 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToolACE-DEV: Self-Improving Tool Learning via Decomposition and EVolution
May 12, 2025The tool-using capability of large language models (LLMs) enables them to access up-to-date external information and handle complex tasks. Current approaches to enhancing this capability primarily rely on distilling advanced models by data synthesis. However, this method incurs significant costs associated with advanced model usage and often results in data compatibility issues, led by the high discrepancy in the knowledge scope between the advanced model and the target model. To address these challenges, we propose ToolACE-DEV, a self-improving framework for tool learning. First, we decompose the tool-learning objective into sub-tasks that enhance basic tool-making and tool-using abilities. Then, we introduce a self-evolving paradigm that allows lightweight models to self-improve, reducing reliance on advanced LLMs. Extensive experiments validate the effectiveness of our approach across models of varying scales and architectures.
GUI Agents with Foundation Models: A Comprehensive Survey
Nov 07, 2024

Recent advances in foundation models, particularly Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs), facilitate intelligent agents being capable of performing complex tasks. By leveraging the ability of (M)LLMs to process and interpret Graphical User Interfaces (GUIs), these agents can autonomously execute user instructions by simulating human-like interactions such as clicking and typing. This survey consolidates recent research on (M)LLM-based GUI agents, highlighting key innovations in data, frameworks, and applications. We begin by discussing representative datasets and benchmarks. Next, we summarize a unified framework that captures the essential components used in prior research, accompanied by a taxonomy. Additionally, we explore commercial applications of (M)LLM-based GUI agents. Drawing from existing work, we identify several key challenges and propose future research directions. We hope this paper will inspire further developments in the field of (M)LLM-based GUI agents.
ToolACE: Winning the Points of LLM Function Calling
Sep 02, 2024



Function calling significantly extends the application boundary of large language models, where high-quality and diverse training data is critical for unlocking this capability. However, real function-calling data is quite challenging to collect and annotate, while synthetic data generated by existing pipelines tends to lack coverage and accuracy. In this paper, we present ToolACE, an automatic agentic pipeline designed to generate accurate, complex, and diverse tool-learning data. ToolACE leverages a novel self-evolution synthesis process to curate a comprehensive API pool of 26,507 diverse APIs. Dialogs are further generated through the interplay among multiple agents, guided by a formalized thinking process. To ensure data accuracy, we implement a dual-layer verification system combining rule-based and model-based checks. We demonstrate that models trained on our synthesized data, even with only 8B parameters, achieve state-of-the-art performance on the Berkeley Function-Calling Leaderboard, rivaling the latest GPT-4 models. Our model and a subset of the data are publicly available at https://huggingface.co/Team-ACE.
Deep Fusion Siamese Network for Automatic Kinship Verification
Jun 07, 2020

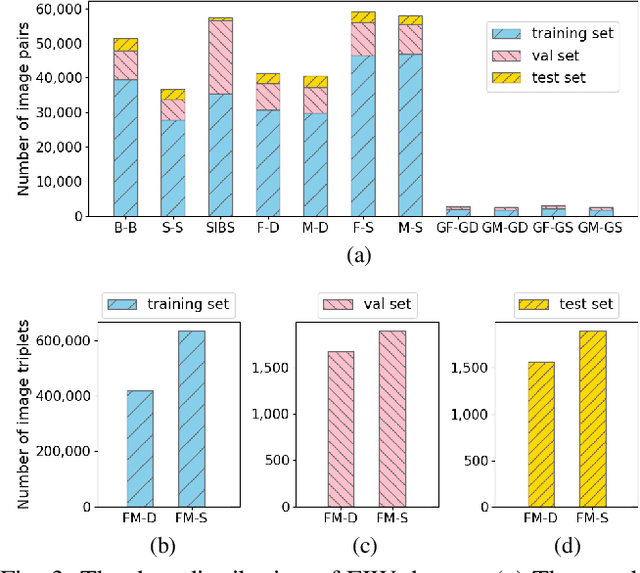
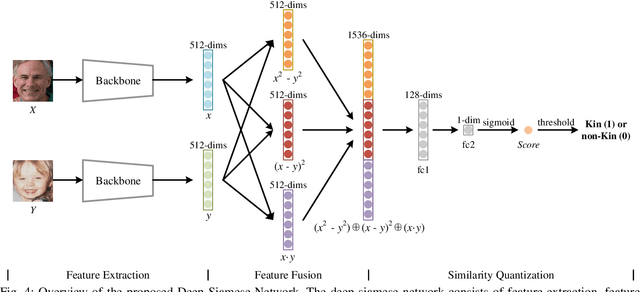
Automatic kinship verification aims to determine whether some individuals belong to the same family. It is of great research significance to help missing persons reunite with their families. In this work, the challenging problem is progressively addressed in two respects. First, we propose a deep siamese network to quantify the relative similarity between two individuals. When given two input face images, the deep siamese network extracts the features from them and fuses these features by combining and concatenating. Then, the fused features are fed into a fully-connected network to obtain the similarity score between two faces, which is used to verify the kinship. To improve the performance, a jury system is also employed for multi-model fusion. Second, two deep siamese networks are integrated into a deep triplet network for tri-subject (i.e., father, mother and child) kinship verification, which is intended to decide whether a child is related to a pair of parents or not. Specifically, the obtained similarity scores of father-child and mother-child are weighted to generate the parent-child similarity score for kinship verification. Recognizing Families In the Wild (RFIW) is a challenging kinship recognition task with multiple tracks, which is based on Families in the Wild (FIW), a large-scale and comprehensive image database for automatic kinship recognition. The Kinship Verification (track I) and Tri-Subject Verification (track II) are supported during the ongoing RFIW2020 Challenge. Our team (ustc-nelslip) ranked 1st in track II, and 3rd in track I. The code is available at https://github.com/gniknoil/FG2020-kinship.
* 8 pages, 8 figures
Retrieval of Family Members Using Siamese Neural Network
May 30, 2020
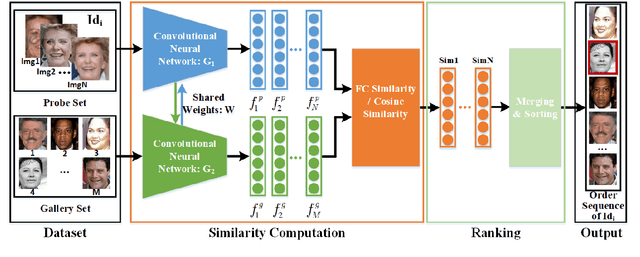
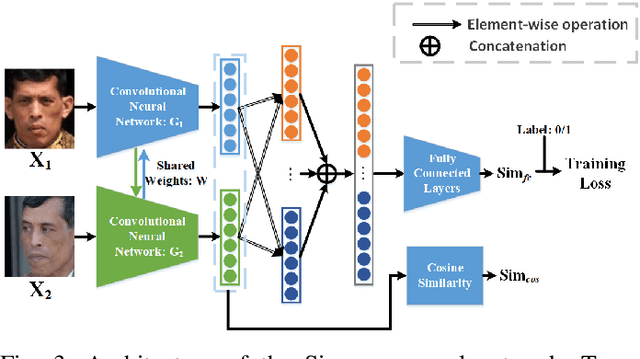
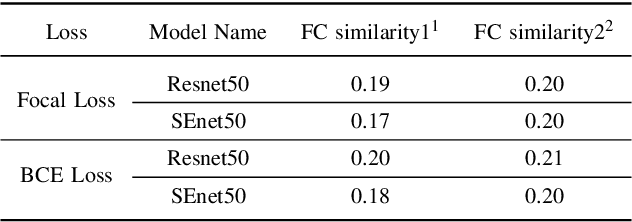
Retrieval of family members in the wild aims at finding family members of the given subject in the dataset, which is useful in finding the lost children and analyzing the kinship. However, due to the diversity in age, gender, pose and illumination of the collected data, this task is always challenging. To solve this problem, we propose our solution with deep Siamese neural network. Our solution can be divided into two parts: similarity computation and ranking. In training procedure, the Siamese network firstly takes two candidate images as input and produces two feature vectors. And then, the similarity between the two vectors is computed with several fully connected layers. While in inference procedure, we try another similarity computing method by dropping the followed several fully connected layers and directly computing the cosine similarity of the two feature vectors. After similarity computation, we use the ranking algorithm to merge the similarity scores with the same identity and output the ordered list according to their similarities. To gain further improvement, we try different combinations of backbones, training methods and similarity computing methods. Finally, we submit the best combination as our solution and our team(ustc-nelslip) obtains favorable result in the track3 of the RFIW2020 challenge with the first runner-up, which verifies the effectiveness of our method. Our code is available at: https://github.com/gniknoil/FG2020-kinship