 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIAR: Modality Interaction and Alignment Representation Fuison for Multimodal Emotion
Jan 03, 2026Multimodal Emotion Recognition (MER) aims to perceive human emotions through three modes: language, vision, and audio. Previous methods primarily focused on modal fusion without adequately addressing significant distributional differences among modalities or considering their varying contributions to the task. They also lacked robust generalization capabilities across diverse textual model features, thus limiting performance in multimodal scenarios. Therefore, we propose a novel approach called Modality Interaction and Alignment Representation (MIAR). This network integrates contextual features across different modalities using a feature interaction to generate feature tokens to represent global representations of this modality extracting information from other modalities. These four tokens represent global representations of how each modality extracts information from others. MIAR aligns different modalities using contrastive learning and normalization strategies. We conduct experiments on two benchmarks: CMU-MOSI and CMU-MOSEI datasets, experimental results demonstrate the MIAR outperforms state-of-the-art MER methods.
AUD-TGN: Advancing Action Unit Detection with Temporal Convolution and GPT-2 in Wild Audiovisual Contexts
Mar 20, 2024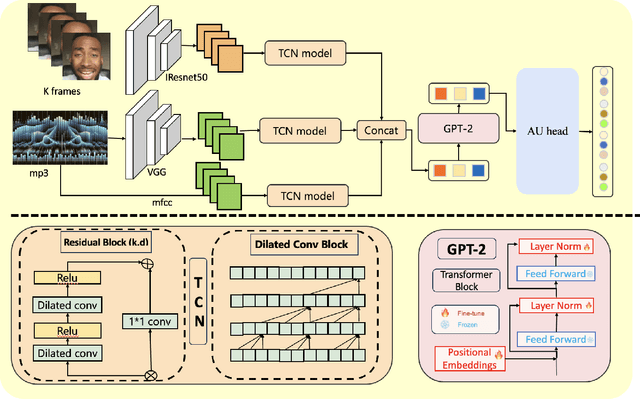
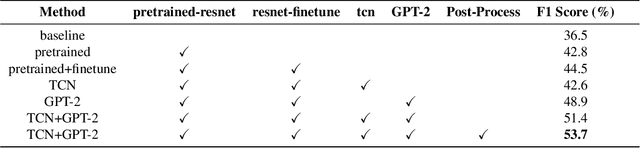
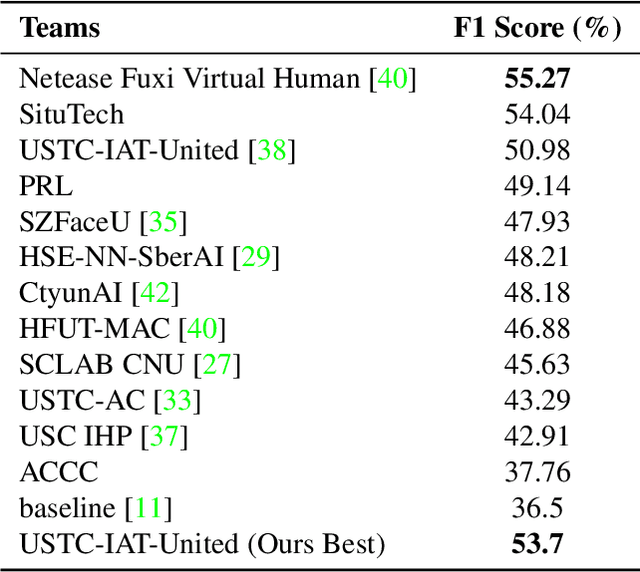
Leveraging the synergy of both audio data and visual data is essential for understanding human emotions and behaviors, especially in in-the-wild setting. Traditional methods for integrating such multimodal information often stumble, leading to less-than-ideal outcomes in the task of facial action unit detection. To overcome these shortcomings, we propose a novel approach utilizing audio-visual multimodal data. This method enhances audio feature extraction by leveraging Mel Frequency Cepstral Coefficients (MFCC) and Log-Mel spectrogram features alongside a pre-trained VGGish network. Moreover, this paper adaptively captures fusion features across modalities by modeling the temporal relationships, and ultilizes a pre-trained GPT-2 model for sophisticated context-aware fusion of multimodal information. Our method notably improves the accuracy of AU detection by understanding the temporal and contextual nuances of the data, showcasing significant advancements in the comprehension of intricate scenarios. These findings underscore the potential of integrating temporal dynamics and contextual interpretation, paving the way for future research endeavors.
Multimodal Fusion Method with Spatiotemporal Sequences and Relationship Learning for Valence-Arousal Estimation
Mar 20, 2024


This paper presents our approach for the VA (Valence-Arousal) estimation task in the ABAW6 competition. We devised a comprehensive model by preprocessing video frames and audio segments to extract visual and audio features. Through the utilization of Temporal Convolutional Network (TCN) modules, we effectively captured the temporal and spatial correlations between these features. Subsequently, we employed a Transformer encoder structure to learn long-range dependencies, thereby enhancing the model's performance and generalization ability. Our method leverages a multimodal data fusion approach, integrating pre-trained audio and video backbones for feature extraction, followed by TCN-based spatiotemporal encoding and Transformer-based temporal information capture. Experimental results demonstrate the effectiveness of our approach, achieving competitive performance in VA estimation on the AffWild2 dataset.
Efficient Feature Extraction and Late Fusion Strategy for Audiovisual Emotional Mimicry Intensity Estimation
Mar 19, 2024
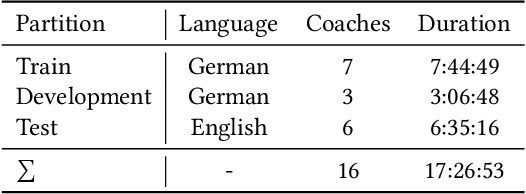
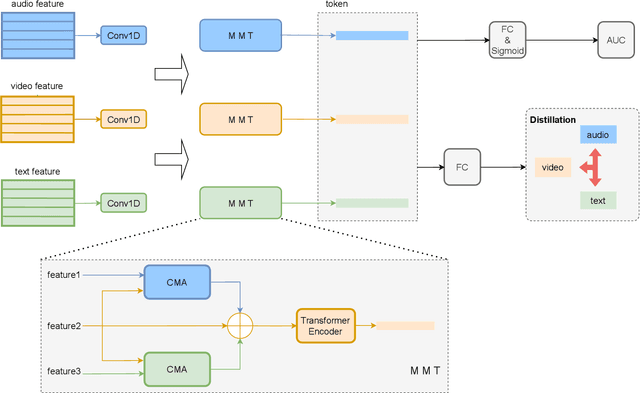
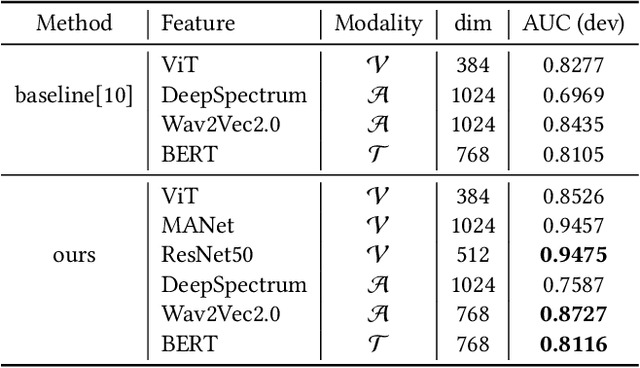
In this paper, we present the solution to the Emotional Mimicry Intensity (EMI) Estimation challenge, which is part of 6th Affective Behavior Analysis in-the-wild (ABAW) Competition.The EMI Estimation challenge task aims to evaluate the emotional intensity of seed videos by assessing them from a set of predefined emotion categories (i.e., "Admiration", "Amusement", "Determination", "Empathic Pain", "Excitement" and "Joy"). To tackle this challenge, we extracted rich dual-channel visual features based on ResNet18 and AUs for the video modality and effective single-channel features based on Wav2Vec2.0 for the audio modality. This allowed us to obtain comprehensive emotional features for the audiovisual modality. Additionally, leveraging a late fusion strategy, we averaged the predictions of the visual and acoustic models, resulting in a more accurate estimation of audiovisual emotional mimicry intensity. Experimental results validate the effectiveness of our approach, with the average Pearson's correlation Coefficient($\rho$) across the 6 emotion dimensionson the validation set achieving 0.3288.
Compound Expression Recognition via Multi Model Ensemble
Mar 19, 2024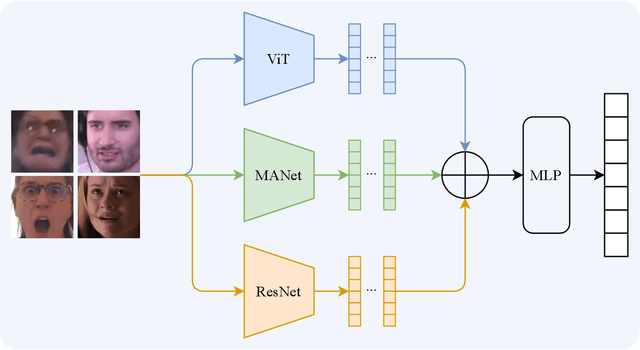
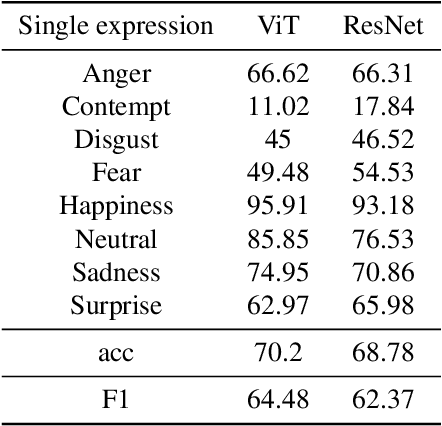
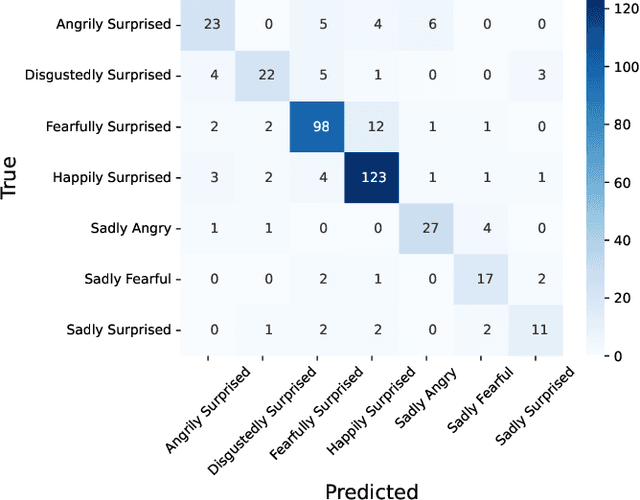
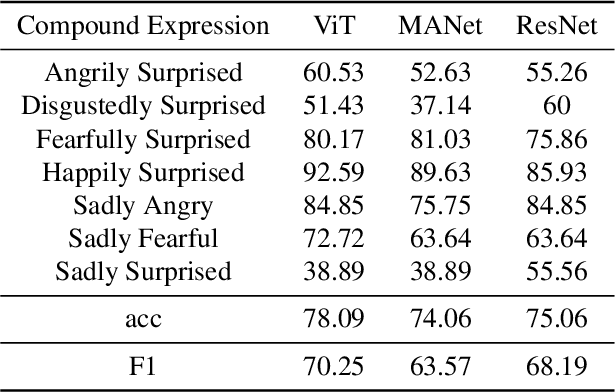
Compound Expression Recognition (CER) plays a crucial role in interpersonal interactions. Due to the existence of Compound Expressions , human emotional expressions are complex, requiring consideration of both local and global facial expressions to make judgments. In this paper, to address this issue, we propose a solution based on ensemble learning methods for Compound Expression Recognition. Specifically, our task is classification, where we train three expression classification models based on convolutional networks, Vision Transformers, and multi-scale local attention networks. Then, through model ensemble using late fusion, we merge the outputs of multiple models to predict the final result. Our method achieves high accuracy on RAF-DB and is able to recognize expressions through zero-shot on certain portions of C-EXPR-DB.
Exploring Facial Expression Recognition through Semi-Supervised Pretraining and Temporal Modeling
Mar 19, 2024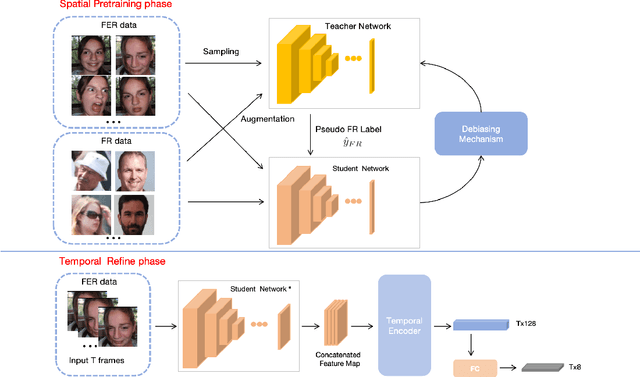

Facial Expression Recognition (FER) plays a crucial role in computer vision and finds extensive applications across various fields. This paper aims to present our approach for the upcoming 6th Affective Behavior Analysis in-the-Wild (ABAW) competition, scheduled to be held at CVPR2024. In the facial expression recognition task, The limited size of the FER dataset poses a challenge to the expression recognition model's generalization ability, resulting in subpar recognition performance. To address this problem, we employ a semi-supervised learning technique to generate expression category pseudo-labels for unlabeled face data. At the same time, we uniformly sampled the labeled facial expression samples and implemented a debiased feedback learning strategy to address the problem of category imbalance in the dataset and the possible data bias in semi-supervised learning. Moreover, to further compensate for the limitation and bias of features obtained only from static images, we introduced a Temporal Encoder to learn and capture temporal relationships between neighbouring expression image features. In the 6th ABAW competition, our method achieved outstanding results on the official validation set, a result that fully confirms the effectiveness and competitiveness of our proposed method.
ICHPro: Intracerebral Hemorrhage Prognosis Classification Via Joint-attention Fusion-based 3d Cross-modal Network
Feb 17, 2024
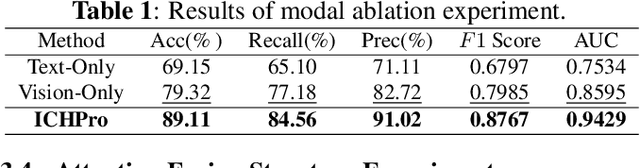

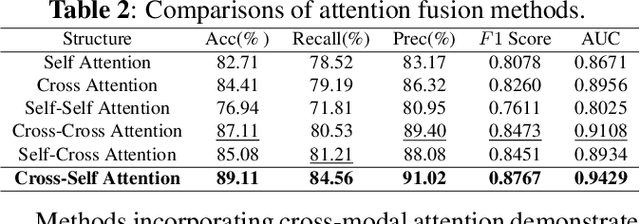
Intracerebral Hemorrhage (ICH) is the deadliest subtype of stroke, necessitating timely and accurate prognostic evaluation to reduce mortality and disability. However, the multi-factorial nature and complexity of ICH make methods based solely on computed tomography (CT) image features inadequate. Despite the capacity of cross-modal networks to fuse additional information, the effective combination of different modal features remains a significant challenge. In this study, we propose a joint-attention fusion-based 3D cross-modal network termed ICHPro that simulates the ICH prognosis interpretation process utilized by neurosurgeons. ICHPro includes a joint-attention fusion module to fuse features from CT images with demographic and clinical textual data. To enhance the representation of cross-modal features, we introduce a joint loss function. ICHPro facilitates the extraction of richer cross-modal features, thereby improving classification performance. Upon testing our method using a five-fold cross-validation, we achieved an accuracy of 89.11%, an F1 score of 0.8767, and an AUC value of 0.9429. These results outperform those obtained from other advanced methods based on the test dataset, thereby demonstrating the superior efficacy of ICHPro. The code is available at our Github: https://github.com/YU-deep/ICH.
GCS-ICHNet: Assessment of Intracerebral Hemorrhage Prognosis using Self-Attention with Domain Knowledge Integration
Nov 08, 2023



Intracerebral Hemorrhage (ICH) is a severe condition resulting from damaged brain blood vessel ruptures, often leading to complications and fatalities. Timely and accurate prognosis and management are essential due to its high mortality rate. However, conventional methods heavily rely on subjective clinician expertise, which can lead to inaccurate diagnoses and delays in treatment. Artificial intelligence (AI) models have been explored to assist clinicians, but many prior studies focused on model modification without considering domain knowledge. This paper introduces a novel deep learning algorithm, GCS-ICHNet, which integrates multimodal brain CT image data and the Glasgow Coma Scale (GCS) score to improve ICH prognosis. The algorithm utilizes a transformer-based fusion module for assessment. GCS-ICHNet demonstrates high sensitivity 81.03% and specificity 91.59%, outperforming average clinicians and other state-of-the-art methods.
Exploring Large-scale Unlabeled Faces to Enhance Facial Expression Recognition
Mar 19, 2023Facial Expression Recognition (FER) is an important task in computer vision and has wide applications in human-computer interaction, intelligent security, emotion analysis, and other fields. However, the limited size of FER datasets limits the generalization ability of expression recognition models, resulting in ineffective model performance. To address this problem, we propose a semi-supervised learning framework that utilizes unlabeled face data to train expression recognition models effectively. Our method uses a dynamic threshold module (\textbf{DTM}) that can adaptively adjust the confidence threshold to fully utilize the face recognition (FR) data to generate pseudo-labels, thus improving the model's ability to model facial expressions. In the ABAW5 EXPR task, our method achieved excellent results on the official validation set.
Local Region Perception and Relationship Learning Combined with Feature Fusion for Facial Action Unit Detection
Mar 19, 2023



Human affective behavior analysis plays a vital role in human-computer interaction (HCI) systems. In this paper, we introduce our submission to the CVPR 2023 Competition on Affective Behavior Analysis in-the-wild (ABAW). We propose a single-stage trained AU detection framework. Specifically, in order to effectively extract facial local region features related to AU detection, we use a local region perception module to effectively extract features of different AUs. Meanwhile, we use a graph neural network-based relational learning module to capture the relationship between AUs. In addition, considering the role of the overall feature of the target face on AU detection, we also use the feature fusion module to fuse the feature information extracted by the backbone network and the AU feature information extracted by the relationship learning module. We also adopted some sampling methods, data augmentation techniques and post-processing strategies to further improve the performance of the model.