 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEduQate: Generating Adaptive Curricula through RMABs in Education Settings
Jun 20, 2024



There has been significant interest in the development of personalized and adaptive educational tools that cater to a student's individual learning progress. A crucial aspect in developing such tools is in exploring how mastery can be achieved across a diverse yet related range of content in an efficient manner. While Reinforcement Learning and Multi-armed Bandits have shown promise in educational settings, existing works often assume the independence of learning content, neglecting the prevalent interdependencies between such content. In response, we introduce Education Network Restless Multi-armed Bandits (EdNetRMABs), utilizing a network to represent the relationships between interdependent arms. Subsequently, we propose EduQate, a method employing interdependency-aware Q-learning to make informed decisions on arm selection at each time step. We establish the optimality guarantee of EduQate and demonstrate its efficacy compared to baseline policies, using students modeled from both synthetic and real-world data.
Training Reinforcement Learning Agents and Humans With Difficulty-Conditioned Generators
Dec 04, 2023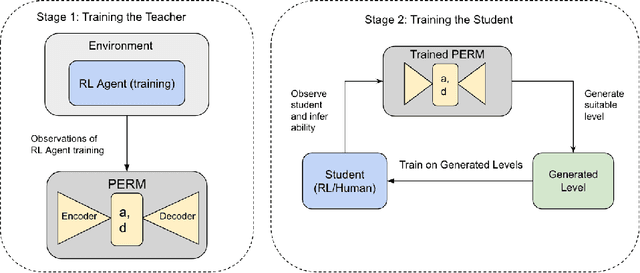



We adapt Parameterized Environment Response Model (PERM), a method for training both Reinforcement Learning (RL) Agents and human learners in parameterized environments by directly modeling difficulty and ability. Inspired by Item Response Theory (IRT), PERM aligns environment difficulty with individual ability, creating a Zone of Proximal Development-based curriculum. Remarkably, PERM operates without real-time RL updates and allows for offline training, ensuring its adaptability across diverse students. We present a two-stage training process that capitalizes on PERM's adaptability, and demonstrate its effectiveness in training RL agents and humans in an empirical study.
Transferable Curricula through Difficulty Conditioned Generators
Jun 22, 2023Advancements in reinforcement learning (RL) have demonstrated superhuman performance in complex tasks such as Starcraft, Go, Chess etc. However, knowledge transfer from Artificial "Experts" to humans remain a significant challenge. A promising avenue for such transfer would be the use of curricula. Recent methods in curricula generation focuses on training RL agents efficiently, yet such methods rely on surrogate measures to track student progress, and are not suited for training robots in the real world (or more ambitiously humans). In this paper, we introduce a method named Parameterized Environment Response Model (PERM) that shows promising results in training RL agents in parameterized environments. Inspired by Item Response Theory, PERM seeks to model difficulty of environments and ability of RL agents directly. Given that RL agents and humans are trained more efficiently under the "zone of proximal development", our method generates a curriculum by matching the difficulty of an environment to the current ability of the student. In addition, PERM can be trained offline and does not employ non-stationary measures of student ability, making it suitable for transfer between students. We demonstrate PERM's ability to represent the environment parameter space, and training with RL agents with PERM produces a strong performance in deterministic environments. Lastly, we show that our method is transferable between students, without any sacrifice in training quality.
Improving Multi-Agent Cooperation using Theory of Mind
Jul 30, 2020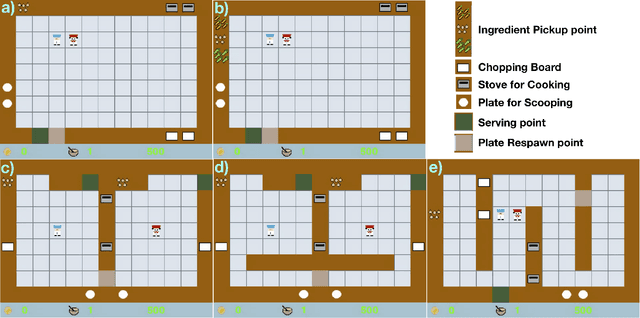


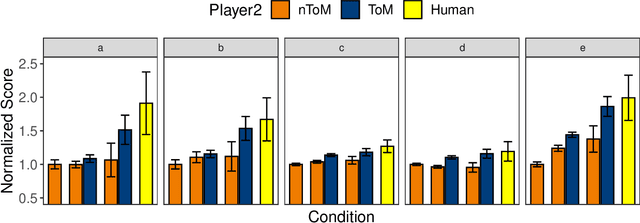
Recent advances in Artificial Intelligence have produced agents that can beat human world champions at games like Go, Starcraft, and Dota2. However, most of these models do not seem to play in a human-like manner: People infer others' intentions from their behaviour, and use these inferences in scheming and strategizing. Here, using a Bayesian Theory of Mind (ToM) approach, we investigated how much an explicit representation of others' intentions improves performance in a cooperative game. We compared the performance of humans playing with optimal-planning agents with and without ToM, in a cooperative game where players have to flexibly cooperate to achieve joint goals. We find that teams with ToM agents significantly outperform non-ToM agents when collaborating with all types of partners: non-ToM, ToM, as well as human players, and that the benefit of ToM increases the more ToM agents there are. These findings have implications for designing better cooperative agents.