 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPAO: Adaptive Prefix-Aware Optimization for Generative Recommendation
Mar 03, 2026Generative recommendation has recently emerged as a promising paradigm in sequential recommendation. It formulates the task as an autoregressive generation process, predicting discrete tokens of the next item conditioned on user interaction histories. Existing generative recommendation models are typically trained with token-level likelihood objectives, such as cross-entropy loss, while employing multi-step beam search during inference to generate ranked item candidates. However, this leads to a fundamental training-inference inconsistency: standard training assumes ground-truth history is always available, ignoring the fact that beam search prunes low-probability branches during inference. Consequently, the correct item may be prematurely discarded simply because its initial tokens (prefixes) have low scores. To address this issue, we propose the Adaptive Prefix-Aware Optimization (APAO) framework, which introduces prefix-level optimization losses to better align the training objective with the inference setting. Furthermore, we design an adaptive worst-prefix optimization strategy that dynamically focuses on the most vulnerable prefixes during training, thereby enhancing the model's ability to retain correct candidates under beam search constraints. We provide theoretical analyses to demonstrate the effectiveness and efficiency of our framework. Extensive experiments on multiple datasets further show that APAO consistently alleviates the training-inference inconsistency and improves performance across various generative recommendation backbones. Our codes are publicly available at https://github.com/yuyq18/APAO.
AgentRecBench: Benchmarking LLM Agent-based Personalized Recommender Systems
May 26, 2025



The emergence of agentic recommender systems powered by Large Language Models (LLMs) represents a paradigm shift in personalized recommendations, leveraging LLMs' advanced reasoning and role-playing capabilities to enable autonomous, adaptive decision-making. Unlike traditional recommendation approaches, agentic recommender systems can dynamically gather and interpret user-item interactions from complex environments, generating robust recommendation strategies that generalize across diverse scenarios. However, the field currently lacks standardized evaluation protocols to systematically assess these methods. To address this critical gap, we propose: (1) an interactive textual recommendation simulator incorporating rich user and item metadata and three typical evaluation scenarios (classic, evolving-interest, and cold-start recommendation tasks); (2) a unified modular framework for developing and studying agentic recommender systems; and (3) the first comprehensive benchmark comparing 10 classical and agentic recommendation methods. Our findings demonstrate the superiority of agentic systems and establish actionable design guidelines for their core components. The benchmark environment has been rigorously validated through an open challenge and remains publicly available with a continuously maintained leaderboard~\footnote[2]{https://tsinghua-fib-lab.github.io/AgentSocietyChallenge/pages/overview.html}, fostering ongoing community engagement and reproducible research. The benchmark is available at: \hyperlink{https://huggingface.co/datasets/SGJQovo/AgentRecBench}{https://huggingface.co/datasets/SGJQovo/AgentRecBench}.
SPRec: Leveraging Self-Play to Debias Preference Alignment for Large Language Model-based Recommendations
Dec 12, 2024Large language models (LLMs) have attracted significant attention in recommendation systems. Current LLM-based recommender systems primarily rely on supervised fine-tuning (SFT) to train the model for recommendation tasks. However, relying solely on positive samples limits the model's ability to align with user satisfaction and expectations. To address this, researchers have introduced Direct Preference Optimization (DPO), which explicitly aligns recommendations with user preferences using offline preference ranking data. Despite its advantages, our theoretical analysis reveals that DPO inherently biases the model towards a few items, exacerbating the filter bubble issue and ultimately degrading user experience. In this paper, we propose SPRec, a novel self-play recommendation framework designed to mitigate over-recommendation and improve fairness without requiring additional data or manual intervention. In each self-play iteration, the model undergoes an SFT step followed by a DPO step, treating offline interaction data as positive samples and the predicted outputs from the previous iteration as negative samples. This effectively re-weights the DPO loss function using the model's logits, adaptively suppressing biased items. Extensive experiments on multiple real-world datasets demonstrate SPRec's effectiveness in enhancing recommendation accuracy and addressing fairness concerns.
StepTool: A Step-grained Reinforcement Learning Framework for Tool Learning in LLMs
Oct 10, 2024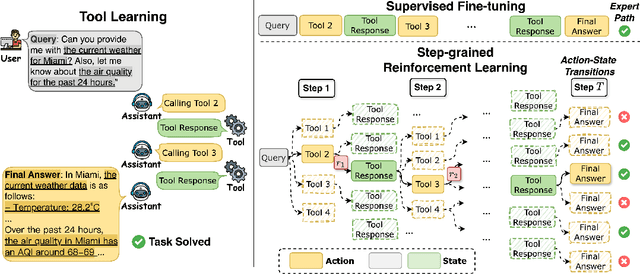

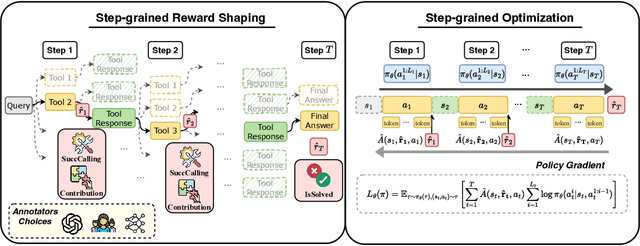
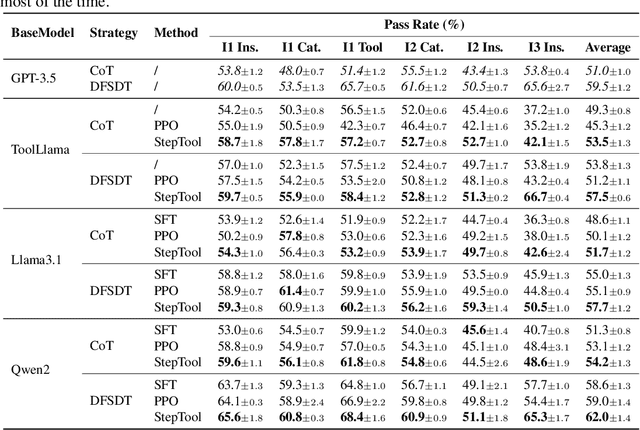
Despite having powerful reasoning and inference capabilities, Large Language Models (LLMs) still need external tools to acquire real-time information retrieval or domain-specific expertise to solve complex tasks, which is referred to as tool learning. Existing tool learning methods primarily rely on tuning with expert trajectories, focusing on token-sequence learning from a linguistic perspective. However, there are several challenges: 1) imitating static trajectories limits their ability to generalize to new tasks. 2) even expert trajectories can be suboptimal, and better solution paths may exist. In this work, we introduce StepTool, a novel step-grained reinforcement learning framework to improve tool learning in LLMs. It consists of two components: Step-grained Reward Shaping, which assigns rewards at each tool interaction based on tool invocation success and its contribution to the task, and Step-grained Optimization, which uses policy gradient methods to optimize the model in a multi-step manner. Experimental results demonstrate that StepTool significantly outperforms existing methods in multi-step, tool-based tasks, providing a robust solution for complex task environments. Codes are available at https://github.com/yuyq18/StepTool.
ToolACE: Winning the Points of LLM Function Calling
Sep 02, 2024



Function calling significantly extends the application boundary of large language models, where high-quality and diverse training data is critical for unlocking this capability. However, real function-calling data is quite challenging to collect and annotate, while synthetic data generated by existing pipelines tends to lack coverage and accuracy. In this paper, we present ToolACE, an automatic agentic pipeline designed to generate accurate, complex, and diverse tool-learning data. ToolACE leverages a novel self-evolution synthesis process to curate a comprehensive API pool of 26,507 diverse APIs. Dialogs are further generated through the interplay among multiple agents, guided by a formalized thinking process. To ensure data accuracy, we implement a dual-layer verification system combining rule-based and model-based checks. We demonstrate that models trained on our synthesized data, even with only 8B parameters, achieve state-of-the-art performance on the Berkeley Function-Calling Leaderboard, rivaling the latest GPT-4 models. Our model and a subset of the data are publicly available at https://huggingface.co/Team-ACE.
EasyRL4Rec: A User-Friendly Code Library for Reinforcement Learning Based Recommender Systems
Feb 23, 2024


Reinforcement Learning (RL)-Based Recommender Systems (RSs) are increasingly recognized for their ability to improve long-term user engagement. Yet, the field grapples with challenges such as the absence of accessible frameworks, inconsistent evaluation standards, and the complexity of replicating prior work. Addressing these obstacles, we present EasyRL4Rec, a user-friendly and efficient library tailored for RL-based RSs. EasyRL4Rec features lightweight, diverse RL environments built on five widely-used public datasets, and is equipped with comprehensive core modules that offer rich options to ease the development of models. It establishes consistent evaluation criteria with a focus on long-term impacts and introduces customized solutions for state modeling and action representation tailored to recommender systems. Additionally, we share valuable insights gained from extensive experiments with current methods. EasyRL4Rec aims to facilitate the model development and experimental process in the domain of RL-based RSs. The library is openly accessible at https://github.com/chongminggao/EasyRL4Rec.
Multi-Agent Collaboration Framework for Recommender Systems
Feb 23, 2024
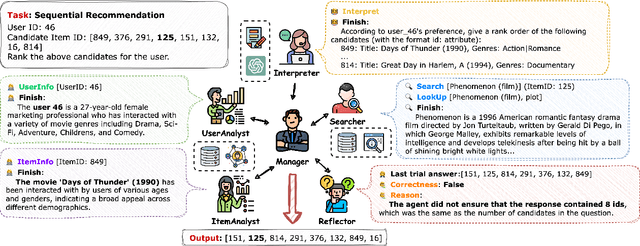


LLM-based agents have gained considerable attention for their decision-making skills and ability to handle complex tasks. Recognizing the current gap in leveraging agent capabilities for multi-agent collaboration in recommendation systems, we introduce MACRec, a novel framework designed to enhance recommendation systems through multi-agent collaboration. Unlike existing work on using agents for user/item simulation, we aim to deploy multi-agents to tackle recommendation tasks directly. In our framework, recommendation tasks are addressed through the collaborative efforts of various specialized agents, including Manager, User/Item Analyst, Reflector, Searcher, and Task Interpreter, with different working flows. Furthermore, we provide application examples of how developers can easily use MACRec on various recommendation tasks, including rating prediction, sequential recommendation, conversational recommendation, and explanation generation of recommendation results. The framework and demonstration video are publicly available at https://github.com/wzf2000/MACRec.
Towards Representation Alignment and Uniformity in Collaborative Filtering
Jun 26, 2022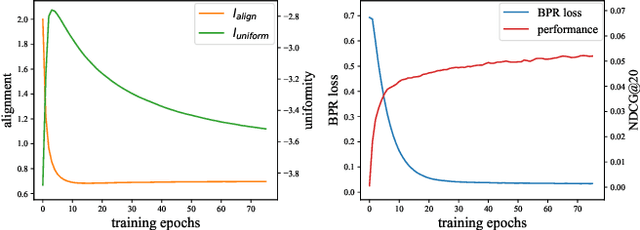
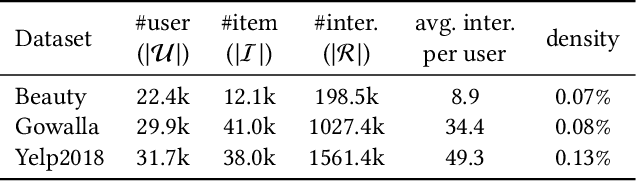
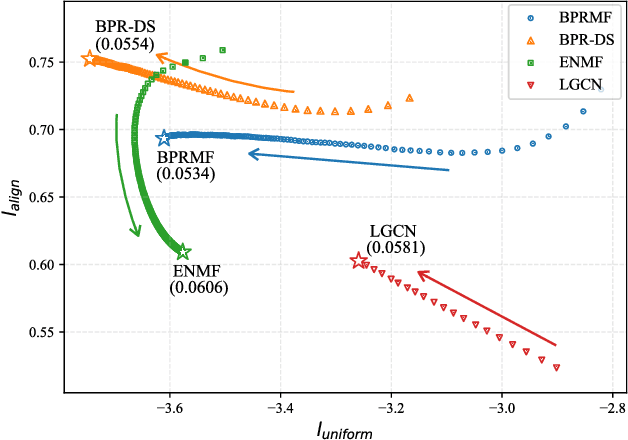

Collaborative filtering (CF) plays a critical role in the development of recommender systems. Most CF methods utilize an encoder to embed users and items into the same representation space, and the Bayesian personalized ranking (BPR) loss is usually adopted as the objective function to learn informative encoders. Existing studies mainly focus on designing more powerful encoders (e.g., graph neural network) to learn better representations. However, few efforts have been devoted to investigating the desired properties of representations in CF, which is important to understand the rationale of existing CF methods and design new learning objectives. In this paper, we measure the representation quality in CF from the perspective of alignment and uniformity on the hypersphere. We first theoretically reveal the connection between the BPR loss and these two properties. Then, we empirically analyze the learning dynamics of typical CF methods in terms of quantified alignment and uniformity, which shows that better alignment or uniformity both contribute to higher recommendation performance. Based on the analyses results, a learning objective that directly optimizes these two properties is proposed, named DirectAU. We conduct extensive experiments on three public datasets, and the proposed learning framework with a simple matrix factorization model leads to significant performance improvements compared to state-of-the-art CF methods. Our implementations are publicly available at https://github.com/THUwangcy/DirectAU.