 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth-Synergized Mamba Meets Memory Experts for All-Day Image Reflection Separation
Jan 01, 2026Image reflection separation aims to disentangle the transmission layer and the reflection layer from a blended image. Existing methods rely on limited information from a single image, tending to confuse the two layers when their contrasts are similar, a challenge more severe at night. To address this issue, we propose the Depth-Memory Decoupling Network (DMDNet). It employs the Depth-Aware Scanning (DAScan) to guide Mamba toward salient structures, promoting information flow along semantic coherence to construct stable states. Working in synergy with DAScan, the Depth-Synergized State-Space Model (DS-SSM) modulates the sensitivity of state activations by depth, suppressing the spread of ambiguous features that interfere with layer disentanglement. Furthermore, we introduce the Memory Expert Compensation Module (MECM), leveraging cross-image historical knowledge to guide experts in providing layer-specific compensation. To address the lack of datasets for nighttime reflection separation, we construct the Nighttime Image Reflection Separation (NightIRS) dataset. Extensive experiments demonstrate that DMDNet outperforms state-of-the-art methods in both daytime and nighttime.
PMQ-VE: Progressive Multi-Frame Quantization for Video Enhancement
May 18, 2025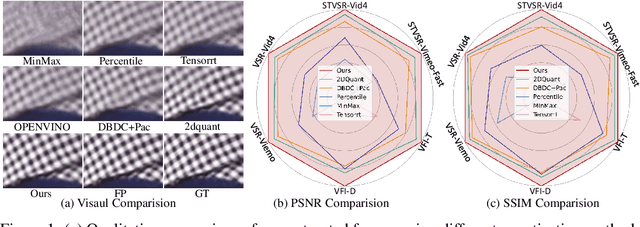
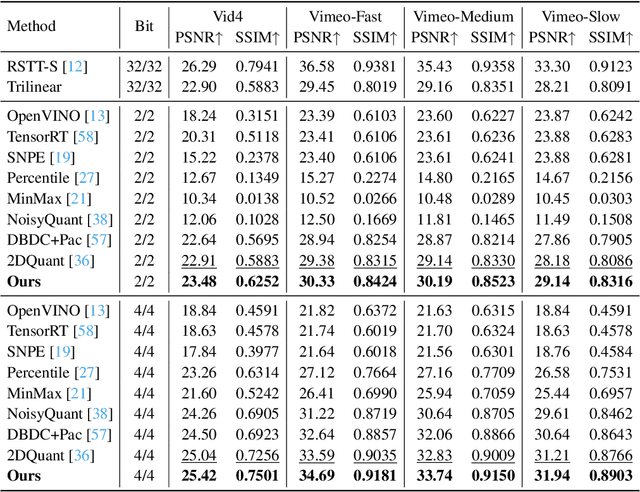
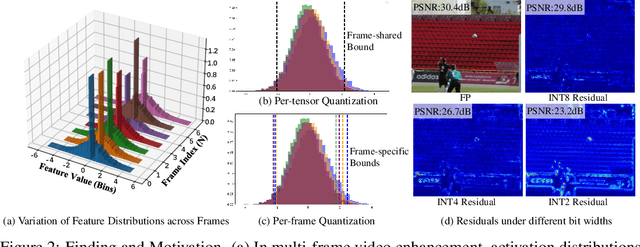
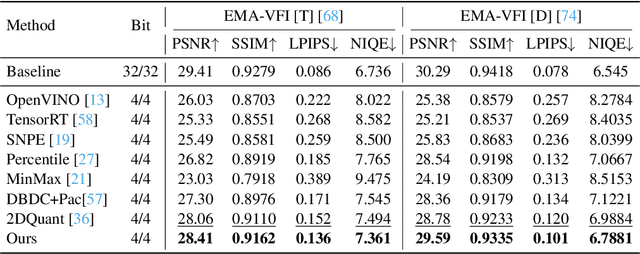
Multi-frame video enhancement tasks aim to improve the spatial and temporal resolution and quality of video sequences by leveraging temporal information from multiple frames, which are widely used in streaming video processing, surveillance, and generation. Although numerous Transformer-based enhancement methods have achieved impressive performance, their computational and memory demands hinder deployment on edge devices. Quantization offers a practical solution by reducing the bit-width of weights and activations to improve efficiency. However, directly applying existing quantization methods to video enhancement tasks often leads to significant performance degradation and loss of fine details. This stems from two limitations: (a) inability to allocate varying representational capacity across frames, which results in suboptimal dynamic range adaptation; (b) over-reliance on full-precision teachers, which limits the learning of low-bit student models. To tackle these challenges, we propose a novel quantization method for video enhancement: Progressive Multi-Frame Quantization for Video Enhancement (PMQ-VE). This framework features a coarse-to-fine two-stage process: Backtracking-based Multi-Frame Quantization (BMFQ) and Progressive Multi-Teacher Distillation (PMTD). BMFQ utilizes a percentile-based initialization and iterative search with pruning and backtracking for robust clipping bounds. PMTD employs a progressive distillation strategy with both full-precision and multiple high-bit (INT) teachers to enhance low-bit models' capacity and quality. Extensive experiments demonstrate that our method outperforms existing approaches, achieving state-of-the-art performance across multiple tasks and benchmarks.The code will be made publicly available at: https://github.com/xiaoBIGfeng/PMQ-VE.
EarthSynth: Generating Informative Earth Observation with Diffusion Models
May 17, 2025Remote sensing image (RSI) interpretation typically faces challenges due to the scarcity of labeled data, which limits the performance of RSI interpretation tasks. To tackle this challenge, we propose EarthSynth, a diffusion-based generative foundation model that enables synthesizing multi-category, cross-satellite labeled Earth observation for downstream RSI interpretation tasks. To the best of our knowledge, EarthSynth is the first to explore multi-task generation for remote sensing. EarthSynth, trained on the EarthSynth-180K dataset, employs the Counterfactual Composition training strategy to improve training data diversity and enhance category control. Furthermore, a rule-based method of R-Filter is proposed to filter more informative synthetic data for downstream tasks. We evaluate our EarthSynth on scene classification, object detection, and semantic segmentation in open-world scenarios, offering a practical solution for advancing RSI interpretation.
Enhance Then Search: An Augmentation-Search Strategy with Foundation Models for Cross-Domain Few-Shot Object Detection
Apr 06, 2025Foundation models pretrained on extensive datasets, such as GroundingDINO and LAE-DINO, have performed remarkably in the cross-domain few-shot object detection (CD-FSOD) task. Through rigorous few-shot training, we found that the integration of image-based data augmentation techniques and grid-based sub-domain search strategy significantly enhances the performance of these foundation models. Building upon GroundingDINO, we employed several widely used image augmentation methods and established optimization objectives to effectively navigate the expansive domain space in search of optimal sub-domains. This approach facilitates efficient few-shot object detection and introduces an approach to solving the CD-FSOD problem by efficiently searching for the optimal parameter configuration from the foundation model. Our findings substantially advance the practical deployment of vision-language models in data-scarce environments, offering critical insights into optimizing their cross-domain generalization capabilities without labor-intensive retraining. Code is available at https://github.com/jaychempan/ETS.
Brightness Perceiving for Recursive Low-Light Image Enhancement
Apr 03, 2025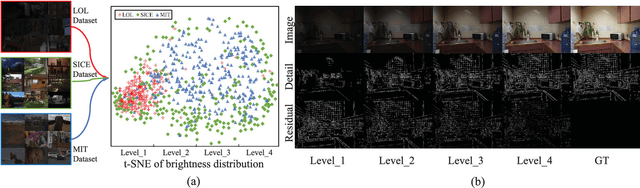



Due to the wide dynamic range in real low-light scenes, there will be large differences in the degree of contrast degradation and detail blurring of captured images, making it difficult for existing end-to-end methods to enhance low-light images to normal exposure. To address the above issue, we decompose low-light image enhancement into a recursive enhancement task and propose a brightness-perceiving-based recursive enhancement framework for high dynamic range low-light image enhancement. Specifically, our recursive enhancement framework consists of two parallel sub-networks: Adaptive Contrast and Texture enhancement network (ACT-Net) and Brightness Perception network (BP-Net). The ACT-Net is proposed to adaptively enhance image contrast and details under the guidance of the brightness adjustment branch and gradient adjustment branch, which are proposed to perceive the degradation degree of contrast and details in low-light images. To adaptively enhance images captured under different brightness levels, BP-Net is proposed to control the recursive enhancement times of ACT-Net by exploring the image brightness distribution properties. Finally, in order to coordinate ACT-Net and BP-Net, we design a novel unsupervised training strategy to facilitate the training procedure. To further validate the effectiveness of the proposed method, we construct a new dataset with a broader brightness distribution by mixing three low-light datasets. Compared with eleven existing representative methods, the proposed method achieves new SOTA performance on six reference and no reference metrics. Specifically, the proposed method improves the PSNR by 0.9 dB compared to the existing SOTA method.
Data-free Knowledge Distillation with Diffusion Models
Apr 01, 2025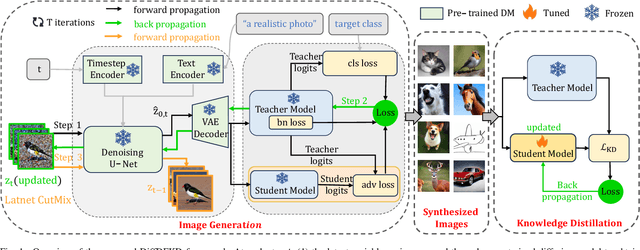
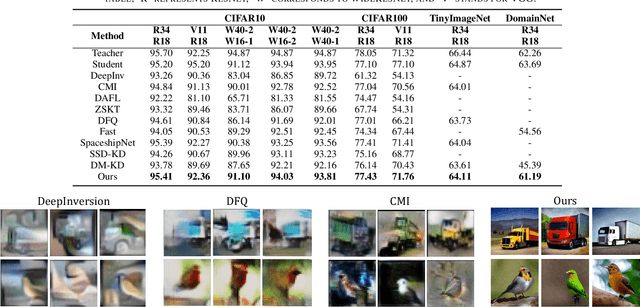
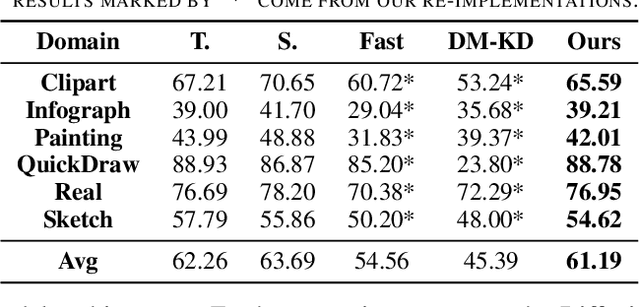

Recently Data-Free Knowledge Distillation (DFKD) has garnered attention and can transfer knowledge from a teacher neural network to a student neural network without requiring any access to training data. Although diffusion models are adept at synthesizing high-fidelity photorealistic images across various domains, existing methods cannot be easiliy implemented to DFKD. To bridge that gap, this paper proposes a novel approach based on diffusion models, DiffDFKD. Specifically, DiffDFKD involves targeted optimizations in two key areas. Firstly, DiffDFKD utilizes valuable information from teacher models to guide the pre-trained diffusion models' data synthesis, generating datasets that mirror the training data distribution and effectively bridge domain gaps. Secondly, to reduce computational burdens, DiffDFKD introduces Latent CutMix Augmentation, an efficient technique, to enhance the diversity of diffusion model-generated images for DFKD while preserving key attributes for effective knowledge transfer. Extensive experiments validate the efficacy of DiffDFKD, yielding state-of-the-art results exceeding existing DFKD approaches. We release our code at https://github.com/xhqi0109/DiffDFKD.
Pixel to Gaussian: Ultra-Fast Continuous Super-Resolution with 2D Gaussian Modeling
Mar 09, 2025Arbitrary-scale super-resolution (ASSR) aims to reconstruct high-resolution (HR) images from low-resolution (LR) inputs with arbitrary upsampling factors using a single model, addressing the limitations of traditional SR methods constrained to fixed-scale factors (\textit{e.g.}, $\times$ 2). Recent advances leveraging implicit neural representation (INR) have achieved great progress by modeling coordinate-to-pixel mappings. However, the efficiency of these methods may suffer from repeated upsampling and decoding, while their reconstruction fidelity and quality are constrained by the intrinsic representational limitations of coordinate-based functions. To address these challenges, we propose a novel ContinuousSR framework with a Pixel-to-Gaussian paradigm, which explicitly reconstructs 2D continuous HR signals from LR images using Gaussian Splatting. This approach eliminates the need for time-consuming upsampling and decoding, enabling extremely fast arbitrary-scale super-resolution. Once the Gaussian field is built in a single pass, ContinuousSR can perform arbitrary-scale rendering in just 1ms per scale. Our method introduces several key innovations. Through statistical ana
Directing Mamba to Complex Textures: An Efficient Texture-Aware State Space Model for Image Restoration
Jan 27, 2025



Image restoration aims to recover details and enhance contrast in degraded images. With the growing demand for high-quality imaging (\textit{e.g.}, 4K and 8K), achieving a balance between restoration quality and computational efficiency has become increasingly critical. Existing methods, primarily based on CNNs, Transformers, or their hybrid approaches, apply uniform deep representation extraction across the image. However, these methods often struggle to effectively model long-range dependencies and largely overlook the spatial characteristics of image degradation (regions with richer textures tend to suffer more severe damage), making it hard to achieve the best trade-off between restoration quality and efficiency. To address these issues, we propose a novel texture-aware image restoration method, TAMambaIR, which simultaneously perceives image textures and achieves a trade-off between performance and efficiency. Specifically, we introduce a novel Texture-Aware State Space Model, which enhances texture awareness and improves efficiency by modulating the transition matrix of the state-space equation and focusing on regions with complex textures. Additionally, we design a {Multi-Directional Perception Block} to improve multi-directional receptive fields while maintaining low computational overhead. Extensive experiments on benchmarks for image super-resolution, deraining, and low-light image enhancement demonstrate that TAMambaIR achieves state-of-the-art performance with significantly improved efficiency, establishing it as a robust and efficient framework for image restoration.
How to Complete Domain Tuning while Keeping General Ability in LLM: Adaptive Layer-wise and Element-wise Regularization
Jan 23, 2025Large Language Models (LLMs) exhibit strong general-purpose language capabilities. However, fine-tuning these models on domain-specific tasks often leads to catastrophic forgetting, where the model overwrites or loses essential knowledge acquired during pretraining. This phenomenon significantly limits the broader applicability of LLMs. To address this challenge, we propose a novel approach to compute the element-wise importance of model parameters crucial for preserving general knowledge during fine-tuning. Our method utilizes a dual-objective optimization strategy: (1) regularization loss to retain the parameter crucial for general knowledge; (2) cross-entropy loss to adapt to domain-specific tasks. Additionally, we introduce layer-wise coefficients to account for the varying contributions of different layers, dynamically balancing the dual-objective optimization. Extensive experiments on scientific, medical, and physical tasks using GPT-J and LLaMA-3 demonstrate that our approach mitigates catastrophic forgetting while enhancing model adaptability. Compared to previous methods, our solution is approximately 20 times faster and requires only 10%-15% of the storage, highlighting the practical efficiency. The code will be released.
Beyond Pixels: Text Enhances Generalization in Real-World Image Restoration
Dec 01, 2024



Generalization has long been a central challenge in real-world image restoration. While recent diffusion-based restoration methods, which leverage generative priors from text-to-image models, have made progress in recovering more realistic details, they still encounter "generative capability deactivation" when applied to out-of-distribution real-world data. To address this, we propose using text as an auxiliary invariant representation to reactivate the generative capabilities of these models. We begin by identifying two key properties of text input: richness and relevance, and examine their respective influence on model performance. Building on these insights, we introduce Res-Captioner, a module that generates enhanced textual descriptions tailored to image content and degradation levels, effectively mitigating response failures. Additionally, we present RealIR, a new benchmark designed to capture diverse real-world scenarios. Extensive experiments demonstrate that Res-Captioner significantly enhances the generalization abilities of diffusion-based restoration models, while remaining fully plug-and-play.