 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Image Super-Resolution via Consistency Rectified Flow
May 12, 2026Diffusion models (DMs) have demonstrated remarkable success in real-world image super-resolution (SR), yet their reliance on time-consuming multi-step sampling largely hinders their practical applications. While recent efforts have introduced few- or single-step solutions, existing methods either inefficiently model the process from noisy input or fail to fully exploit iterative generative priors, compromising the fidelity and quality of the reconstructed images. To address this issue, we propose FlowSR, a novel approach that reformulates the SR problem as a rectified flow from low-resolution (LR) to high-resolution (HR) images. Our method leverages an improved consistency learning strategy to enable high-quality SR in a single step. Specifically, we refine the original consistency distillation process by incorporating HR regularization, ensuring that the learned SR flow not only enforces self-consistency but also converges precisely to the ground-truth HR target. Furthermore, we introduce a fast-slow scheduling strategy, where adjacent timesteps for consistency learning are sampled from two distinct schedulers: a fast scheduler with fewer timesteps to improve efficiency, and a slow scheduler with more timesteps to capture fine-grained texture details. Extensive experiments demonstrate that FlowSR achieves outstanding performance in both efficiency and image quality.
Thinking with Novel Views: A Systematic Analysis of Generative-Augmented Spatial Intelligence
May 11, 2026Current Large Multimodal Models (LMMs) struggle with spatial reasoning tasks requiring viewpoint-dependent understanding, largely because they are confined to a single, static observation. We propose Thinking with Novel Views (TwNV), a paradigm that integrates generative novel-view synthesis into the reasoning loop: a Reasoner LMM identifies spatial ambiguity, instructs a Painter to synthesize an alternative viewpoint, and re-examines the scene with the additional evidence. Through systematic experiments we address three research questions. (1) Instruction format: numerical camera-pose specifications yield more reliable view control than free-form language. (2) Generation fidelity: synthesized view quality is tightly coupled with downstream spatial accuracy. (3) Inference-time visual scaling: iterative multi-turn view refinement further improves performance, echoing recent scaling trends in language reasoning. Across four spatial subtask categories and four LMM architectures (both closed- and open-source), TwNV consistently improves accuracy by +1.3 to +3.9 pp, with the largest gains on viewpoint-sensitive subtasks. These results establish novel-view generation as a practical lever for advancing spatial intelligence of LMMs.
Awaking Spatial Intelligence in Unified Multimodal Understanding and Generation
May 05, 2026We present JoyAI-Image, a unified multimodal foundation model for visual understanding, text-to-image generation, and instruction-guided image editing. JoyAI-Image couples a spatially enhanced Multimodal Large Language Model (MLLM) with a Multimodal Diffusion Transformer (MMDiT), allowing perception and generation to interact through a shared multimodal interface. Around this architecture, we build a scalable training recipe that combines unified instruction tuning, long-text rendering supervision, spatially grounded data, and both general and spatial editing signals. This design gives the model broad multimodal capability while strengthening geometry-aware reasoning and controllable visual synthesis. Experiments across understanding, generation, long-text rendering, and editing benchmarks show that JoyAI-Image achieves state-of-the-art or highly competitive performance. More importantly, the bidirectional loop between enhanced understanding, controllable spatial editing, and novel-view-assisted reasoning enables the model to move beyond general visual competence toward stronger spatial intelligence. These results suggest a promising path for unified visual models in downstream applications such as vision-language-action systems and world models.
OpenSpatial: A Principled Data Engine for Empowering Spatial Intelligence
Apr 09, 2026Spatial understanding is a fundamental cornerstone of human-level intelligence. Nonetheless, current research predominantly focuses on domain-specific data production, leaving a critical void: the absence of a principled, open-source engine capable of fully unleashing the potential of high-quality spatial data. To bridge this gap, we elucidate the design principles of a robust data generation system and introduce OpenSpatial -- an open-source data engine engineered for high quality, extensive scalability, broad task diversity, and optimized efficiency. OpenSpatial adopts 3D bounding boxes as the fundamental primitive to construct a comprehensive data hierarchy across five foundational tasks: Spatial Measurement (SM), Spatial Relationship (SR), Camera Perception (CP), Multi-view Consistency (MC), and Scene-Aware Reasoning (SAR). Leveraging this scalable infrastructure, we curate OpenSpatial-3M, a large-scale dataset comprising 3 million high-fidelity samples. Extensive evaluations demonstrate that versatile models trained on our dataset achieve state-of-the-art performance across a wide spectrum of spatial reasoning benchmarks. Notably, the best-performing model exhibits a substantial average improvement of 19 percent, relatively. Furthermore, we provide a systematic analysis of how data attributes influence spatial perception. By open-sourcing both the engine and the 3M-scale dataset, we provide a robust foundation to accelerate future research in spatial intelligence.
LongCat-Next: Lexicalizing Modalities as Discrete Tokens
Mar 29, 2026The prevailing Next-Token Prediction (NTP) paradigm has driven the success of large language models through discrete autoregressive modeling. However, contemporary multimodal systems remain language-centric, often treating non-linguistic modalities as external attachments, leading to fragmented architectures and suboptimal integration. To transcend this limitation, we introduce Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space, enabling a consistent and principled autoregressive modeling across modalities. A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions, transforming continuous visual signals into hierarchical discrete tokens. Building on this foundation, we develop LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design. As an industrial-strength foundation model, it excels at seeing, painting, and talking within a single framework, achieving strong performance across a wide range of multimodal benchmarks. In particular, LongCat-Next addresses the long-standing performance ceiling of discrete vision modeling on understanding tasks and provides a unified approach to effectively reconcile the conflict between understanding and generation. As an attempt toward native multimodality, we open-source the LongCat-Next and its tokenizers, hoping to foster further research and development in the community. GitHub: https://github.com/meituan-longcat/LongCat-Next
GIFT: Unlocking Global Optimality in Post-Training via Finite-Temperature Gibbs Initialization
Jan 14, 2026The prevailing post-training paradigm for Large Reasoning Models (LRMs)--Supervised Fine-Tuning (SFT) followed by Reinforcement Learning (RL)--suffers from an intrinsic optimization mismatch: the rigid supervision inherent in SFT induces distributional collapse, thereby exhausting the exploration space necessary for subsequent RL. In this paper, we reformulate SFT within a unified post-training framework and propose Gibbs Initialization with Finite Temperature (GIFT). We characterize standard SFT as a degenerate zero-temperature limit that suppresses base priors. Conversely, GIFT incorporates supervision as a finite-temperature energy potential, establishing a distributional bridge that ensures objective consistency throughout the post-training pipeline. Our experiments demonstrate that GIFT significantly outperforms standard SFT and other competitive baselines when utilized for RL initialization, providing a mathematically principled pathway toward achieving global optimality in post-training. Our code is available at https://github.com/zzy1127/GIFT.
S2SBench: A Benchmark for Quantifying Intelligence Degradation in Speech-to-Speech Large Language Models
May 20, 2025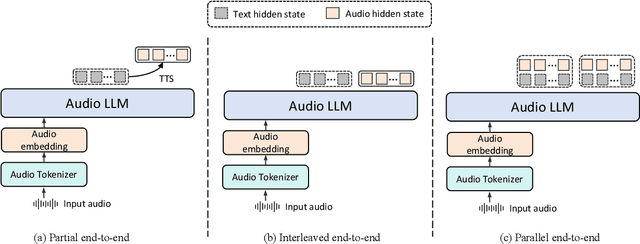
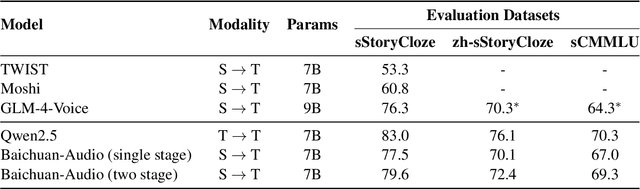
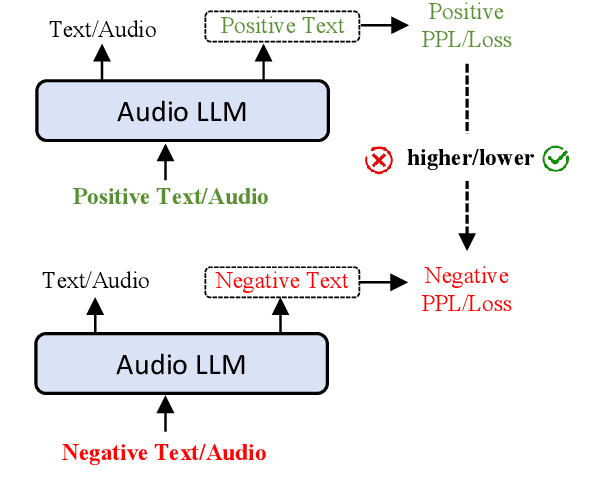
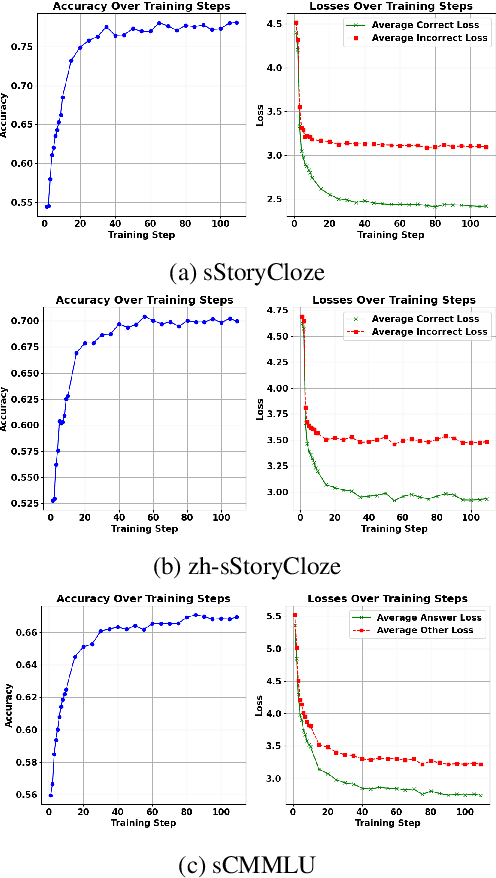
End-to-end speech large language models ((LLMs)) extend the capabilities of text-based models to directly process and generate audio tokens. However, this often leads to a decline in reasoning and generation performance compared to text input, a phenomenon referred to as intelligence degradation. To systematically evaluate this gap, we propose S2SBench, a benchmark designed to quantify performance degradation in Speech LLMs. It includes diagnostic datasets targeting sentence continuation and commonsense reasoning under audio input. We further introduce a pairwise evaluation protocol based on perplexity differences between plausible and implausible samples to measure degradation relative to text input. We apply S2SBench to analyze the training process of Baichuan-Audio, which further demonstrates the benchmark's effectiveness. All datasets and evaluation code are available at https://github.com/undobug/S2SBench.
Turbo2K: Towards Ultra-Efficient and High-Quality 2K Video Synthesis
Apr 20, 2025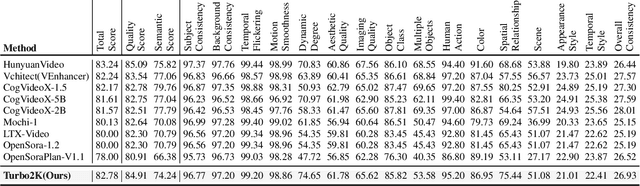

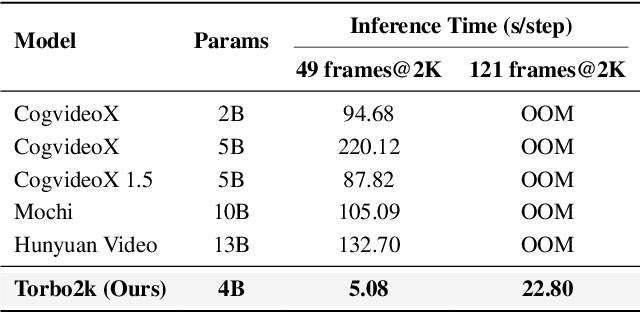

Demand for 2K video synthesis is rising with increasing consumer expectations for ultra-clear visuals. While diffusion transformers (DiTs) have demonstrated remarkable capabilities in high-quality video generation, scaling them to 2K resolution remains computationally prohibitive due to quadratic growth in memory and processing costs. In this work, we propose Turbo2K, an efficient and practical framework for generating detail-rich 2K videos while significantly improving training and inference efficiency. First, Turbo2K operates in a highly compressed latent space, reducing computational complexity and memory footprint, making high-resolution video synthesis feasible. However, the high compression ratio of the VAE and limited model size impose constraints on generative quality. To mitigate this, we introduce a knowledge distillation strategy that enables a smaller student model to inherit the generative capacity of a larger, more powerful teacher model. Our analysis reveals that, despite differences in latent spaces and architectures, DiTs exhibit structural similarities in their internal representations, facilitating effective knowledge transfer. Second, we design a hierarchical two-stage synthesis framework that first generates multi-level feature at lower resolutions before guiding high-resolution video generation. This approach ensures structural coherence and fine-grained detail refinement while eliminating redundant encoding-decoding overhead, further enhancing computational efficiency.Turbo2K achieves state-of-the-art efficiency, generating 5-second, 24fps, 2K videos with significantly reduced computational cost. Compared to existing methods, Turbo2K is up to 20$\times$ faster for inference, making high-resolution video generation more scalable and practical for real-world applications.
ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning
Mar 27, 2025



Large Language Models (LLMs) have shown remarkable capabilities in reasoning, exemplified by the success of OpenAI-o1 and DeepSeek-R1. However, integrating reasoning with external search processes remains challenging, especially for complex multi-hop questions requiring multiple retrieval steps. We propose ReSearch, a novel framework that trains LLMs to Reason with Search via reinforcement learning without using any supervised data on reasoning steps. Our approach treats search operations as integral components of the reasoning chain, where when and how to perform searches is guided by text-based thinking, and search results subsequently influence further reasoning. We train ReSearch on Qwen2.5-7B(-Instruct) and Qwen2.5-32B(-Instruct) models and conduct extensive experiments. Despite being trained on only one dataset, our models demonstrate strong generalizability across various benchmarks. Analysis reveals that ReSearch naturally elicits advanced reasoning capabilities such as reflection and self-correction during the reinforcement learning process.
DualToken: Towards Unifying Visual Understanding and Generation with Dual Visual Vocabularies
Mar 19, 2025The differing representation spaces required for visual understanding and generation pose a challenge in unifying them within the autoregressive paradigm of large language models. A vision tokenizer trained for reconstruction excels at capturing low-level perceptual details, making it well-suited for visual generation but lacking high-level semantic representations for understanding tasks. Conversely, a vision encoder trained via contrastive learning aligns well with language but struggles to decode back into the pixel space for generation tasks. To bridge this gap, we propose DualToken, a method that unifies representations for both understanding and generation within a single tokenizer. However, directly integrating reconstruction and semantic objectives in a single tokenizer creates conflicts, leading to degraded performance in both reconstruction quality and semantic performance. Instead of forcing a single codebook to handle both semantic and perceptual information, DualToken disentangles them by introducing separate codebooks for high and low-level features, effectively transforming their inherent conflict into a synergistic relationship. As a result, DualToken achieves state-of-the-art performance in both reconstruction and semantic tasks while demonstrating remarkable effectiveness in downstream MLLM understanding and generation tasks. Notably, we also show that DualToken, as a unified tokenizer, surpasses the naive combination of two distinct types vision encoders, providing superior performance within a unified MLLM.