUTs and storage blocks of 33% and 40%, respectively. Test results show that the proposed visual tracking hardware system has excellent performance.
High Performance Visual Tracking with Circular and Structural Operators
Oct 13, 2018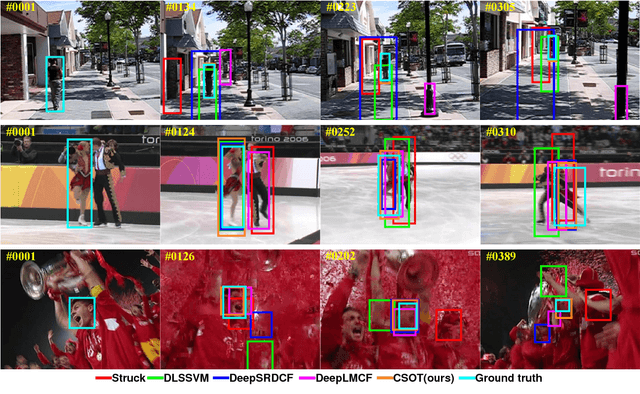

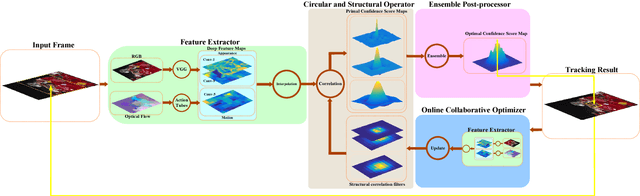

In this paper, a novel circular and structural operator tracker (CSOT) is proposed for high performance visual tracking, it not only possesses the powerful discriminative capability of SOSVM but also efficiently inherits the superior computational efficiency of DCF. Based on the proposed circular and structural operators, a set of primal confidence score maps can be obtained by circular correlating feature maps with their corresponding structural correlation filters. Furthermore, an implicit interpolation is applied to convert the multi-resolution feature maps to the continuous domain and make all primal confidence score maps have the same spatial resolution. Then, we exploit an efficient ensemble post-processor based on relative entropy, which can coalesce primal confidence score maps and create an optimal confidence score map for more accurate localization. The target is localized on the peak of the optimal confidence score map. Besides, we introduce a collaborative optimization strategy to update circular and structural operators by iteratively training structural correlation filters, which significantly reduces computational complexity and improves robustness. Experimental results demonstrate that our approach achieves state-of-the-art performance in mean AUC scores of 71.5% and 69.4% on the OTB-2013 and OTB-2015 benchmarks respectively, and obtains a third-best expected average overlap (EAO) score of 29.8% on the VOT-2017 benchmark.
A Complementary Tracking Model with Multiple Features
Jul 19, 2018Discriminative Correlation Filters based tracking algorithms exploiting conventional handcrafted features have achieved impressive results both in terms of accuracy and robustness. Template handcrafted features have shown excellent performance, but they perform poorly when the appearance of target changes rapidly such as fast motions and fast deformations. In contrast, statistical handcrafted features are insensitive to fast states changes, but they yield inferior performance in the scenarios of illumination variations and background clutters. In this work, to achieve an efficient tracking performance, we propose a novel visual tracking algorithm, named MFCMT, based on a complementary ensemble model with multiple features, including Histogram of Oriented Gradients (HOGs), Color Names (CNs) and Color Histograms (CHs). Additionally, to improve tracking results and prevent targets drift, we introduce an effective fusion method by exploiting relative entropy to coalesce all basic response maps and get an optimal response. Furthermore, we suggest a simple but efficient update strategy to boost tracking performance. Comprehensive evaluations are conducted on two tracking benchmarks demonstrate and the experimental results demonstrate that our method is competitive with numerous state-of-the-art trackers. Our tracker achieves impressive performance with faster speed on these benchmarks.
Large Margin Structured Convolution Operator for Thermal Infrared Object Tracking
Jul 19, 2018



Compared with visible object tracking, thermal infrared (TIR) object tracking can track an arbitrary target in total darkness since it cannot be influenced by illumination variations. However, there are many unwanted attributes that constrain the potentials of TIR tracking, such as the absence of visual color patterns and low resolutions. Recently, structured output support vector machine (SOSVM) and discriminative correlation filter (DCF) have been successfully applied to visible object tracking, respectively. Motivated by these, in this paper, we propose a large margin structured convolution operator (LMSCO) to achieve efficient TIR object tracking. To improve the tracking performance, we employ the spatial regularization and implicit interpolation to obtain continuous deep feature maps, including deep appearance features and deep motion features, of the TIR targets. Finally, a collaborative optimization strategy is exploited to significantly update the operators. Our approach not only inherits the advantage of the strong discriminative capability of SOSVM but also achieves accurate and robust tracking with higher-dimensional features and more dense samples. To the best of our knowledge, we are the first to incorporate the advantages of DCF and SOSVM for TIR object tracking. Comprehensive evaluations on two thermal infrared tracking benchmarks, i.e. VOT-TIR2015 and VOT-TIR2016, clearly demonstrate that our LMSCO tracker achieves impressive results and outperforms most state-of-the-art trackers in terms of accuracy and robustness with sufficient frame rate.