 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhononBench:A Large-Scale Phonon-Based Benchmark for Dynamical Stability in Crystal Generation
Dec 24, 2025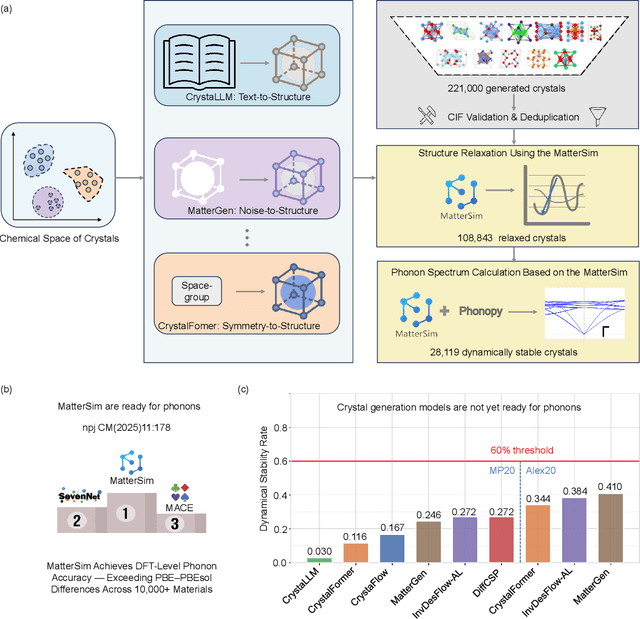
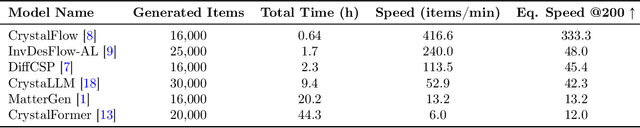
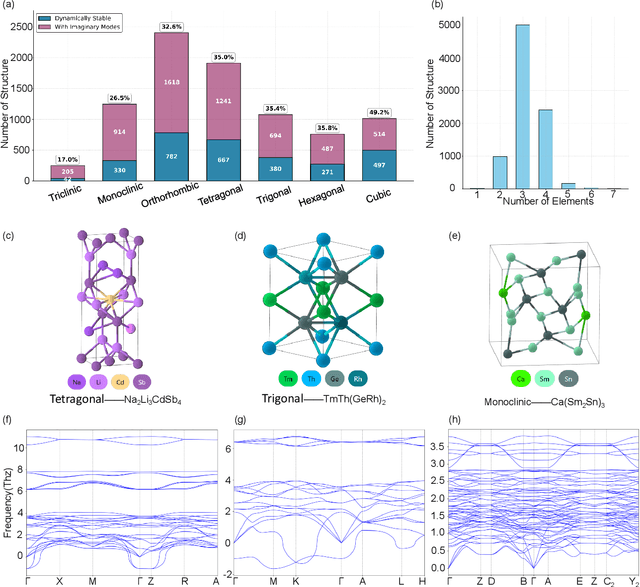
In this work, we introduce PhononBench, the first large-scale benchmark for dynamical stability in AI-generated crystals. Leveraging the recently developed MatterSim interatomic potential, which achieves DFT-level accuracy in phonon predictions across more than 10,000 materials, PhononBench enables efficient large-scale phonon calculations and dynamical-stability analysis for 108,843 crystal structures generated by six leading crystal generation models. PhononBench reveals a widespread limitation of current generative models in ensuring dynamical stability: the average dynamical-stability rate across all generated structures is only 25.83%, with the top-performing model, MatterGen, reaching just 41.0%. Further case studies show that in property-targeted generation-illustrated here by band-gap conditioning with MatterGen--the dynamical-stability rate remains as low as 23.5% even at the optimal band-gap condition of 0.5 eV. In space-group-controlled generation, higher-symmetry crystals exhibit better stability (e.g., cubic systems achieve rates up to 49.2%), yet the average stability across all controlled generations is still only 34.4%. An important additional outcome of this study is the identification of 28,119 crystal structures that are phonon-stable across the entire Brillouin zone, providing a substantial pool of reliable candidates for future materials exploration. By establishing the first large-scale dynamical-stability benchmark, this work systematically highlights the current limitations of crystal generation models and offers essential evaluation criteria and guidance for their future development toward the design and discovery of physically viable materials. All model-generated crystal structures, phonon calculation results, and the high-throughput evaluation workflows developed in PhononBench will be openly released at https://github.com/xqh19970407/PhononBench
HTSC-2025: A Benchmark Dataset of Ambient-Pressure High-Temperature Superconductors for AI-Driven Critical Temperature Prediction
Jun 04, 2025The discovery of high-temperature superconducting materials holds great significance for human industry and daily life. In recent years, research on predicting superconducting transition temperatures using artificial intelligence~(AI) has gained popularity, with most of these tools claiming to achieve remarkable accuracy. However, the lack of widely accepted benchmark datasets in this field has severely hindered fair comparisons between different AI algorithms and impeded further advancement of these methods. In this work, we present the HTSC-2025, an ambient-pressure high-temperature superconducting benchmark dataset. This comprehensive compilation encompasses theoretically predicted superconducting materials discovered by theoretical physicists from 2023 to 2025 based on BCS superconductivity theory, including the renowned X$_2$YH$_6$ system, perovskite MXH$_3$ system, M$_3$XH$_8$ system, cage-like BCN-doped metal atomic systems derived from LaH$_{10}$ structural evolution, and two-dimensional honeycomb-structured systems evolving from MgB$_2$. The HTSC-2025 benchmark has been open-sourced at https://github.com/xqh19970407/HTSC-2025 and will be continuously updated. This benchmark holds significant importance for accelerating the discovery of superconducting materials using AI-based methods.
InvDesFlow-AL: Active Learning-based Workflow for Inverse Design of Functional Materials
May 14, 2025Developing inverse design methods for functional materials with specific properties is critical to advancing fields like renewable energy, catalysis, energy storage, and carbon capture. Generative models based on diffusion principles can directly produce new materials that meet performance constraints, thereby significantly accelerating the material design process. However, existing methods for generating and predicting crystal structures often remain limited by low success rates. In this work, we propose a novel inverse material design generative framework called InvDesFlow-AL, which is based on active learning strategies. This framework can iteratively optimize the material generation process to gradually guide it towards desired performance characteristics. In terms of crystal structure prediction, the InvDesFlow-AL model achieves an RMSE of 0.0423 {\AA}, representing an 32.96% improvement in performance compared to exsisting generative models. Additionally, InvDesFlow-AL has been successfully validated in the design of low-formation-energy and low-Ehull materials. It can systematically generate materials with progressively lower formation energies while continuously expanding the exploration across diverse chemical spaces. These results fully demonstrate the effectiveness of the proposed active learning-driven generative model in accelerating material discovery and inverse design. To further prove the effectiveness of this method, we took the search for BCS superconductors under ambient pressure as an example explored by InvDesFlow-AL. As a result, we successfully identified Li\(_2\)AuH\(_6\) as a conventional BCS superconductor with an ultra-high transition temperature of 140 K. This discovery provides strong empirical support for the application of inverse design in materials science.
Strong phonon-mediated high temperature superconductivity in Li$_2$AuH$_6$ under ambient pressure
Jan 21, 2025



We used our developed AI search engine~(InvDesFlow) to perform extensive investigations regarding ambient stable superconducting hydrides. A cubic structure Li$_2$AuH$_6$ with Au-H octahedral motifs is identified to be a candidate. After performing thermodynamical analysis, we provide a feasible route to experimentally synthesize this material via the known LiAu and LiH compounds under ambient pressure. The further first-principles calculations suggest that Li$_2$AuH$_6$ shows a high superconducting transition temperature ($T_c$) $\sim$ 140 K under ambient pressure. The H-1$s$ electrons strongly couple with phonon modes of vibrations of Au-H octahedrons as well as vibrations of Li atoms, where the latter is not taken seriously in other previously similar cases. Hence, different from previous claims of searching metallic covalent bonds to find high-$T_c$ superconductors, we emphasize here the importance of those phonon modes with strong electron-phonon coupling (EPC). And we suggest that one can intercalate atoms into binary or ternary hydrides to introduce more potential phonon modes with strong EPC, which is an effective approach to find high-$T_c$ superconductors within multicomponent compounds.
AI-driven inverse design of materials: Past, present and future
Nov 14, 2024



The discovery of advanced materials is the cornerstone of human technological development and progress. The structures of materials and their corresponding properties are essentially the result of a complex interplay of multiple degrees of freedom such as lattice, charge, spin, symmetry, and topology. This poses significant challenges for the inverse design methods of materials. Humans have long explored new materials through a large number of experiments and proposed corresponding theoretical systems to predict new material properties and structures. With the improvement of computational power, researchers have gradually developed various electronic structure calculation methods, particularly such as the one based density functional theory, as well as high-throughput computational methods. Recently, the rapid development of artificial intelligence technology in the field of computer science has enabled the effective characterization of the implicit association between material properties and structures, thus opening up an efficient paradigm for the inverse design of functional materials. A significant progress has been made in inverse design of materials based on generative and discriminative models, attracting widespread attention from researchers. Considering this rapid technological progress, in this survey, we look back on the latest advancements in AI-driven inverse design of materials by introducing the background, key findings, and mainstream technological development routes. In addition, we summarize the remaining issues for future directions. This survey provides the latest overview of AI-driven inverse design of materials, which can serve as a useful resource for researchers.
Over-parameterized Student Model via Tensor Decomposition Boosted Knowledge Distillation
Nov 10, 2024



Increased training parameters have enabled large pre-trained models to excel in various downstream tasks. Nevertheless, the extensive computational requirements associated with these models hinder their widespread adoption within the community. We focus on Knowledge Distillation (KD), where a compact student model is trained to mimic a larger teacher model, facilitating the transfer of knowledge of large models. In contrast to much of the previous work, we scale up the parameters of the student model during training, to benefit from overparameterization without increasing the inference latency. In particular, we propose a tensor decomposition strategy that effectively over-parameterizes the relatively small student model through an efficient and nearly lossless decomposition of its parameter matrices into higher-dimensional tensors. To ensure efficiency, we further introduce a tensor constraint loss to align the high-dimensional tensors between the student and teacher models. Comprehensive experiments validate the significant performance enhancement by our approach in various KD tasks, covering computer vision and natural language processing areas. Our code is available at https://github.com/intell-sci-comput/OPDF.
AI-accelerated discovery of high critical temperature superconductors
Sep 12, 2024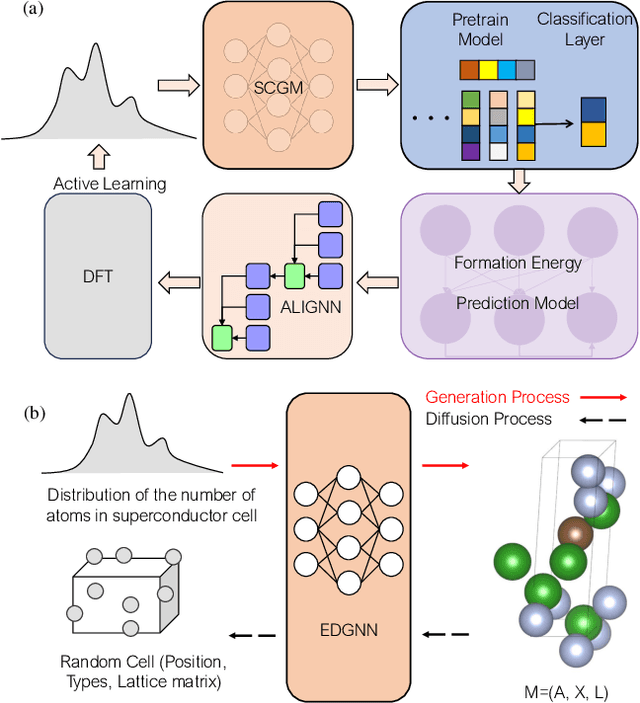
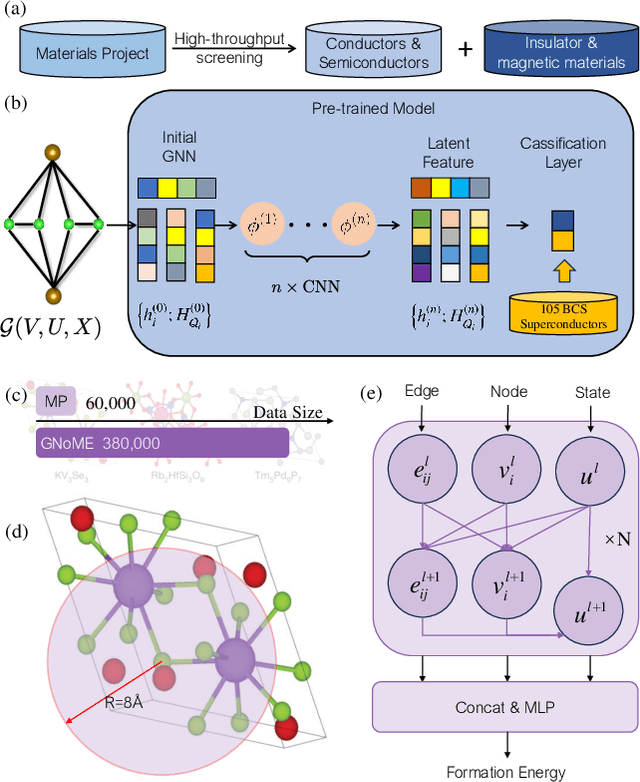
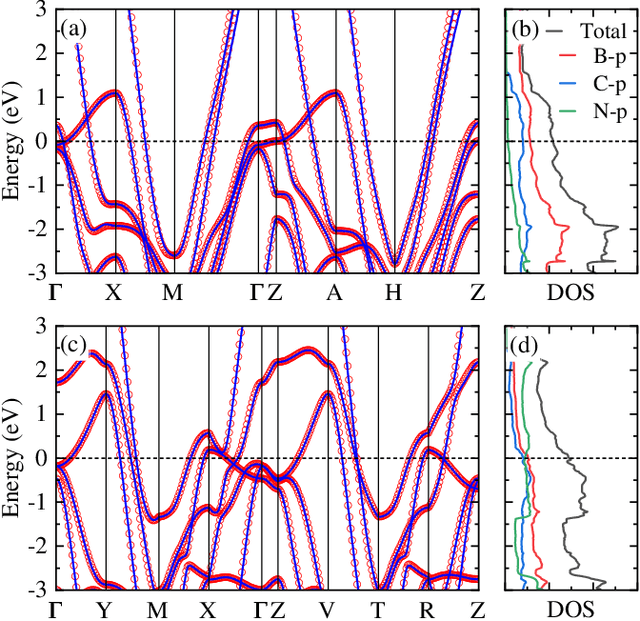
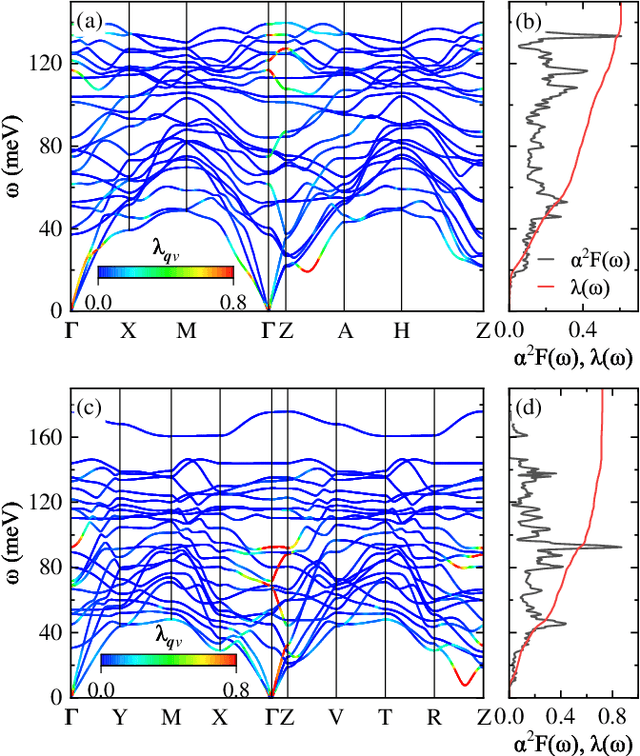
The discovery of new superconducting materials, particularly those exhibiting high critical temperature ($T_c$), has been a vibrant area of study within the field of condensed matter physics. Conventional approaches primarily rely on physical intuition to search for potential superconductors within the existing databases. However, the known materials only scratch the surface of the extensive array of possibilities within the realm of materials. Here, we develop an AI search engine that integrates deep model pre-training and fine-tuning techniques, diffusion models, and physics-based approaches (e.g., first-principles electronic structure calculation) for discovery of high-$T_c$ superconductors. Utilizing this AI search engine, we have obtained 74 dynamically stable materials with critical temperatures predicted by the AI model to be $T_c \geq$ 15 K based on a very small set of samples. Notably, these materials are not contained in any existing dataset. Furthermore, we analyze trends in our dataset and individual materials including B$_4$CN$_3$ and B$_5$CN$_2$ whose $T_c$s are 24.08 K and 15.93 K, respectively. We demonstrate that AI technique can discover a set of new high-$T_c$ superconductors, outline its potential for accelerating discovery of the materials with targeted properties.
Discovering symbolic expressions with parallelized tree search
Jul 05, 2024Symbolic regression plays a crucial role in modern scientific research thanks to its capability of discovering concise and interpretable mathematical expressions from data. A grand challenge lies in the arduous search for parsimonious and generalizable mathematical formulas, in an infinite search space, while intending to fit the training data. Existing algorithms have faced a critical bottleneck of accuracy and efficiency over a decade when handling problems of complexity, which essentially hinders the pace of applying symbolic regression for scientific exploration across interdisciplinary domains. To this end, we introduce a parallelized tree search (PTS) model to efficiently distill generic mathematical expressions from limited data. Through a series of extensive experiments, we demonstrate the superior accuracy and efficiency of PTS for equation discovery, which greatly outperforms the state-of-the-art baseline models on over 80 synthetic and experimental datasets (e.g., lifting its performance by up to 99% accuracy improvement and one-order of magnitude speed up). PTS represents a key advance in accurate and efficient data-driven discovery of symbolic, interpretable models (e.g., underlying physical laws) and marks a pivotal transition towards scalable symbolic learning.
YuLan: An Open-source Large Language Model
Jun 28, 2024



Large language models (LLMs) have become the foundation of many applications, leveraging their extensive capabilities in processing and understanding natural language. While many open-source LLMs have been released with technical reports, the lack of training details hinders further research and development. This paper presents the development of YuLan, a series of open-source LLMs with $12$ billion parameters. The base model of YuLan is pre-trained on approximately $1.7$T tokens derived from a diverse corpus, including massive English, Chinese, and multilingual texts. We design a three-stage pre-training method to enhance YuLan's overall capabilities. Subsequent phases of training incorporate instruction-tuning and human alignment, employing a substantial volume of high-quality synthesized data. To facilitate the learning of complex and long-tail knowledge, we devise a curriculum-learning framework throughout across these stages, which helps LLMs learn knowledge in an easy-to-hard manner. YuLan's training is finished on Jan, 2024 and has achieved performance on par with state-of-the-art LLMs across various English and Chinese benchmarks. This paper outlines a comprehensive technical roadmap for developing LLMs from scratch. Our model and codes are available at https://github.com/RUC-GSAI/YuLan-Chat.
Unlocking Data-free Low-bit Quantization with Matrix Decomposition for KV Cache Compression
May 21, 2024Key-value~(KV) caching is an important technique to accelerate the inference of large language models~(LLMs), but incurs significant memory overhead. To compress the size of KV cache, existing methods often compromise precision or require extra data for calibration, limiting their practicality in LLM deployment. In this paper, we introduce \textbf{DecoQuant}, a novel data-free low-bit quantization technique based on tensor decomposition methods, to effectively compress KV cache. Our core idea is to adjust the outlier distribution of the original matrix by performing tensor decomposition, so that the quantization difficulties are migrated from the matrix to decomposed local tensors. Specially, we find that outliers mainly concentrate on small local tensors, while large tensors tend to have a narrower value range. Based on this finding, we propose to apply low-bit quantization to the large tensor, while maintaining high-precision representation for the small tensor. Furthermore, we utilize the proposed quantization method to compress the KV cache of LLMs to accelerate the inference and develop an efficient dequantization kernel tailored specifically for DecoQuant. Through extensive experiments, DecoQuant demonstrates remarkable efficiency gains, showcasing up to a $\sim$75\% reduction in memory footprint while maintaining comparable generation quality.