 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Thought Compression Should Not Be Blind: V-Skip for Efficient Multimodal Reasoning via Dual-Path Anchoring
Jan 21, 2026While Chain-of-Thought (CoT) reasoning significantly enhances the performance of Multimodal Large Language Models (MLLMs), its autoregressive nature incurs prohibitive latency constraints. Current efforts to mitigate this via token compression often fail by blindly applying text-centric metrics to multimodal contexts. We identify a critical failure mode termed Visual Amnesia, where linguistically redundant tokens are erroneously pruned, leading to hallucinations. To address this, we introduce V-Skip that reformulates token pruning as a Visual-Anchored Information Bottleneck (VA-IB) optimization problem. V-Skip employs a dual-path gating mechanism that weighs token importance through both linguistic surprisal and cross-modal attention flow, effectively rescuing visually salient anchors. Extensive experiments on Qwen2-VL and Llama-3.2 families demonstrate that V-Skip achieves a $2.9\times$ speedup with negligible accuracy loss. Specifically, it preserves fine-grained visual details, outperforming other baselines over 30\% on the DocVQA.
PointDico: Contrastive 3D Representation Learning Guided by Diffusion Models
Dec 09, 2025Self-supervised representation learning has shown significant improvement in Natural Language Processing and 2D Computer Vision. However, existing methods face difficulties in representing 3D data because of its unordered and uneven density. Through an in-depth analysis of mainstream contrastive and generative approaches, we find that contrastive models tend to suffer from overfitting, while 3D Mask Autoencoders struggle to handle unordered point clouds. This motivates us to learn 3D representations by sharing the merits of diffusion and contrast models, which is non-trivial due to the pattern difference between the two paradigms. In this paper, we propose \textit{PointDico}, a novel model that seamlessly integrates these methods. \textit{PointDico} learns from both denoising generative modeling and cross-modal contrastive learning through knowledge distillation, where the diffusion model serves as a guide for the contrastive model. We introduce a hierarchical pyramid conditional generator for multi-scale geometric feature extraction and employ a dual-channel design to effectively integrate local and global contextual information. \textit{PointDico} achieves a new state-of-the-art in 3D representation learning, \textit{e.g.}, \textbf{94.32\%} accuracy on ScanObjectNN, \textbf{86.5\%} Inst. mIoU on ShapeNetPart.
AFBS:Buffer Gradient Selection in Semi-asynchronous Federated Learning
Jun 15, 2025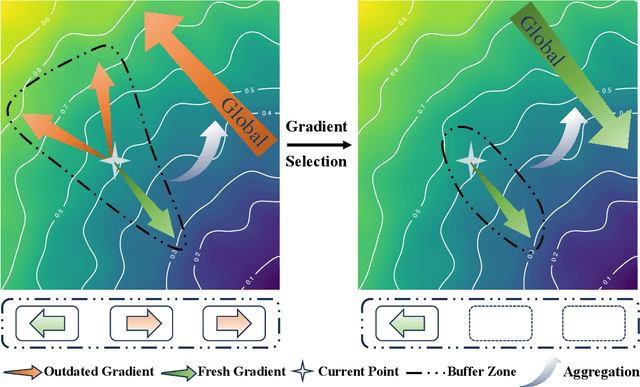



Asynchronous federated learning (AFL) accelerates training by eliminating the need to wait for stragglers, but its asynchronous nature introduces gradient staleness, where outdated gradients degrade performance. Existing solutions address this issue with gradient buffers, forming a semi-asynchronous framework. However, this approach struggles when buffers accumulate numerous stale gradients, as blindly aggregating all gradients can harm training. To address this, we propose AFBS (Asynchronous FL Buffer Selection), the first algorithm to perform gradient selection within buffers while ensuring privacy protection. Specifically, the client sends the random projection encrypted label distribution matrix before training, and the server performs client clustering based on it. During training, server scores and selects gradients within each cluster based on their informational value, discarding low-value gradients to enhance semi-asynchronous federated learning. Extensive experiments in highly heterogeneous system and data environments demonstrate AFBS's superior performance compared to state-of-the-art methods. Notably, on the most challenging task, CIFAR-100, AFBS improves accuracy by up to 4.8% over the previous best algorithm and reduces the time to reach target accuracy by 75%.
Corrected with the Latest Version: Make Robust Asynchronous Federated Learning Possible
Apr 09, 2025



As an emerging paradigm of federated learning, asynchronous federated learning offers significant speed advantages over traditional synchronous federated learning. Unlike synchronous federated learning, which requires waiting for all clients to complete updates before aggregation, asynchronous federated learning aggregates the models that have arrived in realtime, greatly improving training speed. However, this mechanism also introduces the issue of client model version inconsistency. When the differences between models of different versions during aggregation become too large, it may lead to conflicts, thereby reducing the models accuracy. To address this issue, this paper proposes an asynchronous federated learning version correction algorithm based on knowledge distillation, named FedADT. FedADT applies knowledge distillation before aggregating gradients, using the latest global model to correct outdated information, thus effectively reducing the negative impact of outdated gradients on the training process. Additionally, FedADT introduces an adaptive weighting function that adjusts the knowledge distillation weight according to different stages of training, helps mitigate the misleading effects caused by the poorer performance of the global model in the early stages of training. This method significantly improves the overall performance of asynchronous federated learning without adding excessive computational overhead. We conducted experimental comparisons with several classical algorithms, and the results demonstrate that FedADT achieves significant improvements over other asynchronous methods and outperforms all methods in terms of convergence speed.
BaichuanSEED: Sharing the Potential of ExtensivE Data Collection and Deduplication by Introducing a Competitive Large Language Model Baseline
Aug 27, 2024
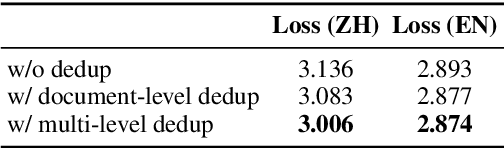

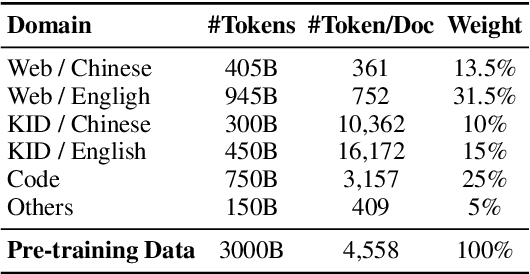
The general capabilities of Large Language Models (LLM) highly rely on the composition and selection on extensive pretraining datasets, treated as commercial secrets by several institutions. To mitigate this issue, we open-source the details of a universally applicable data processing pipeline and validate its effectiveness and potential by introducing a competitive LLM baseline. Specifically, the data processing pipeline consists of broad collection to scale up and reweighting to improve quality. We then pretrain a 7B model BaichuanSEED with 3T tokens processed by our pipeline without any deliberate downstream task-related optimization, followed by an easy but effective supervised fine-tuning stage. BaichuanSEED demonstrates consistency and predictability throughout training and achieves comparable performance on comprehensive benchmarks with several commercial advanced large language models, such as Qwen1.5 and Llama3. We also conduct several heuristic experiments to discuss the potential for further optimization of downstream tasks, such as mathematics and coding.
Aligning Explanations for Recommendation with Rating and Feature via Maximizing Mutual Information
Jul 18, 2024
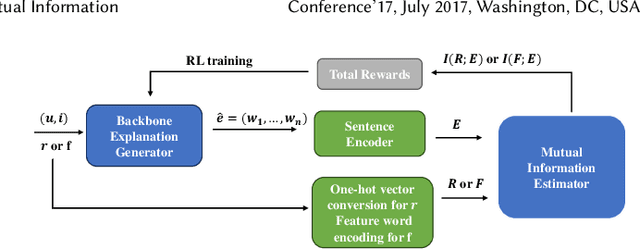
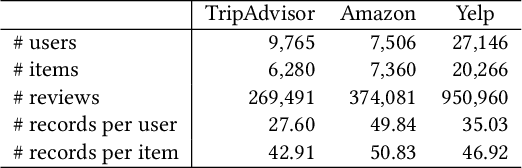
Providing natural language-based explanations to justify recommendations helps to improve users' satisfaction and gain users' trust. However, as current explanation generation methods are commonly trained with an objective to mimic existing user reviews, the generated explanations are often not aligned with the predicted ratings or some important features of the recommended items, and thus, are suboptimal in helping users make informed decision on the recommendation platform. To tackle this problem, we propose a flexible model-agnostic method named MMI (Maximizing Mutual Information) framework to enhance the alignment between the generated natural language explanations and the predicted rating/important item features. Specifically, we propose to use mutual information (MI) as a measure for the alignment and train a neural MI estimator. Then, we treat a well-trained explanation generation model as the backbone model and further fine-tune it through reinforcement learning with guidance from the MI estimator, which rewards a generated explanation that is more aligned with the predicted rating or a pre-defined feature of the recommended item. Experiments on three datasets demonstrate that our MMI framework can boost different backbone models, enabling them to outperform existing baselines in terms of alignment with predicted ratings and item features. Additionally, user studies verify that MI-enhanced explanations indeed facilitate users' decisions and are favorable compared with other baselines due to their better alignment properties.
YuLan: An Open-source Large Language Model
Jun 28, 2024



Large language models (LLMs) have become the foundation of many applications, leveraging their extensive capabilities in processing and understanding natural language. While many open-source LLMs have been released with technical reports, the lack of training details hinders further research and development. This paper presents the development of YuLan, a series of open-source LLMs with $12$ billion parameters. The base model of YuLan is pre-trained on approximately $1.7$T tokens derived from a diverse corpus, including massive English, Chinese, and multilingual texts. We design a three-stage pre-training method to enhance YuLan's overall capabilities. Subsequent phases of training incorporate instruction-tuning and human alignment, employing a substantial volume of high-quality synthesized data. To facilitate the learning of complex and long-tail knowledge, we devise a curriculum-learning framework throughout across these stages, which helps LLMs learn knowledge in an easy-to-hard manner. YuLan's training is finished on Jan, 2024 and has achieved performance on par with state-of-the-art LLMs across various English and Chinese benchmarks. This paper outlines a comprehensive technical roadmap for developing LLMs from scratch. Our model and codes are available at https://github.com/RUC-GSAI/YuLan-Chat.
An Integrated Data Processing Framework for Pretraining Foundation Models
Feb 26, 2024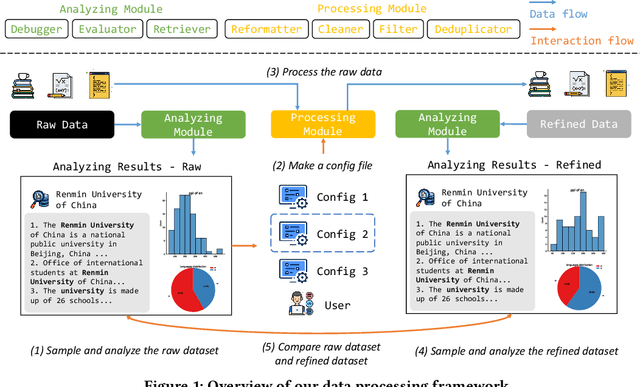



The ability of the foundation models heavily relies on large-scale, diverse, and high-quality pretraining data. In order to improve data quality, researchers and practitioners often have to manually curate datasets from difference sources and develop dedicated data cleansing pipeline for each data repository. Lacking a unified data processing framework, this process is repetitive and cumbersome. To mitigate this issue, we propose a data processing framework that integrates a Processing Module which consists of a series of operators at different granularity levels, and an Analyzing Module which supports probing and evaluation of the refined data. The proposed framework is easy to use and highly flexible. In this demo paper, we first introduce how to use this framework with some example use cases and then demonstrate its effectiveness in improving the data quality with an automated evaluation with ChatGPT and an end-to-end evaluation in pretraining the GPT-2 model. The code and demonstration videos are accessible on GitHub.