 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiVid-Narrator: Hierarchical Video Narrative Generation with Scene-Primed ASR-anchored Compression
Jan 12, 2026Generating structured narrations for real-world e-commerce videos requires models to perceive fine-grained visual details and organize them into coherent, high-level stories--capabilities that existing approaches struggle to unify. We introduce the E-commerce Hierarchical Video Captioning (E-HVC) dataset with dual-granularity, temporally grounded annotations: a Temporal Chain-of-Thought that anchors event-level observations and Chapter Summary that compose them into concise, story-centric summaries. Rather than directly prompting chapters, we adopt a staged construction that first gathers reliable linguistic and visual evidence via curated ASR and frame-level descriptions, then refines coarse annotations into precise chapter boundaries and titles conditioned on the Temporal Chain-of-Thought, yielding fact-grounded, time-aligned narratives. We also observe that e-commerce videos are fast-paced and information-dense, with visual tokens dominating the input sequence. To enable efficient training while reducing input tokens, we propose the Scene-Primed ASR-anchored Compressor (SPA-Compressor), which compresses multimodal tokens into hierarchical scene and event representations guided by ASR semantic cues. Built upon these designs, our HiVid-Narrator framework achieves superior narrative quality with fewer input tokens compared to existing methods.
Semi-supervised Clustering Through Representation Learning of Large-scale EHR Data
May 27, 2025Electronic Health Records (EHR) offer rich real-world data for personalized medicine, providing insights into disease progression, treatment responses, and patient outcomes. However, their sparsity, heterogeneity, and high dimensionality make them difficult to model, while the lack of standardized ground truth further complicates predictive modeling. To address these challenges, we propose SCORE, a semi-supervised representation learning framework that captures multi-domain disease profiles through patient embeddings. SCORE employs a Poisson-Adapted Latent factor Mixture (PALM) Model with pre-trained code embeddings to characterize codified features and extract meaningful patient phenotypes and embeddings. To handle the computational challenges of large-scale data, it introduces a hybrid Expectation-Maximization (EM) and Gaussian Variational Approximation (GVA) algorithm, leveraging limited labeled data to refine estimates on a vast pool of unlabeled samples. We theoretically establish the convergence of this hybrid approach, quantify GVA errors, and derive SCORE's error rate under diverging embedding dimensions. Our analysis shows that incorporating unlabeled data enhances accuracy and reduces sensitivity to label scarcity. Extensive simulations confirm SCORE's superior finite-sample performance over existing methods. Finally, we apply SCORE to predict disability status for patients with multiple sclerosis (MS) using partially labeled EHR data, demonstrating that it produces more informative and predictive patient embeddings for multiple MS-related conditions compared to existing approaches.
DATE: Domain Adaptive Product Seeker for E-commerce
Apr 07, 2023



Product Retrieval (PR) and Grounding (PG), aiming to seek image and object-level products respectively according to a textual query, have attracted great interest recently for better shopping experience. Owing to the lack of relevant datasets, we collect two large-scale benchmark datasets from Taobao Mall and Live domains with about 474k and 101k image-query pairs for PR, and manually annotate the object bounding boxes in each image for PG. As annotating boxes is expensive and time-consuming, we attempt to transfer knowledge from annotated domain to unannotated for PG to achieve un-supervised Domain Adaptation (PG-DA). We propose a {\bf D}omain {\bf A}daptive Produc{\bf t} S{\bf e}eker ({\bf DATE}) framework, regarding PR and PG as Product Seeking problem at different levels, to assist the query {\bf date} the product. Concretely, we first design a semantics-aggregated feature extractor for each modality to obtain concentrated and comprehensive features for following efficient retrieval and fine-grained grounding tasks. Then, we present two cooperative seekers to simultaneously search the image for PR and localize the product for PG. Besides, we devise a domain aligner for PG-DA to alleviate uni-modal marginal and multi-modal conditional distribution shift between source and target domains, and design a pseudo box generator to dynamically select reliable instances and generate bounding boxes for further knowledge transfer. Extensive experiments show that our DATE achieves satisfactory performance in fully-supervised PR, PG and un-supervised PG-DA. Our desensitized datasets will be publicly available here\footnote{\url{https://github.com/Taobao-live/Product-Seeking}}.
Deep Fusion Siamese Network for Automatic Kinship Verification
Jun 07, 2020

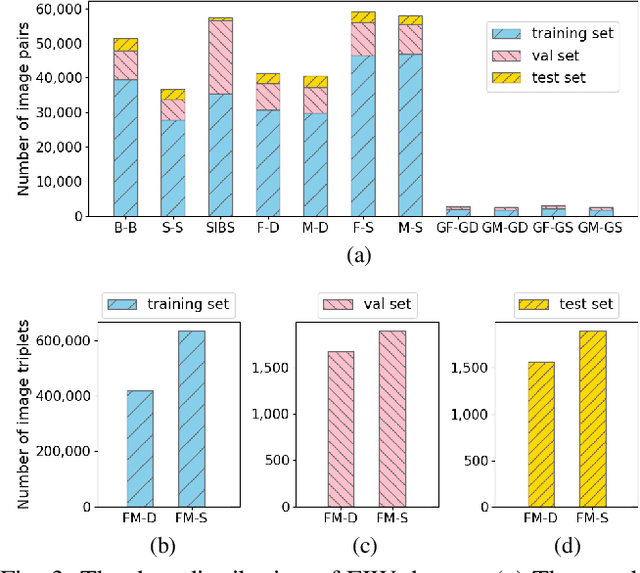
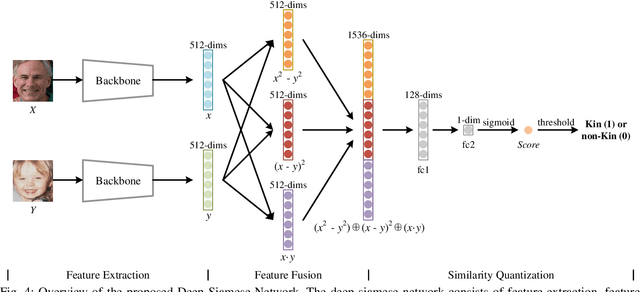
Automatic kinship verification aims to determine whether some individuals belong to the same family. It is of great research significance to help missing persons reunite with their families. In this work, the challenging problem is progressively addressed in two respects. First, we propose a deep siamese network to quantify the relative similarity between two individuals. When given two input face images, the deep siamese network extracts the features from them and fuses these features by combining and concatenating. Then, the fused features are fed into a fully-connected network to obtain the similarity score between two faces, which is used to verify the kinship. To improve the performance, a jury system is also employed for multi-model fusion. Second, two deep siamese networks are integrated into a deep triplet network for tri-subject (i.e., father, mother and child) kinship verification, which is intended to decide whether a child is related to a pair of parents or not. Specifically, the obtained similarity scores of father-child and mother-child are weighted to generate the parent-child similarity score for kinship verification. Recognizing Families In the Wild (RFIW) is a challenging kinship recognition task with multiple tracks, which is based on Families in the Wild (FIW), a large-scale and comprehensive image database for automatic kinship recognition. The Kinship Verification (track I) and Tri-Subject Verification (track II) are supported during the ongoing RFIW2020 Challenge. Our team (ustc-nelslip) ranked 1st in track II, and 3rd in track I. The code is available at https://github.com/gniknoil/FG2020-kinship.
* 8 pages, 8 figures
Retrieval of Family Members Using Siamese Neural Network
May 30, 2020
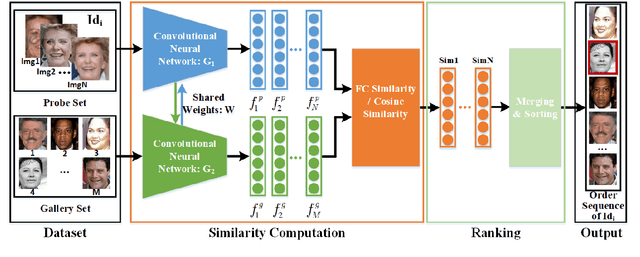
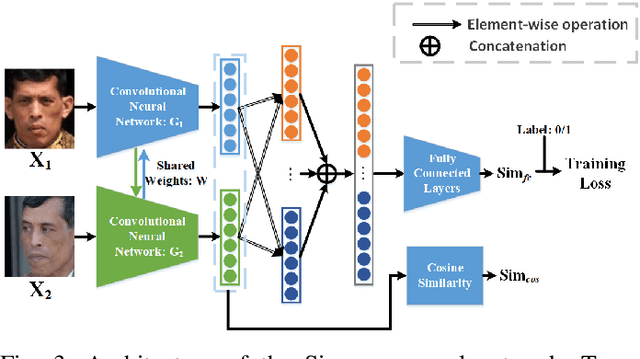
Retrieval of family members in the wild aims at finding family members of the given subject in the dataset, which is useful in finding the lost children and analyzing the kinship. However, due to the diversity in age, gender, pose and illumination of the collected data, this task is always challenging. To solve this problem, we propose our solution with deep Siamese neural network. Our solution can be divided into two parts: similarity computation and ranking. In training procedure, the Siamese network firstly takes two candidate images as input and produces two feature vectors. And then, the similarity between the two vectors is computed with several fully connected layers. While in inference procedure, we try another similarity computing method by dropping the followed several fully connected layers and directly computing the cosine similarity of the two feature vectors. After similarity computation, we use the ranking algorithm to merge the similarity scores with the same identity and output the ordered list according to their similarities. To gain further improvement, we try different combinations of backbones, training methods and similarity computing methods. Finally, we submit the best combination as our solution and our team(ustc-nelslip) obtains favorable result in the track3 of the RFIW2020 challenge with the first runner-up, which verifies the effectiveness of our method. Our code is available at: https://github.com/gniknoil/FG2020-kinship
Grand Challenge of 106-Point Facial Landmark Localization
May 09, 2019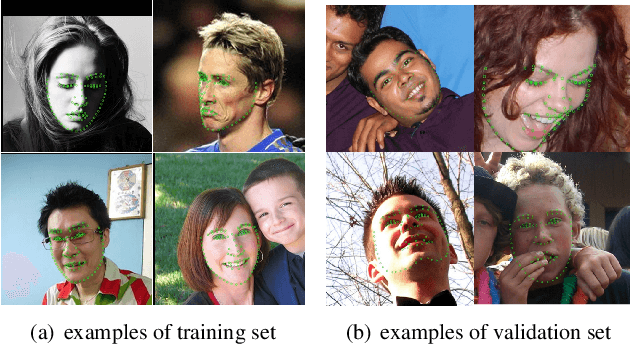
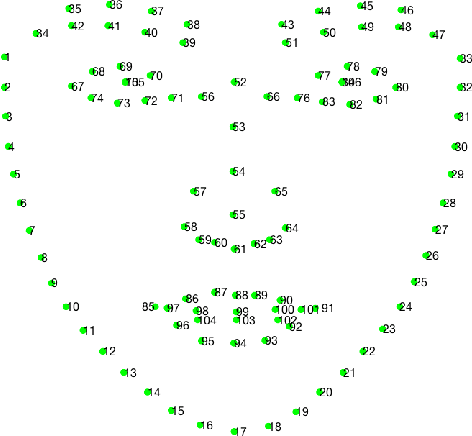

Facial landmark localization is a very crucial step in numerous face related applications, such as face recognition, facial pose estimation, face image synthesis, etc. However, previous competitions on facial landmark localization (i.e., the 300-W, 300-VW and Menpo challenges) aim to predict 68-point landmarks, which are incompetent to depict the structure of facial components. In order to overcome this problem, we construct a challenging dataset, named JD-landmark. Each image is manually annotated with 106-point landmarks. This dataset covers large variations on pose and expression, which brings a lot of difficulties to predict accurate landmarks. We hold a 106-point facial landmark localization competition1 on this dataset in conjunction with IEEE International Conference on Multimedia and Expo (ICME) 2019. The purpose of this competition is to discover effective and robust facial landmark localization approaches.