 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Navigation with Embodied Intelligence: A Survey
Feb 22, 2024



As a long-term vision in the field of artificial intelligence, the core goal of embodied intelligence is to improve the perception, understanding, and interaction capabilities of agents and the environment. Vision-language navigation (VLN), as a critical research path to achieve embodied intelligence, focuses on exploring how agents use natural language to communicate effectively with humans, receive and understand instructions, and ultimately rely on visual information to achieve accurate navigation. VLN integrates artificial intelligence, natural language processing, computer vision, and robotics. This field faces technical challenges but shows potential for application such as human-computer interaction. However, due to the complex process involved from language understanding to action execution, VLN faces the problem of aligning visual information and language instructions, improving generalization ability, and many other challenges. This survey systematically reviews the research progress of VLN and details the research direction of VLN with embodied intelligence. After a detailed summary of its system architecture and research based on methods and commonly used benchmark datasets, we comprehensively analyze the problems and challenges faced by current research and explore the future development direction of this field, aiming to provide a practical reference for researchers.
Learning Cascaded Siamese Networks for High Performance Visual Tracking
May 08, 2019



Visual tracking is one of the most challenging computer vision problems. In order to achieve high performance visual tracking in various negative scenarios, a novel cascaded Siamese network is proposed and developed based on two different deep learning networks: a matching subnetwork and a classification subnetwork. The matching subnetwork is a fully convolutional Siamese network. According to the similarity score between the exemplar image and the candidate image, it aims to search possible object positions and crop scaled candidate patches. The classification subnetwork is designed to further evaluate the cropped candidate patches and determine the optimal tracking results based on the classification score. The matching subnetwork is trained offline and fixed online, while the classification subnetwork performs stochastic gradient descent online to learn more target-specific information. To improve the tracking performance further, an effective classification subnetwork update method based on both similarity and classification scores is utilized for updating the classification subnetwork. Extensive experimental results demonstrate that our proposed approach achieves state-of-the-art performance in recent benchmarks.
Siamese Attentional Keypoint Network for High Performance Visual Tracking
Apr 23, 2019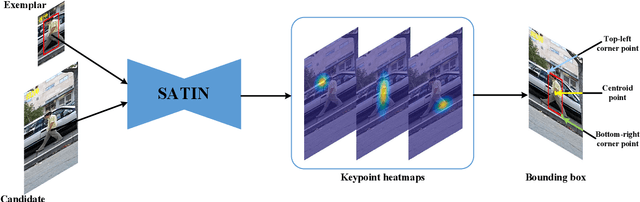
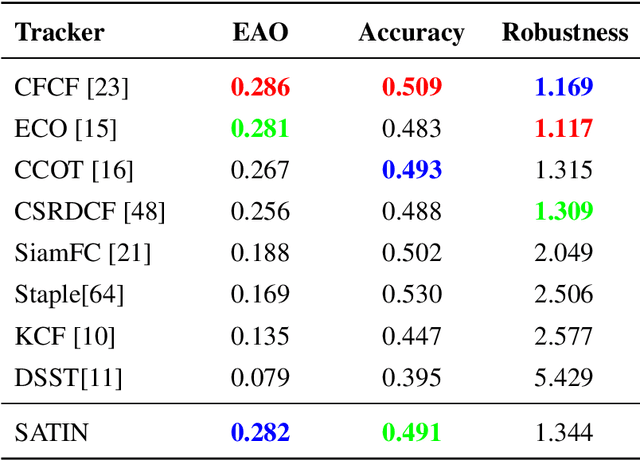
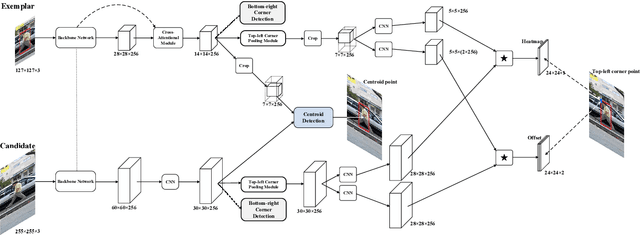
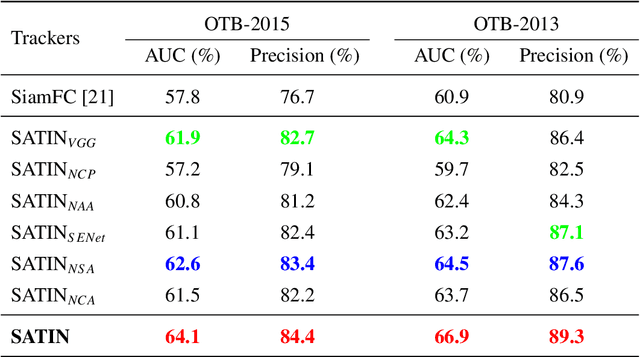
In this paper, we investigate impacts of three main aspects of visual tracking, i.e., the backbone network, the attentional mechanism and the detection component, and propose a Siamese Attentional Keypoint Network, dubbed SATIN, to achieve efficient tracking and accurate localization. Firstly, a new Siamese lightweight hourglass network is specifically designed for visual tracking. It takes advantage of the benefits of the repeated bottom-up and top-down inference to capture more global and local contextual information at multiple scales. Secondly, a novel cross-attentional module is utilized to leverage both channel-wise and spatial intermediate attentional information, which enhance both discriminative and localization capabilities of feature maps. Thirdly, a keypoints detection approach is invented to track any target object by detecting the top-left corner point, the centroid point and the bottom-right corner point of its bounding box. To the best of our knowledge, we are the first to propose this approach. Therefore, our SATIN tracker not only has a strong capability to learn more effective object representations, but also computational and memory storage efficiency, either during the training or testing stage. Without bells and whistles, experimental results demonstrate that our approach achieves state-of-the-art performance on several recent benchmark datasets, at speeds far exceeding the frame-rate requirement.
A Novel Low-cost FPGA-based Real-time Object Tracking System
Apr 22, 2018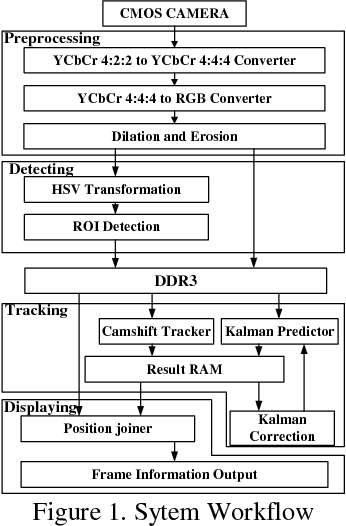
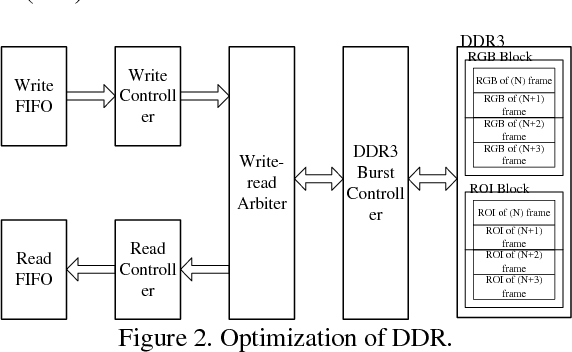
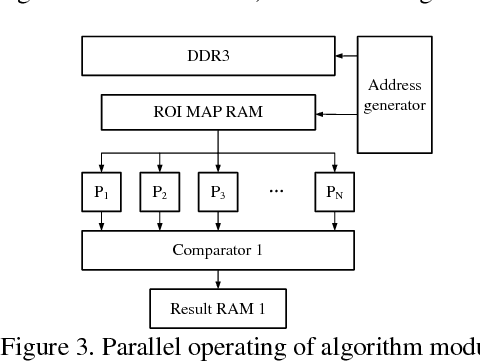

In current visual object tracking system, the CPU or GPU-based visual object tracking systems have high computational cost and consume a prohibitive amount of power. Therefore, in this paper, to reduce the computational burden of the Camshift algorithm, we propose a novel visual object tracking algorithm by exploiting the properties of the binary classifier and Kalman predictor. Moreover, we present a low-cost FPGA-based real-time object tracking hardware architecture. Extensive evaluations on OTB benchmark demonstrate that the proposed system has extremely compelling real-time, stability and robustness. The evaluation results show that the accuracy of our algorithm is about 48%, and the average speed is about 309 frames per second.