 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
LeanGeo: Formalizing Competitional Geometry problems in Lean
Aug 20, 2025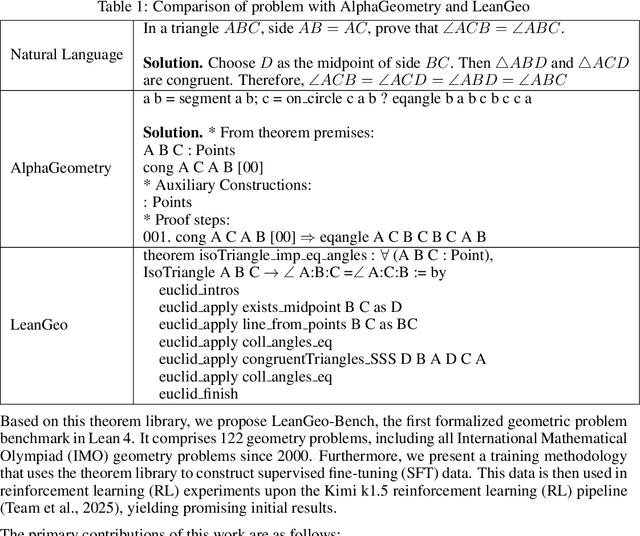

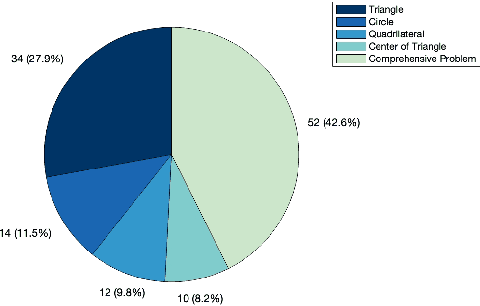
Geometry problems are a crucial testbed for AI reasoning capabilities. Most existing geometry solving systems cannot express problems within a unified framework, thus are difficult to integrate with other mathematical fields. Besides, since most geometric proofs rely on intuitive diagrams, verifying geometry problems is particularly challenging. To address these gaps, we introduce LeanGeo, a unified formal system for formalizing and solving competition-level geometry problems within the Lean 4 theorem prover. LeanGeo features a comprehensive library of high-level geometric theorems with Lean's foundational logic, enabling rigorous proof verification and seamless integration with Mathlib. We also present LeanGeo-Bench, a formal geometry benchmark in LeanGeo, comprising problems from the International Mathematical Olympiad (IMO) and other advanced sources. Our evaluation demonstrates the capabilities and limitations of state-of-the-art Large Language Models on this benchmark, highlighting the need for further advancements in automated geometric reasoning. We open source the theorem library and the benchmark of LeanGeo at https://github.com/project-numina/LeanGeo/tree/master.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
CombiBench: Benchmarking LLM Capability for Combinatorial Mathematics
May 06, 2025Neurosymbolic approaches integrating large language models with formal reasoning have recently achieved human-level performance on mathematics competition problems in algebra, geometry and number theory. In comparison, combinatorics remains a challenging domain, characterized by a lack of appropriate benchmarks and theorem libraries. To address this gap, we introduce CombiBench, a comprehensive benchmark comprising 100 combinatorial problems, each formalized in Lean~4 and paired with its corresponding informal statement. The problem set covers a wide spectrum of difficulty levels, ranging from middle school to IMO and university level, and span over ten combinatorial topics. CombiBench is suitable for testing IMO solving capabilities since it includes all IMO combinatorial problems since 2000 (except IMO 2004 P3 as its statement contain an images). Furthermore, we provide a comprehensive and standardized evaluation framework, dubbed Fine-Eval (for $\textbf{F}$ill-in-the-blank $\textbf{in}$ L$\textbf{e}$an Evaluation), for formal mathematics. It accommodates not only proof-based problems but also, for the first time, the evaluation of fill-in-the-blank questions. Using Fine-Eval as the evaluation method and Kimina Lean Server as the backend, we benchmark several LLMs on CombiBench and observe that their capabilities for formally solving combinatorial problems remain limited. Among all models tested (none of which has been trained for this particular task), Kimina-Prover attains the best results, solving 7 problems (out of 100) under both ``with solution'' and ``without solution'' scenarios. We open source the benchmark dataset alongside with the code of the proposed evaluation method at https://github.com/MoonshotAI/CombiBench/.
Kimina-Prover Preview: Towards Large Formal Reasoning Models with Reinforcement Learning
Apr 15, 2025We introduce Kimina-Prover Preview, a large language model that pioneers a novel reasoning-driven exploration paradigm for formal theorem proving, as showcased in this preview release. Trained with a large-scale reinforcement learning pipeline from Qwen2.5-72B, Kimina-Prover demonstrates strong performance in Lean 4 proof generation by employing a structured reasoning pattern we term \textit{formal reasoning pattern}. This approach allows the model to emulate human problem-solving strategies in Lean, iteratively generating and refining proof steps. Kimina-Prover sets a new state-of-the-art on the miniF2F benchmark, reaching 80.7% with pass@8192. Beyond improved benchmark performance, our work yields several key insights: (1) Kimina-Prover exhibits high sample efficiency, delivering strong results even with minimal sampling (pass@1) and scaling effectively with computational budget, stemming from its unique reasoning pattern and RL training; (2) we demonstrate clear performance scaling with model size, a trend previously unobserved for neural theorem provers in formal mathematics; (3) the learned reasoning style, distinct from traditional search algorithms, shows potential to bridge the gap between formal verification and informal mathematical intuition. We open source distilled versions with 1.5B and 7B parameters of Kimina-Prover
FormalAlign: Automated Alignment Evaluation for Autoformalization
Oct 14, 2024



Autoformalization aims to convert informal mathematical proofs into machine-verifiable formats, bridging the gap between natural and formal languages. However, ensuring semantic alignment between the informal and formalized statements remains challenging. Existing approaches heavily rely on manual verification, hindering scalability. To address this, we introduce \textsc{FormalAlign}, the first automated framework designed for evaluating the alignment between natural and formal languages in autoformalization. \textsc{FormalAlign} trains on both the autoformalization sequence generation task and the representational alignment between input and output, employing a dual loss that combines a pair of mutually enhancing autoformalization and alignment tasks. Evaluated across four benchmarks augmented by our proposed misalignment strategies, \textsc{FormalAlign} demonstrates superior performance. In our experiments, \textsc{FormalAlign} outperforms GPT-4, achieving an Alignment-Selection Score 11.58\% higher on \forml-Basic (99.21\% vs. 88.91\%) and 3.19\% higher on MiniF2F-Valid (66.39\% vs. 64.34\%). This effective alignment evaluation significantly reduces the need for manual verification. Both the dataset and code can be accessed via~\url{https://github.com/rookie-joe/FormalAlign}.
ToolACE: Winning the Points of LLM Function Calling
Sep 02, 2024



Function calling significantly extends the application boundary of large language models, where high-quality and diverse training data is critical for unlocking this capability. However, real function-calling data is quite challenging to collect and annotate, while synthetic data generated by existing pipelines tends to lack coverage and accuracy. In this paper, we present ToolACE, an automatic agentic pipeline designed to generate accurate, complex, and diverse tool-learning data. ToolACE leverages a novel self-evolution synthesis process to curate a comprehensive API pool of 26,507 diverse APIs. Dialogs are further generated through the interplay among multiple agents, guided by a formalized thinking process. To ensure data accuracy, we implement a dual-layer verification system combining rule-based and model-based checks. We demonstrate that models trained on our synthesized data, even with only 8B parameters, achieve state-of-the-art performance on the Berkeley Function-Calling Leaderboard, rivaling the latest GPT-4 models. Our model and a subset of the data are publicly available at https://huggingface.co/Team-ACE.
FVEL: Interactive Formal Verification Environment with Large Language Models via Theorem Proving
Jun 20, 2024



Formal verification (FV) has witnessed growing significance with current emerging program synthesis by the evolving large language models (LLMs). However, current formal verification mainly resorts to symbolic verifiers or hand-craft rules, resulting in limitations for extensive and flexible verification. On the other hand, formal languages for automated theorem proving, such as Isabelle, as another line of rigorous verification, are maintained with comprehensive rules and theorems. In this paper, we propose FVEL, an interactive Formal Verification Environment with LLMs. Specifically, FVEL transforms a given code to be verified into Isabelle, and then conducts verification via neural automated theorem proving with an LLM. The joined paradigm leverages the rigorous yet abundant formulated and organized rules in Isabelle and is also convenient for introducing and adjusting cutting-edge LLMs. To achieve this goal, we extract a large-scale FVELER3. The FVELER dataset includes code dependencies and verification processes that are formulated in Isabelle, containing 758 theories, 29,125 lemmas, and 200,646 proof steps in total with in-depth dependencies. We benchmark FVELER in the FVEL environment by first fine-tuning LLMs with FVELER and then evaluating them on Code2Inv and SV-COMP. The results show that FVEL with FVELER fine-tuned Llama3- 8B solves 17.39% (69 -> 81) more problems, and Mistral-7B 12% (75 -> 84) more problems in SV-COMP. And the proportion of proof errors is reduced. Project page: https://fveler.github.io/.
Process-Driven Autoformalization in Lean 4
Jun 04, 2024



Autoformalization, the conversion of natural language mathematics into formal languages, offers significant potential for advancing mathematical reasoning. However, existing efforts are limited to formal languages with substantial online corpora and struggle to keep pace with rapidly evolving languages like Lean 4. To bridge this gap, we propose a new benchmark \textbf{Form}alization for \textbf{L}ean~\textbf{4} (\textbf{\name}) designed to evaluate the autoformalization capabilities of large language models (LLMs). This benchmark encompasses a comprehensive assessment of questions, answers, formal statements, and proofs. Additionally, we introduce a \textbf{P}rocess-\textbf{S}upervised \textbf{V}erifier (\textbf{PSV}) model that leverages the precise feedback from Lean 4 compilers to enhance autoformalization. Our experiments demonstrate that the PSV method improves autoformalization, enabling higher accuracy using less filtered training data. Furthermore, when fine-tuned with data containing detailed process information, PSV can leverage the data more effectively, leading to more significant improvements in autoformalization for Lean 4. Our dataset and code are available at \url{https://github.com/rookie-joe/PDA}.
Proving Theorems Recursively
May 23, 2024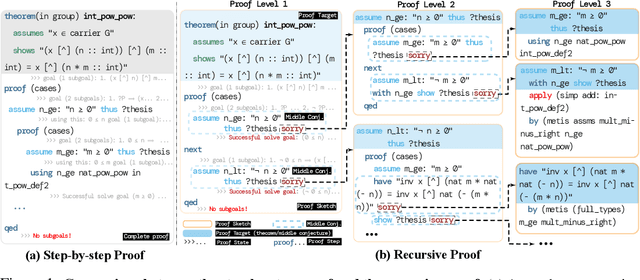

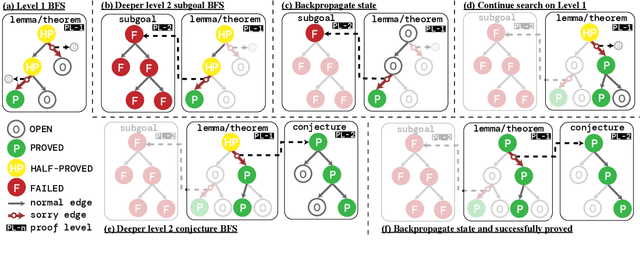
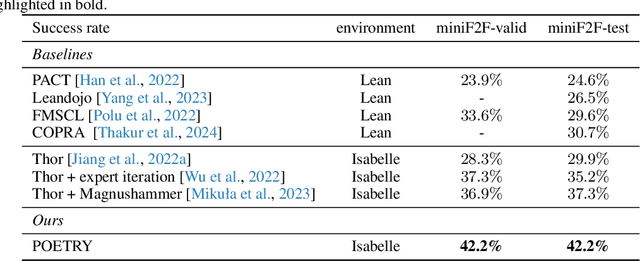
Recent advances in automated theorem proving leverages language models to explore expanded search spaces by step-by-step proof generation. However, such approaches are usually based on short-sighted heuristics (e.g., log probability or value function scores) that potentially lead to suboptimal or even distracting subgoals, preventing us from finding longer proofs. To address this challenge, we propose POETRY (PrOvE Theorems RecursivelY), which proves theorems in a recursive, level-by-level manner in the Isabelle theorem prover. Unlike previous step-by-step methods, POETRY searches for a verifiable sketch of the proof at each level and focuses on solving the current level's theorem or conjecture. Detailed proofs of intermediate conjectures within the sketch are temporarily replaced by a placeholder tactic called sorry, deferring their proofs to subsequent levels. This approach allows the theorem to be tackled incrementally by outlining the overall theorem at the first level and then solving the intermediate conjectures at deeper levels. Experiments are conducted on the miniF2F and PISA datasets and significant performance gains are observed in our POETRY approach over state-of-the-art methods. POETRY on miniF2F achieves an average proving success rate improvement of 5.1%. Moreover, we observe a substantial increase in the maximum proof length found by POETRY, from 10 to 26.