 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Fusion Method with Spatiotemporal Sequences and Relationship Learning for Valence-Arousal Estimation
Mar 20, 2024


This paper presents our approach for the VA (Valence-Arousal) estimation task in the ABAW6 competition. We devised a comprehensive model by preprocessing video frames and audio segments to extract visual and audio features. Through the utilization of Temporal Convolutional Network (TCN) modules, we effectively captured the temporal and spatial correlations between these features. Subsequently, we employed a Transformer encoder structure to learn long-range dependencies, thereby enhancing the model's performance and generalization ability. Our method leverages a multimodal data fusion approach, integrating pre-trained audio and video backbones for feature extraction, followed by TCN-based spatiotemporal encoding and Transformer-based temporal information capture. Experimental results demonstrate the effectiveness of our approach, achieving competitive performance in VA estimation on the AffWild2 dataset.
AUD-TGN: Advancing Action Unit Detection with Temporal Convolution and GPT-2 in Wild Audiovisual Contexts
Mar 20, 2024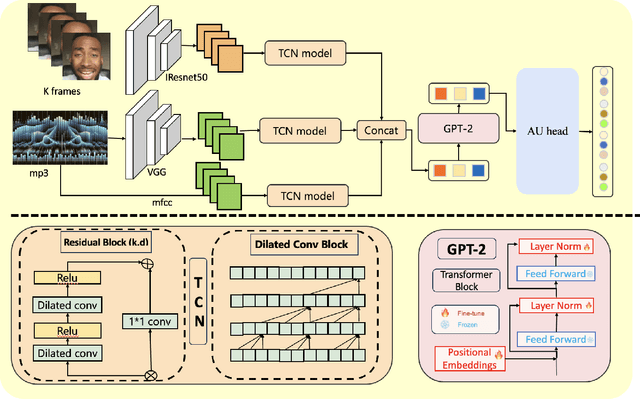
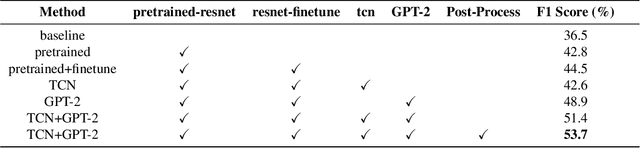
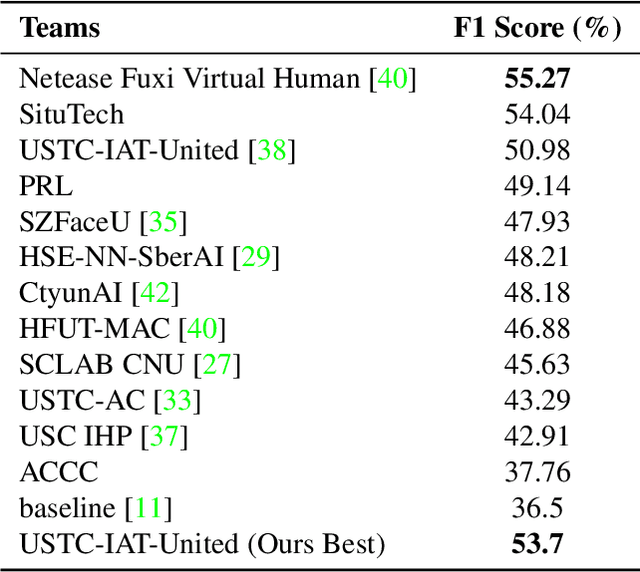
Leveraging the synergy of both audio data and visual data is essential for understanding human emotions and behaviors, especially in in-the-wild setting. Traditional methods for integrating such multimodal information often stumble, leading to less-than-ideal outcomes in the task of facial action unit detection. To overcome these shortcomings, we propose a novel approach utilizing audio-visual multimodal data. This method enhances audio feature extraction by leveraging Mel Frequency Cepstral Coefficients (MFCC) and Log-Mel spectrogram features alongside a pre-trained VGGish network. Moreover, this paper adaptively captures fusion features across modalities by modeling the temporal relationships, and ultilizes a pre-trained GPT-2 model for sophisticated context-aware fusion of multimodal information. Our method notably improves the accuracy of AU detection by understanding the temporal and contextual nuances of the data, showcasing significant advancements in the comprehension of intricate scenarios. These findings underscore the potential of integrating temporal dynamics and contextual interpretation, paving the way for future research endeavors.
Exploring Facial Expression Recognition through Semi-Supervised Pretraining and Temporal Modeling
Mar 19, 2024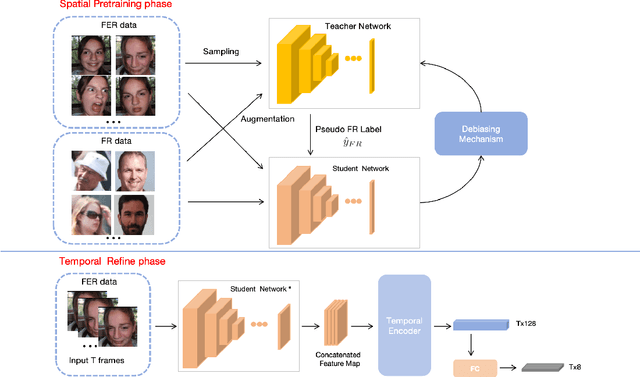

Facial Expression Recognition (FER) plays a crucial role in computer vision and finds extensive applications across various fields. This paper aims to present our approach for the upcoming 6th Affective Behavior Analysis in-the-Wild (ABAW) competition, scheduled to be held at CVPR2024. In the facial expression recognition task, The limited size of the FER dataset poses a challenge to the expression recognition model's generalization ability, resulting in subpar recognition performance. To address this problem, we employ a semi-supervised learning technique to generate expression category pseudo-labels for unlabeled face data. At the same time, we uniformly sampled the labeled facial expression samples and implemented a debiased feedback learning strategy to address the problem of category imbalance in the dataset and the possible data bias in semi-supervised learning. Moreover, to further compensate for the limitation and bias of features obtained only from static images, we introduced a Temporal Encoder to learn and capture temporal relationships between neighbouring expression image features. In the 6th ABAW competition, our method achieved outstanding results on the official validation set, a result that fully confirms the effectiveness and competitiveness of our proposed method.
SAR2EO: A High-resolution Image Translation Framework with Denoising Enhancement
Apr 08, 2023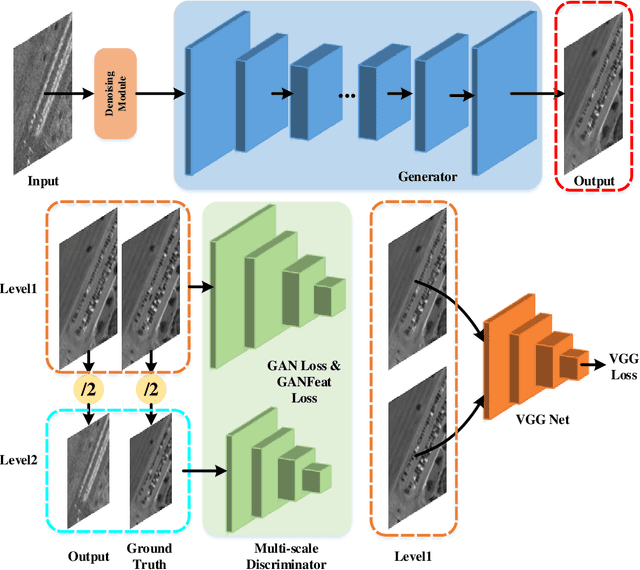
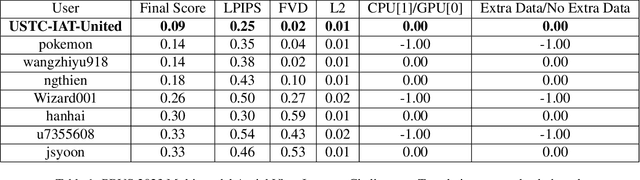

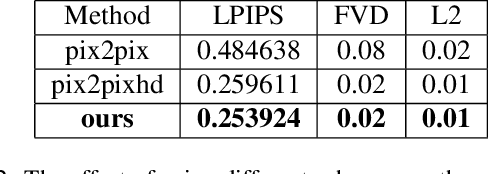
Synthetic Aperture Radar (SAR) to electro-optical (EO) image translation is a fundamental task in remote sensing that can enrich the dataset by fusing information from different sources. Recently, many methods have been proposed to tackle this task, but they are still difficult to complete the conversion from low-resolution images to high-resolution images. Thus, we propose a framework, SAR2EO, aiming at addressing this challenge. Firstly, to generate high-quality EO images, we adopt the coarse-to-fine generator, multi-scale discriminators, and improved adversarial loss in the pix2pixHD model to increase the synthesis quality. Secondly, we introduce a denoising module to remove the noise in SAR images, which helps to suppress the noise while preserving the structural information of the images. To validate the effectiveness of the proposed framework, we conduct experiments on the dataset of the Multi-modal Aerial View Imagery Challenge (MAVIC), which consists of large-scale SAR and EO image pairs. The experimental results demonstrate the superiority of our proposed framework, and we win the first place in the MAVIC held in CVPR PBVS 2023.
Local Region Perception and Relationship Learning Combined with Feature Fusion for Facial Action Unit Detection
Mar 19, 2023



Human affective behavior analysis plays a vital role in human-computer interaction (HCI) systems. In this paper, we introduce our submission to the CVPR 2023 Competition on Affective Behavior Analysis in-the-wild (ABAW). We propose a single-stage trained AU detection framework. Specifically, in order to effectively extract facial local region features related to AU detection, we use a local region perception module to effectively extract features of different AUs. Meanwhile, we use a graph neural network-based relational learning module to capture the relationship between AUs. In addition, considering the role of the overall feature of the target face on AU detection, we also use the feature fusion module to fuse the feature information extracted by the backbone network and the AU feature information extracted by the relationship learning module. We also adopted some sampling methods, data augmentation techniques and post-processing strategies to further improve the performance of the model.
Exploring Large-scale Unlabeled Faces to Enhance Facial Expression Recognition
Mar 19, 2023Facial Expression Recognition (FER) is an important task in computer vision and has wide applications in human-computer interaction, intelligent security, emotion analysis, and other fields. However, the limited size of FER datasets limits the generalization ability of expression recognition models, resulting in ineffective model performance. To address this problem, we propose a semi-supervised learning framework that utilizes unlabeled face data to train expression recognition models effectively. Our method uses a dynamic threshold module (\textbf{DTM}) that can adaptively adjust the confidence threshold to fully utilize the face recognition (FR) data to generate pseudo-labels, thus improving the model's ability to model facial expressions. In the ABAW5 EXPR task, our method achieved excellent results on the official validation set.
A Dual Branch Network for Emotional Reaction Intensity Estimation
Mar 16, 2023Emotional Reaction Intensity(ERI) estimation is an important task in multimodal scenarios, and has fundamental applications in medicine, safe driving and other fields. In this paper, we propose a solution to the ERI challenge of the fifth Affective Behavior Analysis in-the-wild(ABAW), a dual-branch based multi-output regression model. The spatial attention is used to better extract visual features, and the Mel-Frequency Cepstral Coefficients technology extracts acoustic features, and a method named modality dropout is added to fusion multimodal features. Our method achieves excellent results on the official validation set.
BiSTF: Bilateral-Branch Self-Training Framework for Semi-Supervised Large-scale Fine-Grained Recognition
Jul 14, 2021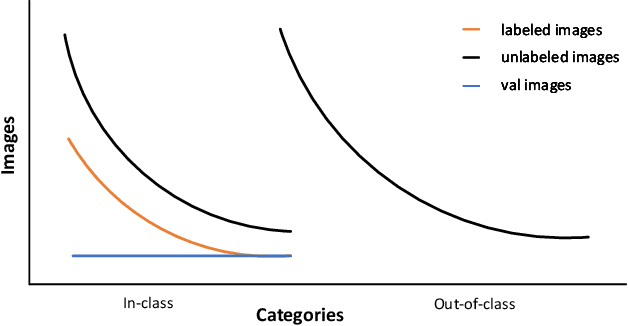
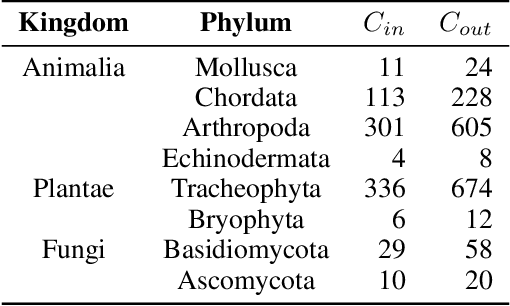
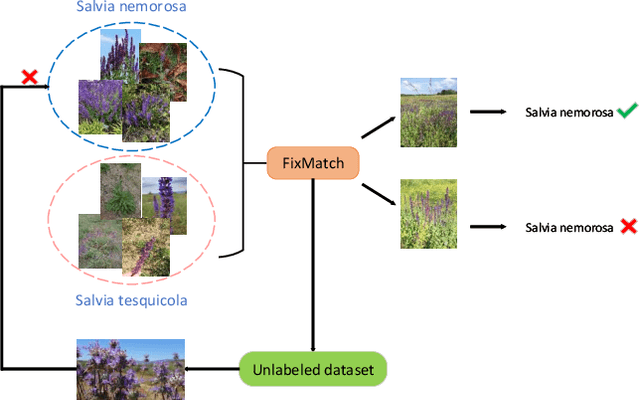
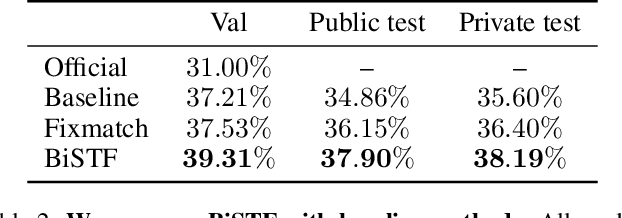
Semi-supervised Fine-Grained Recognition is a challenge task due to the difficulty of data imbalance, high inter-class similarity and domain mismatch. Recent years, this field has witnessed great progress and many methods has gained great performance. However, these methods can hardly generalize to the large-scale datasets, such as Semi-iNat, as they are prone to suffer from noise in unlabeled data and the incompetence for learning features from imbalanced fine-grained data. In this work, we propose Bilateral-Branch Self-Training Framework (BiSTF), a simple yet effective framework to improve existing semi-supervised learning methods on class-imbalanced and domain-shifted fine-grained data. By adjusting the update frequency through stochastic epoch update, BiSTF iteratively retrains a baseline SSL model with a labeled set expanded by selectively adding pseudo-labeled samples from an unlabeled set, where the distribution of pseudo-labeled samples are the same as the labeled data. We show that BiSTF outperforms the existing state-of-the-art SSL algorithm on Semi-iNat dataset.
Deep Fusion Siamese Network for Automatic Kinship Verification
Jun 07, 2020

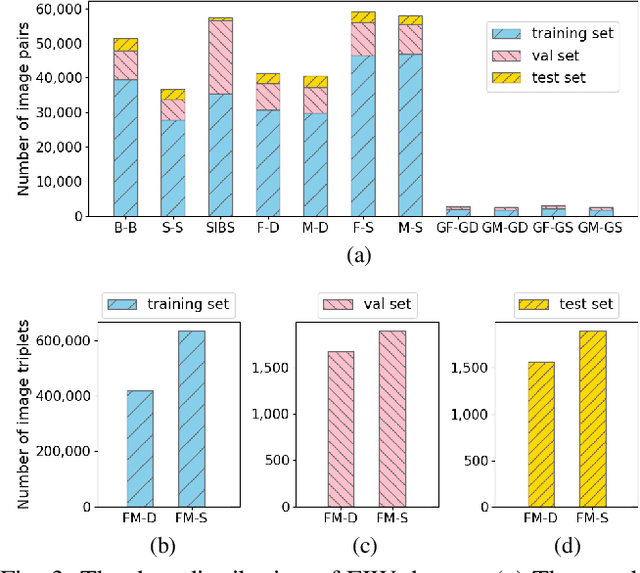
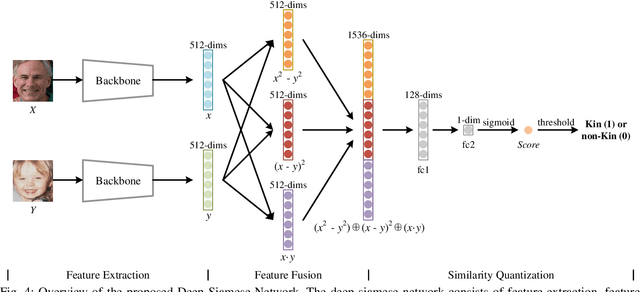
Automatic kinship verification aims to determine whether some individuals belong to the same family. It is of great research significance to help missing persons reunite with their families. In this work, the challenging problem is progressively addressed in two respects. First, we propose a deep siamese network to quantify the relative similarity between two individuals. When given two input face images, the deep siamese network extracts the features from them and fuses these features by combining and concatenating. Then, the fused features are fed into a fully-connected network to obtain the similarity score between two faces, which is used to verify the kinship. To improve the performance, a jury system is also employed for multi-model fusion. Second, two deep siamese networks are integrated into a deep triplet network for tri-subject (i.e., father, mother and child) kinship verification, which is intended to decide whether a child is related to a pair of parents or not. Specifically, the obtained similarity scores of father-child and mother-child are weighted to generate the parent-child similarity score for kinship verification. Recognizing Families In the Wild (RFIW) is a challenging kinship recognition task with multiple tracks, which is based on Families in the Wild (FIW), a large-scale and comprehensive image database for automatic kinship recognition. The Kinship Verification (track I) and Tri-Subject Verification (track II) are supported during the ongoing RFIW2020 Challenge. Our team (ustc-nelslip) ranked 1st in track II, and 3rd in track I. The code is available at https://github.com/gniknoil/FG2020-kinship.
* 8 pages, 8 figures
Retrieval of Family Members Using Siamese Neural Network
May 30, 2020
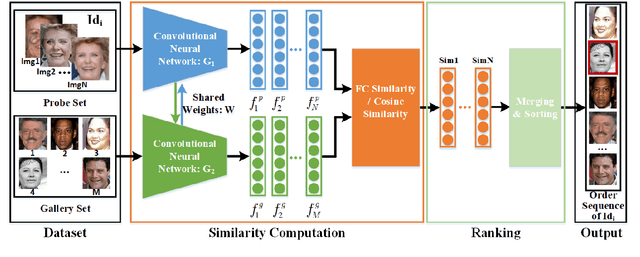
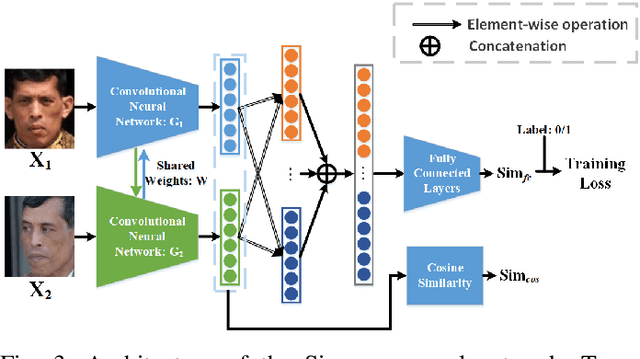
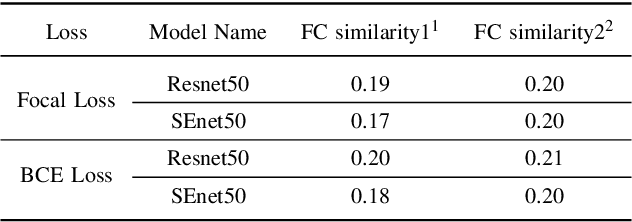
Retrieval of family members in the wild aims at finding family members of the given subject in the dataset, which is useful in finding the lost children and analyzing the kinship. However, due to the diversity in age, gender, pose and illumination of the collected data, this task is always challenging. To solve this problem, we propose our solution with deep Siamese neural network. Our solution can be divided into two parts: similarity computation and ranking. In training procedure, the Siamese network firstly takes two candidate images as input and produces two feature vectors. And then, the similarity between the two vectors is computed with several fully connected layers. While in inference procedure, we try another similarity computing method by dropping the followed several fully connected layers and directly computing the cosine similarity of the two feature vectors. After similarity computation, we use the ranking algorithm to merge the similarity scores with the same identity and output the ordered list according to their similarities. To gain further improvement, we try different combinations of backbones, training methods and similarity computing methods. Finally, we submit the best combination as our solution and our team(ustc-nelslip) obtains favorable result in the track3 of the RFIW2020 challenge with the first runner-up, which verifies the effectiveness of our method. Our code is available at: https://github.com/gniknoil/FG2020-kinship