 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTackling the Dynamicity in a Production LLM Serving System with SOTA Optimizations via Hybrid Prefill/Decode/Verify Scheduling on Efficient Meta-kernels
Dec 24, 2024



Meeting growing demands for low latency and cost efficiency in production-grade large language model (LLM) serving systems requires integrating advanced optimization techniques. However, dynamic and unpredictable input-output lengths of LLM, compounded by these optimizations, exacerbate the issues of workload variability, making it difficult to maintain high efficiency on AI accelerators, especially DSAs with tile-based programming models. To address this challenge, we introduce XY-Serve, a versatile, Ascend native, end-to-end production LLM-serving system. The core idea is an abstraction mechanism that smooths out the workload variability by decomposing computations into unified, hardware-friendly, fine-grained meta primitives. For attention, we propose a meta-kernel that computes the basic pattern of matmul-softmax-matmul with architectural-aware tile sizes. For GEMM, we introduce a virtual padding scheme that adapts to dynamic shape changes while using highly efficient GEMM primitives with assorted fixed tile sizes. XY-Serve sits harmoniously with vLLM. Experimental results show up to 89% end-to-end throughput improvement compared with current publicly available baselines on Ascend NPUs. Additionally, our approach outperforms existing GEMM (average 14.6% faster) and attention (average 21.5% faster) kernels relative to existing libraries. While the work is Ascend native, we believe the approach can be readily applicable to SIMT architectures as well.
P/D-Serve: Serving Disaggregated Large Language Model at Scale
Aug 15, 2024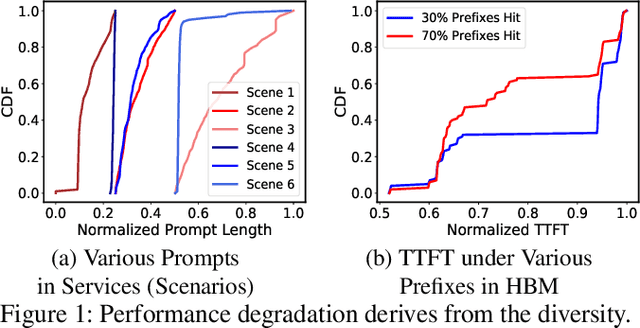
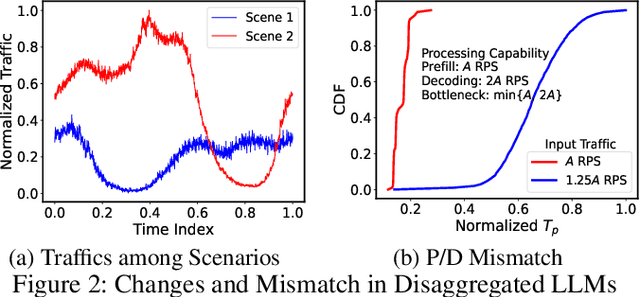
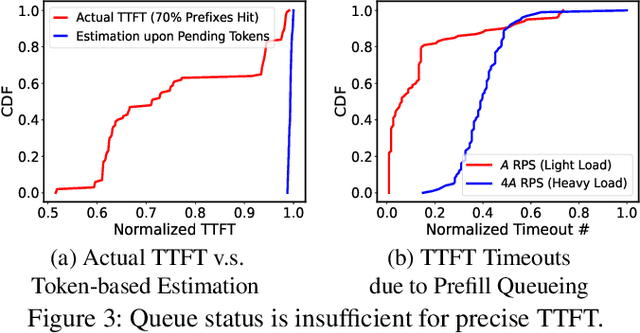
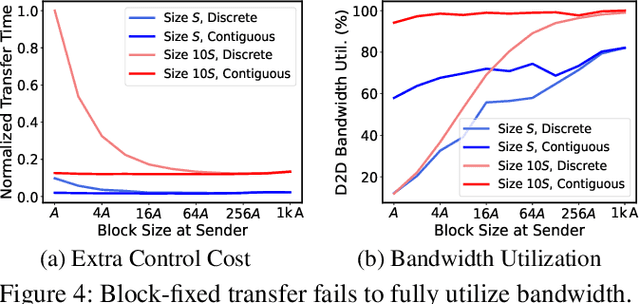
Serving disaggregated large language models (LLMs) over tens of thousands of xPU devices (GPUs or NPUs) with reliable performance faces multiple challenges. 1) Ignoring the diversity (various prefixes and tidal requests), treating all the prompts in a mixed pool is inadequate. To facilitate the similarity per scenario and minimize the inner mismatch on P/D (prefill and decoding) processing, fine-grained organization is required, dynamically adjusting P/D ratios for better performance. 2) Due to inaccurate estimation on workload (queue status or maintained connections), the global scheduler easily incurs unnecessary timeouts in prefill. 3) Block-fixed device-to-device (D2D) KVCache transfer over cluster-level RDMA (remote direct memory access) fails to achieve desired D2D utilization as expected. To overcome previous problems, this paper proposes an end-to-end system P/D-Serve, complying with the paradigm of MLOps (machine learning operations), which models end-to-end (E2E) P/D performance and enables: 1) fine-grained P/D organization, mapping the service with RoCE (RDMA over converged ethernet) as needed, to facilitate similar processing and dynamic adjustments on P/D ratios; 2) on-demand forwarding upon rejections for idle prefill, decoupling the scheduler from regular inaccurate reports and local queues, to avoid timeouts in prefill; and 3) efficient KVCache transfer via optimized D2D access. P/D-Serve is implemented upon Ascend and MindSpore, has been deployed over tens of thousands of NPUs for more than eight months in commercial use, and further achieves 60\%, 42\% and 46\% improvements on E2E throughput, time-to-first-token (TTFT) SLO (service level objective) and D2D transfer time. As the E2E system with optimizations, P/D-Serve achieves 6.7x increase on throughput, compared with aggregated LLMs.
Unlocking Data-free Low-bit Quantization with Matrix Decomposition for KV Cache Compression
May 21, 2024Key-value~(KV) caching is an important technique to accelerate the inference of large language models~(LLMs), but incurs significant memory overhead. To compress the size of KV cache, existing methods often compromise precision or require extra data for calibration, limiting their practicality in LLM deployment. In this paper, we introduce \textbf{DecoQuant}, a novel data-free low-bit quantization technique based on tensor decomposition methods, to effectively compress KV cache. Our core idea is to adjust the outlier distribution of the original matrix by performing tensor decomposition, so that the quantization difficulties are migrated from the matrix to decomposed local tensors. Specially, we find that outliers mainly concentrate on small local tensors, while large tensors tend to have a narrower value range. Based on this finding, we propose to apply low-bit quantization to the large tensor, while maintaining high-precision representation for the small tensor. Furthermore, we utilize the proposed quantization method to compress the KV cache of LLMs to accelerate the inference and develop an efficient dequantization kernel tailored specifically for DecoQuant. Through extensive experiments, DecoQuant demonstrates remarkable efficiency gains, showcasing up to a $\sim$75\% reduction in memory footprint while maintaining comparable generation quality.
Real-time Image Enhancer via Learnable Spatial-aware 3D Lookup Tables
Aug 19, 2021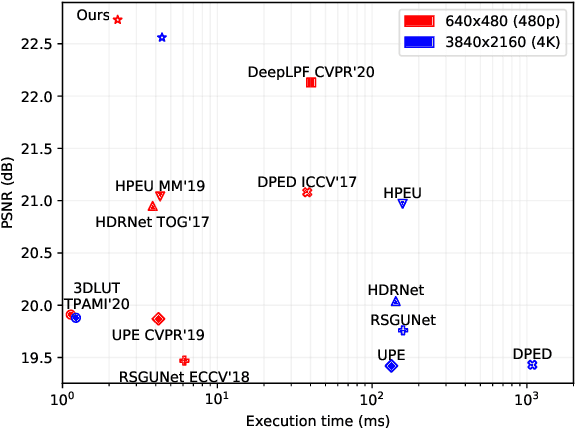
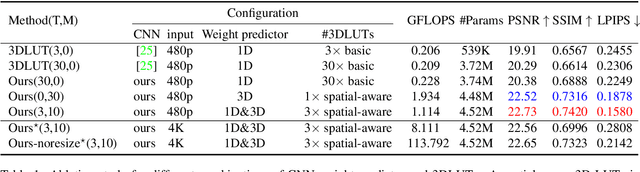
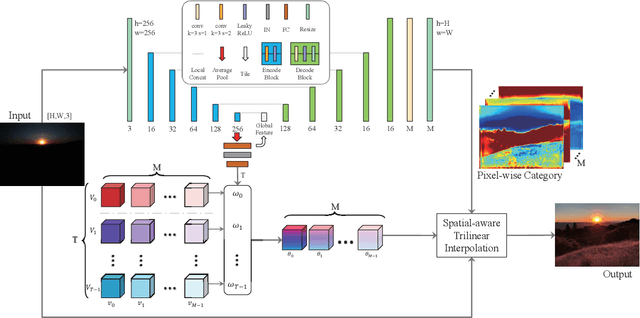
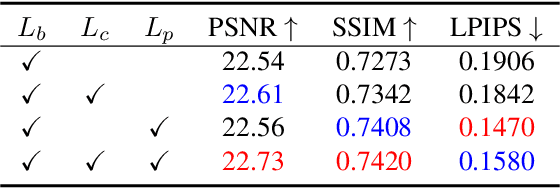
Recently, deep learning-based image enhancement algorithms achieved state-of-the-art (SOTA) performance on several publicly available datasets. However, most existing methods fail to meet practical requirements either for visual perception or for computation efficiency, especially for high-resolution images. In this paper, we propose a novel real-time image enhancer via learnable spatial-aware 3-dimentional lookup tables(3D LUTs), which well considers global scenario and local spatial information. Specifically, we introduce a light weight two-head weight predictor that has two outputs. One is a 1D weight vector used for image-level scenario adaptation, the other is a 3D weight map aimed for pixel-wise category fusion. We learn the spatial-aware 3D LUTs and fuse them according to the aforementioned weights in an end-to-end manner. The fused LUT is then used to transform the source image into the target tone in an efficient way. Extensive results show that our model outperforms SOTA image enhancement methods on public datasets both subjectively and objectively, and that our model only takes about 4ms to process a 4K resolution image on one NVIDIA V100 GPU.
Learned Smartphone ISP on Mobile NPUs with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021
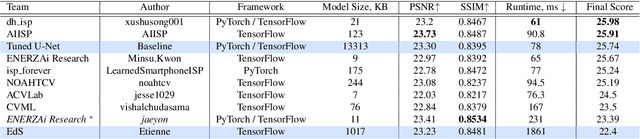
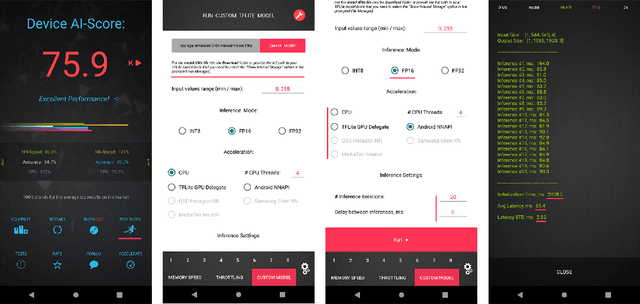
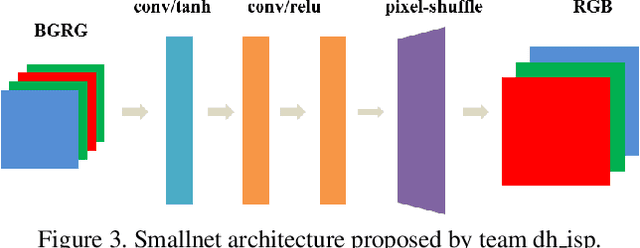
As the quality of mobile cameras starts to play a crucial role in modern smartphones, more and more attention is now being paid to ISP algorithms used to improve various perceptual aspects of mobile photos. In this Mobile AI challenge, the target was to develop an end-to-end deep learning-based image signal processing (ISP) pipeline that can replace classical hand-crafted ISPs and achieve nearly real-time performance on smartphone NPUs. For this, the participants were provided with a novel learned ISP dataset consisting of RAW-RGB image pairs captured with the Sony IMX586 Quad Bayer mobile sensor and a professional 102-megapixel medium format camera. The runtime of all models was evaluated on the MediaTek Dimensity 1000+ platform with a dedicated AI processing unit capable of accelerating both floating-point and quantized neural networks. The proposed solutions are fully compatible with the above NPU and are capable of processing Full HD photos under 60-100 milliseconds while achieving high fidelity results. A detailed description of all models developed in this challenge is provided in this paper.
Learning Cascaded Siamese Networks for High Performance Visual Tracking
May 08, 2019



Visual tracking is one of the most challenging computer vision problems. In order to achieve high performance visual tracking in various negative scenarios, a novel cascaded Siamese network is proposed and developed based on two different deep learning networks: a matching subnetwork and a classification subnetwork. The matching subnetwork is a fully convolutional Siamese network. According to the similarity score between the exemplar image and the candidate image, it aims to search possible object positions and crop scaled candidate patches. The classification subnetwork is designed to further evaluate the cropped candidate patches and determine the optimal tracking results based on the classification score. The matching subnetwork is trained offline and fixed online, while the classification subnetwork performs stochastic gradient descent online to learn more target-specific information. To improve the tracking performance further, an effective classification subnetwork update method based on both similarity and classification scores is utilized for updating the classification subnetwork. Extensive experimental results demonstrate that our proposed approach achieves state-of-the-art performance in recent benchmarks.
Siamese Attentional Keypoint Network for High Performance Visual Tracking
Apr 23, 2019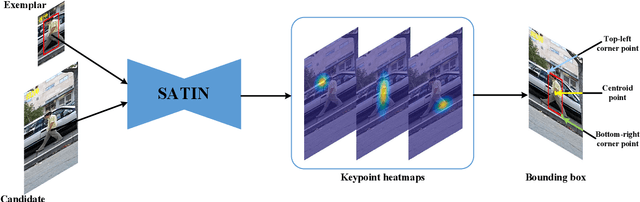
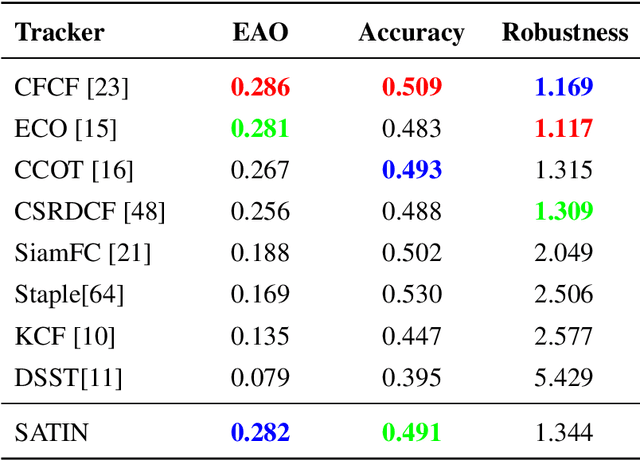
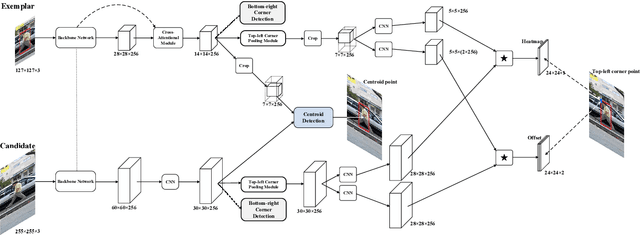
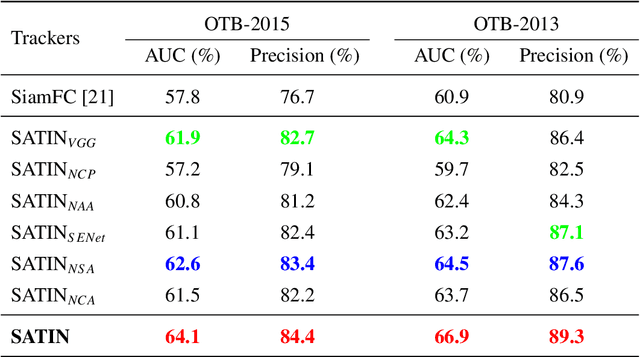
In this paper, we investigate impacts of three main aspects of visual tracking, i.e., the backbone network, the attentional mechanism and the detection component, and propose a Siamese Attentional Keypoint Network, dubbed SATIN, to achieve efficient tracking and accurate localization. Firstly, a new Siamese lightweight hourglass network is specifically designed for visual tracking. It takes advantage of the benefits of the repeated bottom-up and top-down inference to capture more global and local contextual information at multiple scales. Secondly, a novel cross-attentional module is utilized to leverage both channel-wise and spatial intermediate attentional information, which enhance both discriminative and localization capabilities of feature maps. Thirdly, a keypoints detection approach is invented to track any target object by detecting the top-left corner point, the centroid point and the bottom-right corner point of its bounding box. To the best of our knowledge, we are the first to propose this approach. Therefore, our SATIN tracker not only has a strong capability to learn more effective object representations, but also computational and memory storage efficiency, either during the training or testing stage. Without bells and whistles, experimental results demonstrate that our approach achieves state-of-the-art performance on several recent benchmark datasets, at speeds far exceeding the frame-rate requirement.
High Performance Visual Tracking with Circular and Structural Operators
Oct 13, 2018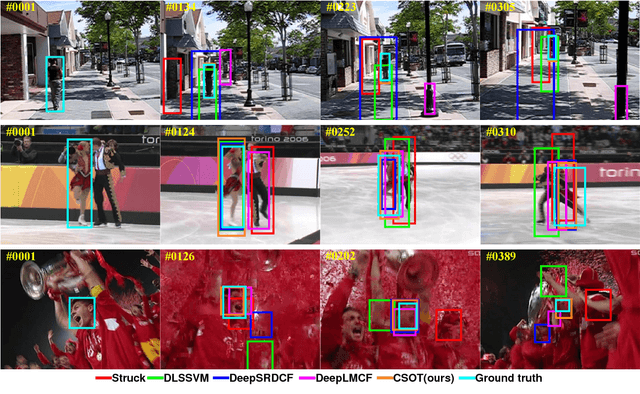

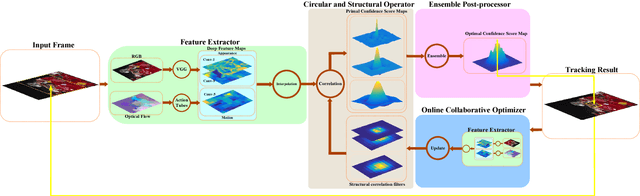

In this paper, a novel circular and structural operator tracker (CSOT) is proposed for high performance visual tracking, it not only possesses the powerful discriminative capability of SOSVM but also efficiently inherits the superior computational efficiency of DCF. Based on the proposed circular and structural operators, a set of primal confidence score maps can be obtained by circular correlating feature maps with their corresponding structural correlation filters. Furthermore, an implicit interpolation is applied to convert the multi-resolution feature maps to the continuous domain and make all primal confidence score maps have the same spatial resolution. Then, we exploit an efficient ensemble post-processor based on relative entropy, which can coalesce primal confidence score maps and create an optimal confidence score map for more accurate localization. The target is localized on the peak of the optimal confidence score map. Besides, we introduce a collaborative optimization strategy to update circular and structural operators by iteratively training structural correlation filters, which significantly reduces computational complexity and improves robustness. Experimental results demonstrate that our approach achieves state-of-the-art performance in mean AUC scores of 71.5% and 69.4% on the OTB-2013 and OTB-2015 benchmarks respectively, and obtains a third-best expected average overlap (EAO) score of 29.8% on the VOT-2017 benchmark.
Efficient Multi-level Correlating for Visual Tracking
Oct 13, 2018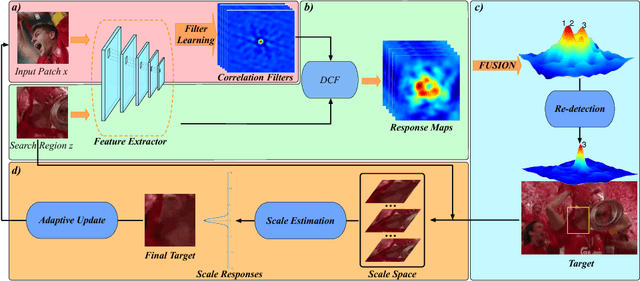
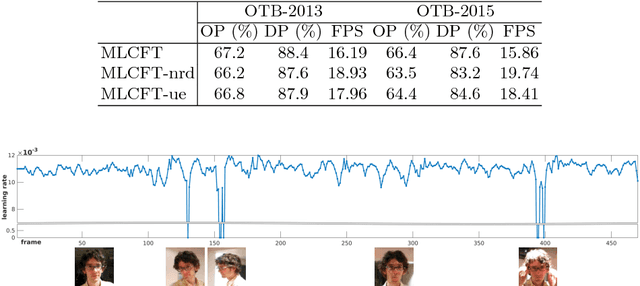
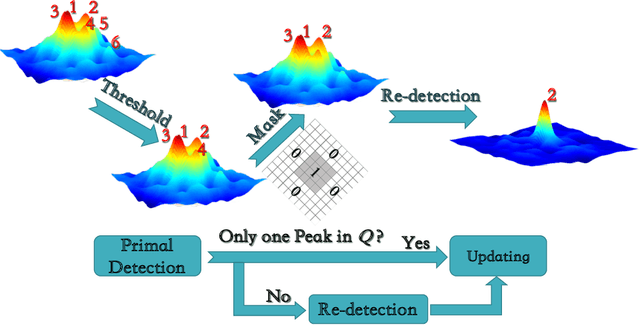
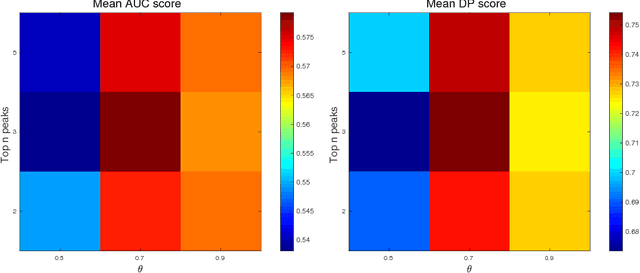
Correlation filter (CF) based tracking algorithms have demonstrated favorable performance recently. Nevertheless, the top performance trackers always employ complicated optimization methods which constraint their real-time applications. How to accelerate the tracking speed while retaining the tracking accuracy is a significant issue. In this paper, we propose a multi-level CF-based tracking approach named MLCFT which further explores the potential capacity of CF with two-stage detection: primal detection and oriented re-detection. The cascaded detection scheme is simple but competent to prevent model drift and accelerate the speed. An effective fusion method based on relative entropy is introduced to combine the complementary features extracted from deep and shallow layers of convolutional neural networks (CNN). Moreover, a novel online model update strategy is utilized in our tracker, which enhances the tracking performance further. Experimental results demonstrate that our proposed approach outperforms the most state-of-the-art trackers while tracking at speed of exceeded 16 frames per second on challenging benchmarks.
A Complementary Tracking Model with Multiple Features
Jul 19, 2018Discriminative Correlation Filters based tracking algorithms exploiting conventional handcrafted features have achieved impressive results both in terms of accuracy and robustness. Template handcrafted features have shown excellent performance, but they perform poorly when the appearance of target changes rapidly such as fast motions and fast deformations. In contrast, statistical handcrafted features are insensitive to fast states changes, but they yield inferior performance in the scenarios of illumination variations and background clutters. In this work, to achieve an efficient tracking performance, we propose a novel visual tracking algorithm, named MFCMT, based on a complementary ensemble model with multiple features, including Histogram of Oriented Gradients (HOGs), Color Names (CNs) and Color Histograms (CHs). Additionally, to improve tracking results and prevent targets drift, we introduce an effective fusion method by exploiting relative entropy to coalesce all basic response maps and get an optimal response. Furthermore, we suggest a simple but efficient update strategy to boost tracking performance. Comprehensive evaluations are conducted on two tracking benchmarks demonstrate and the experimental results demonstrate that our method is competitive with numerous state-of-the-art trackers. Our tracker achieves impressive performance with faster speed on these benchmarks.