 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaCuRL: Adaptive Curriculum Reinforcement Learning with Invalid Sample Mitigation and Historical Revisiting
Nov 12, 2025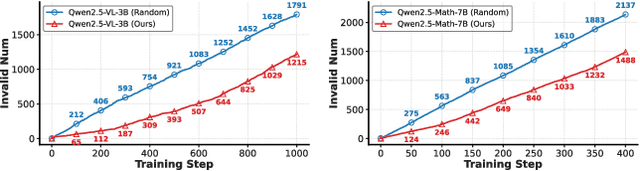
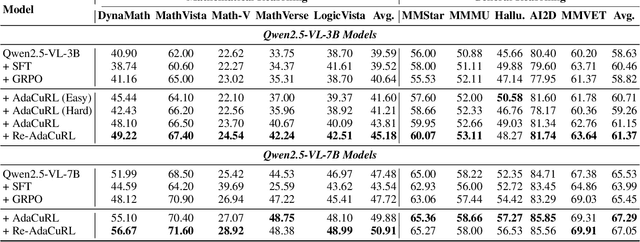
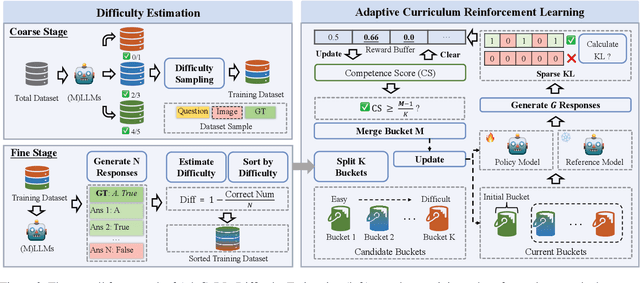
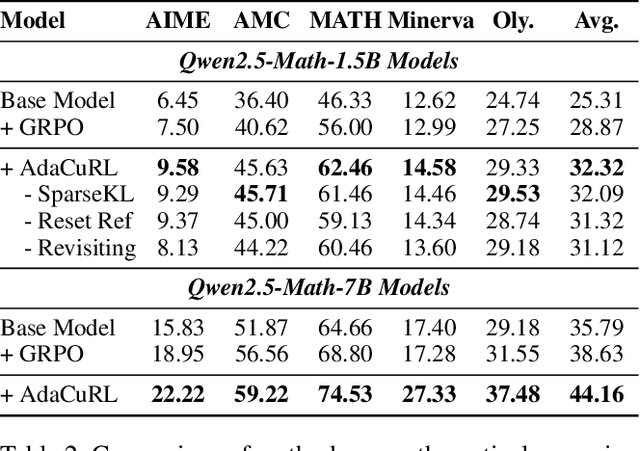
Reinforcement learning (RL) has demonstrated considerable potential for enhancing reasoning in large language models (LLMs). However, existing methods suffer from Gradient Starvation and Policy Degradation when training directly on samples with mixed difficulty. To mitigate this, prior approaches leverage Chain-of-Thought (CoT) data, but the construction of high-quality CoT annotations remains labor-intensive. Alternatively, curriculum learning strategies have been explored but frequently encounter challenges, such as difficulty mismatch, reliance on manual curriculum design, and catastrophic forgetting. To address these issues, we propose AdaCuRL, a Adaptive Curriculum Reinforcement Learning framework that integrates coarse-to-fine difficulty estimation with adaptive curriculum scheduling. This approach dynamically aligns data difficulty with model capability and incorporates a data revisitation mechanism to mitigate catastrophic forgetting. Furthermore, AdaCuRL employs adaptive reference and sparse KL strategies to prevent Policy Degradation. Extensive experiments across diverse reasoning benchmarks demonstrate that AdaCuRL consistently achieves significant performance improvements on both LLMs and MLLMs.
EasyGenNet: An Efficient Framework for Audio-Driven Gesture Video Generation Based on Diffusion Model
Apr 11, 2025Audio-driven cospeech video generation typically involves two stages: speech-to-gesture and gesture-to-video. While significant advances have been made in speech-to-gesture generation, synthesizing natural expressions and gestures remains challenging in gesture-to-video systems. In order to improve the generation effect, previous works adopted complex input and training strategies and required a large amount of data sets for pre-training, which brought inconvenience to practical applications. We propose a simple one-stage training method and a temporal inference method based on a diffusion model to synthesize realistic and continuous gesture videos without the need for additional training of temporal modules.The entire model makes use of existing pre-trained weights, and only a few thousand frames of data are needed for each character at a time to complete fine-tuning. Built upon the video generator, we introduce a new audio-to-video pipeline to synthesize co-speech videos, using 2D human skeleton as the intermediate motion representation. Our experiments show that our method outperforms existing GAN-based and diffusion-based methods.
Data-free Knowledge Distillation with Diffusion Models
Apr 01, 2025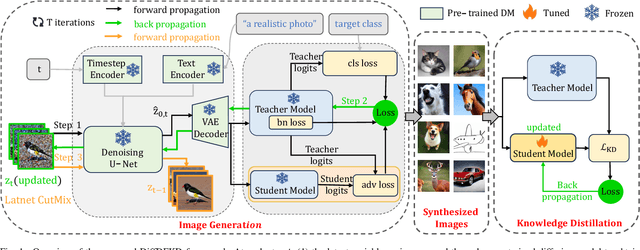
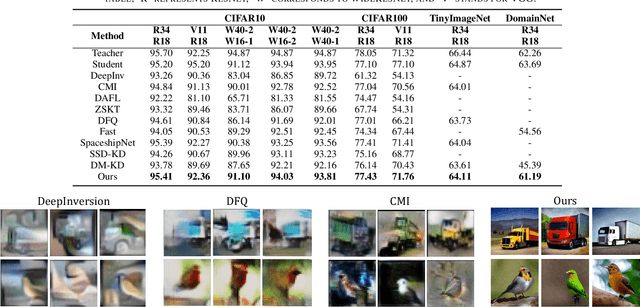
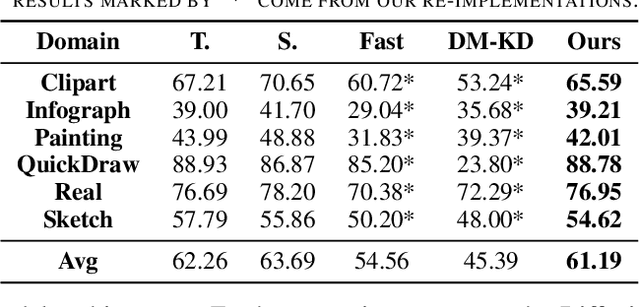

Recently Data-Free Knowledge Distillation (DFKD) has garnered attention and can transfer knowledge from a teacher neural network to a student neural network without requiring any access to training data. Although diffusion models are adept at synthesizing high-fidelity photorealistic images across various domains, existing methods cannot be easiliy implemented to DFKD. To bridge that gap, this paper proposes a novel approach based on diffusion models, DiffDFKD. Specifically, DiffDFKD involves targeted optimizations in two key areas. Firstly, DiffDFKD utilizes valuable information from teacher models to guide the pre-trained diffusion models' data synthesis, generating datasets that mirror the training data distribution and effectively bridge domain gaps. Secondly, to reduce computational burdens, DiffDFKD introduces Latent CutMix Augmentation, an efficient technique, to enhance the diversity of diffusion model-generated images for DFKD while preserving key attributes for effective knowledge transfer. Extensive experiments validate the efficacy of DiffDFKD, yielding state-of-the-art results exceeding existing DFKD approaches. We release our code at https://github.com/xhqi0109/DiffDFKD.
USP: Unified Self-Supervised Pretraining for Image Generation and Understanding
Mar 08, 2025



Recent studies have highlighted the interplay between diffusion models and representation learning. Intermediate representations from diffusion models can be leveraged for downstream visual tasks, while self-supervised vision models can enhance the convergence and generation quality of diffusion models. However, transferring pretrained weights from vision models to diffusion models is challenging due to input mismatches and the use of latent spaces. To address these challenges, we propose Unified Self-supervised Pretraining (USP), a framework that initializes diffusion models via masked latent modeling in a Variational Autoencoder (VAE) latent space. USP achieves comparable performance in understanding tasks while significantly improving the convergence speed and generation quality of diffusion models. Our code will be publicly available at https://github.com/cxxgtxy/USP.
Exploring Large-scale Unlabeled Faces to Enhance Facial Expression Recognition
Mar 19, 2023Facial Expression Recognition (FER) is an important task in computer vision and has wide applications in human-computer interaction, intelligent security, emotion analysis, and other fields. However, the limited size of FER datasets limits the generalization ability of expression recognition models, resulting in ineffective model performance. To address this problem, we propose a semi-supervised learning framework that utilizes unlabeled face data to train expression recognition models effectively. Our method uses a dynamic threshold module (\textbf{DTM}) that can adaptively adjust the confidence threshold to fully utilize the face recognition (FR) data to generate pseudo-labels, thus improving the model's ability to model facial expressions. In the ABAW5 EXPR task, our method achieved excellent results on the official validation set.
Local Region Perception and Relationship Learning Combined with Feature Fusion for Facial Action Unit Detection
Mar 19, 2023



Human affective behavior analysis plays a vital role in human-computer interaction (HCI) systems. In this paper, we introduce our submission to the CVPR 2023 Competition on Affective Behavior Analysis in-the-wild (ABAW). We propose a single-stage trained AU detection framework. Specifically, in order to effectively extract facial local region features related to AU detection, we use a local region perception module to effectively extract features of different AUs. Meanwhile, we use a graph neural network-based relational learning module to capture the relationship between AUs. In addition, considering the role of the overall feature of the target face on AU detection, we also use the feature fusion module to fuse the feature information extracted by the backbone network and the AU feature information extracted by the relationship learning module. We also adopted some sampling methods, data augmentation techniques and post-processing strategies to further improve the performance of the model.
A Dual Branch Network for Emotional Reaction Intensity Estimation
Mar 16, 2023Emotional Reaction Intensity(ERI) estimation is an important task in multimodal scenarios, and has fundamental applications in medicine, safe driving and other fields. In this paper, we propose a solution to the ERI challenge of the fifth Affective Behavior Analysis in-the-wild(ABAW), a dual-branch based multi-output regression model. The spatial attention is used to better extract visual features, and the Mel-Frequency Cepstral Coefficients technology extracts acoustic features, and a method named modality dropout is added to fusion multimodal features. Our method achieves excellent results on the official validation set.