 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoc-Researcher: A Unified System for Multimodal Document Parsing and Deep Research
Oct 24, 2025Deep Research systems have revolutionized how LLMs solve complex questions through iterative reasoning and evidence gathering. However, current systems remain fundamentally constrained to textual web data, overlooking the vast knowledge embedded in multimodal documents Processing such documents demands sophisticated parsing to preserve visual semantics (figures, tables, charts, and equations), intelligent chunking to maintain structural coherence, and adaptive retrieval across modalities, which are capabilities absent in existing systems. In response, we present Doc-Researcher, a unified system that bridges this gap through three integrated components: (i) deep multimodal parsing that preserves layout structure and visual semantics while creating multi-granular representations from chunk to document level, (ii) systematic retrieval architecture supporting text-only, vision-only, and hybrid paradigms with dynamic granularity selection, and (iii) iterative multi-agent workflows that decompose complex queries, progressively accumulate evidence, and synthesize comprehensive answers across documents and modalities. To enable rigorous evaluation, we introduce M4DocBench, the first benchmark for Multi-modal, Multi-hop, Multi-document, and Multi-turn deep research. Featuring 158 expert-annotated questions with complete evidence chains across 304 documents, M4DocBench tests capabilities that existing benchmarks cannot assess. Experiments demonstrate that Doc-Researcher achieves 50.6% accuracy, 3.4xbetter than state-of-the-art baselines, validating that effective document research requires not just better retrieval, but fundamentally deep parsing that preserve multimodal integrity and support iterative research. Our work establishes a new paradigm for conducting deep research on multimodal document collections.
Adaptive Tool Use in Large Language Models with Meta-Cognition Trigger
Feb 18, 2025



Large language models (LLMs) have shown remarkable emergent capabilities, transforming the execution of functional tasks by leveraging external tools for complex problems that require specialized processing or real-time data. While existing research expands LLMs access to diverse tools (e.g., program interpreters, search engines, weather/map apps), the necessity of using these tools is often overlooked, leading to indiscriminate tool invocation. This naive approach raises two key issues:(1) increased delays due to unnecessary tool calls, and (2) potential errors resulting from faulty interactions with external tools. In this paper, we introduce meta-cognition as a proxy for LLMs self-assessment of their capabilities, representing the model's awareness of its own limitations. Based on this, we propose MeCo, an adaptive decision-making strategy for external tool use. MeCo quantifies metacognitive scores by capturing high-level cognitive signals in the representation space, guiding when to invoke tools. Notably, MeCo is fine-tuning-free and incurs minimal cost. Our experiments show that MeCo accurately detects LLMs' internal cognitive signals and significantly improves tool-use decision-making across multiple base models and benchmarks.
MMDocIR: Benchmarking Multi-Modal Retrieval for Long Documents
Jan 15, 2025



Multi-modal document retrieval is designed to identify and retrieve various forms of multi-modal content, such as figures, tables, charts, and layout information from extensive documents. Despite its significance, there is a notable lack of a robust benchmark to effectively evaluate the performance of systems in multi-modal document retrieval. To address this gap, this work introduces a new benchmark, named as MMDocIR, encompassing two distinct tasks: page-level and layout-level retrieval. The former focuses on localizing the most relevant pages within a long document, while the latter targets the detection of specific layouts, offering a more fine-grained granularity than whole-page analysis. A layout can refer to a variety of elements such as textual paragraphs, equations, figures, tables, or charts. The MMDocIR benchmark comprises a rich dataset featuring expertly annotated labels for 1,685 questions and bootstrapped labels for 173,843 questions, making it a pivotal resource for advancing multi-modal document retrieval for both training and evaluation. Through rigorous experiments, we reveal that (i) visual retrievers significantly outperform their text counterparts, (ii) MMDocIR train set can effectively benefit the training process of multi-modal document retrieval and (iii) text retrievers leveraging on VLM-text perform much better than those using OCR-text. These findings underscores the potential advantages of integrating visual elements for multi-modal document retrieval.
ToolACE: Winning the Points of LLM Function Calling
Sep 02, 2024



Function calling significantly extends the application boundary of large language models, where high-quality and diverse training data is critical for unlocking this capability. However, real function-calling data is quite challenging to collect and annotate, while synthetic data generated by existing pipelines tends to lack coverage and accuracy. In this paper, we present ToolACE, an automatic agentic pipeline designed to generate accurate, complex, and diverse tool-learning data. ToolACE leverages a novel self-evolution synthesis process to curate a comprehensive API pool of 26,507 diverse APIs. Dialogs are further generated through the interplay among multiple agents, guided by a formalized thinking process. To ensure data accuracy, we implement a dual-layer verification system combining rule-based and model-based checks. We demonstrate that models trained on our synthesized data, even with only 8B parameters, achieve state-of-the-art performance on the Berkeley Function-Calling Leaderboard, rivaling the latest GPT-4 models. Our model and a subset of the data are publicly available at https://huggingface.co/Team-ACE.
EduQate: Generating Adaptive Curricula through RMABs in Education Settings
Jun 20, 2024



There has been significant interest in the development of personalized and adaptive educational tools that cater to a student's individual learning progress. A crucial aspect in developing such tools is in exploring how mastery can be achieved across a diverse yet related range of content in an efficient manner. While Reinforcement Learning and Multi-armed Bandits have shown promise in educational settings, existing works often assume the independence of learning content, neglecting the prevalent interdependencies between such content. In response, we introduce Education Network Restless Multi-armed Bandits (EdNetRMABs), utilizing a network to represent the relationships between interdependent arms. Subsequently, we propose EduQate, a method employing interdependency-aware Q-learning to make informed decisions on arm selection at each time step. We establish the optimality guarantee of EduQate and demonstrate its efficacy compared to baseline policies, using students modeled from both synthetic and real-world data.
Meta-Task Planning for Language Agents
May 28, 2024The rapid advancement of neural language models has sparked a new surge of intelligent agent research. Unlike traditional agents, large language model-based agents (LLM agents) have emerged as a promising paradigm for achieving artificial general intelligence (AGI) due to their superior reasoning and generalization capabilities. Effective planning is crucial for the success of LLM agents in real-world tasks, making it a highly pursued topic in the community. Current planning methods typically translate tasks into executable action sequences. However, determining a feasible or optimal sequence for complex tasks at fine granularity, which often requires compositing long chains of heterogeneous actions, remains challenging. This paper introduces Meta-Task Planning (MTP), a zero-shot methodology for collaborative LLM-based multi-agent systems that simplifies complex task planning by decomposing it into a hierarchy of subordinate tasks, or meta-tasks. Each meta-task is then mapped into executable actions. MTP was assessed on two rigorous benchmarks, TravelPlanner and API-Bank. Notably, MTP achieved an average $\sim40\%$ success rate on TravelPlanner, significantly higher than the state-of-the-art (SOTA) baseline ($2.92\%$), and outperforming $LLM_{api}$-4 with ReAct on API-Bank by $\sim14\%$, showing the immense potential of integrating LLM with multi-agent systems.
Aligning Crowd Feedback via Distributional Preference Reward Modeling
Feb 21, 2024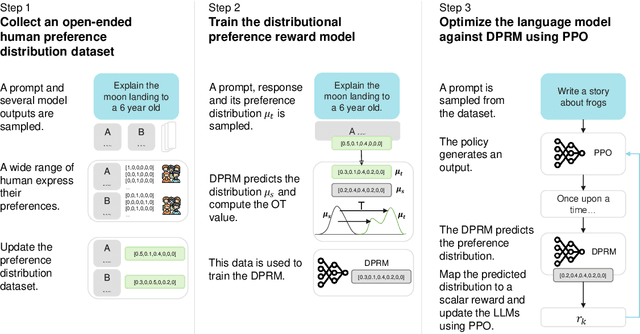



Deep Reinforcement Learning is widely used for aligning Large Language Models (LLM) with human preference. However, the conventional reward modelling has predominantly depended on human annotations provided by a select cohort of individuals. Such dependence may unintentionally result in models that are skewed to reflect the inclinations of these annotators, thereby failing to represent the expectations of the wider population adequately. In this paper, we introduce the Distributional Preference Reward Model (DPRM), a simple yet effective framework to align large language models with a diverse set of human preferences. To this end, we characterize the preferences by a beta distribution, which can dynamically adapt to fluctuations in preference trends. On top of that, we design an optimal-transportation-based loss to calibrate DPRM to align with the preference distribution. Finally, the expected reward is utilized to fine-tune an LLM policy to generate responses favoured by the population. Our experiments show that DPRM significantly enhances the alignment of LLMs with population preference, yielding more accurate, unbiased, and contextually appropriate responses.
A Hierarchical Approach to Environment Design with Generative Trajectory Modeling
Sep 30, 2023



Unsupervised Environment Design (UED) is a paradigm for training generally capable agents to achieve good zero-shot transfer performance. This paradigm hinges on automatically generating a curriculum of training environments. Leading approaches for UED predominantly use randomly generated environment instances to train the agent. While these methods exhibit good zero-shot transfer performance, they often encounter challenges in effectively exploring large design spaces or leveraging previously discovered underlying structures, To address these challenges, we introduce a novel framework based on Hierarchical MDP (Markov Decision Processes). Our approach includes an upper-level teacher's MDP responsible for training a lower-level MDP student agent, guided by the student's performance. To expedite the learning of the upper leavel MDP, we leverage recent advancements in generative modeling to generate synthetic experience dataset for training the teacher agent. Our algorithm, called Synthetically-enhanced Hierarchical Environment Design (SHED), significantly reduces the resource-intensive interactions between the agent and the environment. To validate the effectiveness of SHED, we conduct empirical experiments across various domains, with the goal of developing an efficient and robust agent under limited training resources. Our results show the manifold advantages of SHED and highlight its effectiveness as a potent instrument for curriculum-based learning within the UED framework. This work contributes to exploring the next generation of RL agents capable of adeptly handling an ever-expanding range of complex tasks.
Diversity Induced Environment Design via Self-Play
Feb 04, 2023



Recent work on designing an appropriate distribution of environments has shown promise for training effective generally capable agents. Its success is partly because of a form of adaptive curriculum learning that generates environment instances (or levels) at the frontier of the agent's capabilities. However, such an environment design framework often struggles to find effective levels in challenging design spaces and requires costly interactions with the environment. In this paper, we aim to introduce diversity in the Unsupervised Environment Design (UED) framework. Specifically, we propose a task-agnostic method to identify observed/hidden states that are representative of a given level. The outcome of this method is then utilized to characterize the diversity between two levels, which as we show can be crucial to effective performance. In addition, to improve sampling efficiency, we incorporate the self-play technique that allows the environment generator to automatically generate environments that are of great benefit to the training agent. Quantitatively, our approach, Diversity-induced Environment Design via Self-Play (DivSP), shows compelling performance over existing methods.
Effective Diversity in Unsupervised Environment Design
Jan 19, 2023Agent decision making using Reinforcement Learning (RL) heavily relies on either a model or simulator of the environment (e.g., moving in an 8x8 maze with three rooms, playing Chess on an 8x8 board). Due to this dependence, small changes in the environment (e.g. positions of obstacles in the maze, size of the board) can severely affect the effectiveness of the policy learnt by the agent. To that end, existing work has proposed training RL agents on an adaptive curriculum of environments (generated automatically) to improve performance on out-of-distribution (OOD) test scenarios. Specifically, existing research has employed the potential for the agent to learn in an environment (captured using Generalized Advantage Estimation, GAE) as the key factor to select the next environment(s) to train the agent. However, such a mechanism can select similar environments (with a high potential to learn) thereby making agent training redundant on all but one of those environments. To that end, we provide a principled approach to adaptively identify diverse environments based on a novel distance measure relevant to environment design. We empirically demonstrate the versatility and effectiveness of our method in comparison to multiple leading approaches for unsupervised environment design on three distinct benchmark problems used in literature.