 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Unsupervised Environment Design through Hierarchical Policy Representation Learning
Feb 10, 2026Unsupervised Environment Design (UED) has emerged as a promising approach to developing general-purpose agents through automated curriculum generation. Popular UED methods focus on Open-Endedness, where teacher algorithms rely on stochastic processes for infinite generation of useful environments. This assumption becomes impractical in resource-constrained scenarios where teacher-student interaction opportunities are limited. To address this challenge, we introduce a hierarchical Markov Decision Process (MDP) framework for environment design. Our framework features a teacher agent that leverages student policy representations derived from discovered evaluation environments, enabling it to generate training environments based on the student's capabilities. To improve efficiency, we incorporate a generative model that augments the teacher's training dataset with synthetic data, reducing the need for teacher-student interactions. In experiments across several domains, we show that our method outperforms baseline approaches while requiring fewer teacher-student interactions in a single episode. The results suggest the applicability of our approach in settings where training opportunities are limited.
Offline Safe Policy Optimization From Heterogeneous Feedback
Dec 23, 2025Offline Preference-based Reinforcement Learning (PbRL) learns rewards and policies aligned with human preferences without the need for extensive reward engineering and direct interaction with human annotators. However, ensuring safety remains a critical challenge across many domains and tasks. Previous works on safe RL from human feedback (RLHF) first learn reward and cost models from offline data, then use constrained RL to optimize a safe policy. While such an approach works in the contextual bandits settings (LLMs), in long horizon continuous control tasks, errors in rewards and costs accumulate, leading to impairment in performance when used with constrained RL methods. To address these challenges, (a) instead of indirectly learning policies (from rewards and costs), we introduce a framework that learns a policy directly based on pairwise preferences regarding the agent's behavior in terms of rewards, as well as binary labels indicating the safety of trajectory segments; (b) we propose \textsc{PreSa} (Preference and Safety Alignment), a method that combines preference learning module with safety alignment in a constrained optimization problem. This optimization problem is solved within a Lagrangian paradigm that directly learns reward-maximizing safe policy \textit{without explicitly learning reward and cost models}, avoiding the need for constrained RL; (c) we evaluate our approach on continuous control tasks with both synthetic and real human feedback. Empirically, our method successfully learns safe policies with high rewards, outperforming state-of-the-art baselines, and offline safe RL approaches with ground-truth reward and cost.
Learning What to Do and What Not To Do: Offline Imitation from Expert and Undesirable Demonstrations
May 27, 2025Offline imitation learning typically learns from expert and unlabeled demonstrations, yet often overlooks the valuable signal in explicitly undesirable behaviors. In this work, we study offline imitation learning from contrasting behaviors, where the dataset contains both expert and undesirable demonstrations. We propose a novel formulation that optimizes a difference of KL divergences over the state-action visitation distributions of expert and undesirable (or bad) data. Although the resulting objective is a DC (Difference-of-Convex) program, we prove that it becomes convex when expert demonstrations outweigh undesirable demonstrations, enabling a practical and stable non-adversarial training objective. Our method avoids adversarial training and handles both positive and negative demonstrations in a unified framework. Extensive experiments on standard offline imitation learning benchmarks demonstrate that our approach consistently outperforms state-of-the-art baselines.
Optimizing Ride-Pooling Operations with Extended Pickup and Drop-Off Flexibility
Mar 11, 2025The Ride-Pool Matching Problem (RMP) is central to on-demand ride-pooling services, where vehicles must be matched with multiple requests while adhering to service constraints such as pickup delays, detour limits, and vehicle capacity. Most existing RMP solutions assume passengers are picked up and dropped off at their original locations, neglecting the potential for passengers to walk to nearby spots to meet vehicles. This assumption restricts the optimization potential in ride-pooling operations. In this paper, we propose a novel matching method that incorporates extended pickup and drop-off areas for passengers. We first design a tree-based approach to efficiently generate feasible matches between passengers and vehicles. Next, we optimize vehicle routes to cover all designated pickup and drop-off locations while minimizing total travel distance. Finally, we employ dynamic assignment strategies to achieve optimal matching outcomes. Experiments on city-scale taxi datasets demonstrate that our method improves the number of served requests by up to 13\% and average travel distance by up to 21\% compared to leading existing solutions, underscoring the potential of leveraging passenger mobility to significantly enhance ride-pooling service efficiency.
Improving Environment Novelty Quantification for Effective Unsupervised Environment Design
Feb 08, 2025Unsupervised Environment Design (UED) formalizes the problem of autocurricula through interactive training between a teacher agent and a student agent. The teacher generates new training environments with high learning potential, curating an adaptive curriculum that strengthens the student's ability to handle unseen scenarios. Existing UED methods mainly rely on regret, a metric that measures the difference between the agent's optimal and actual performance, to guide curriculum design. Regret-driven methods generate curricula that progressively increase environment complexity for the student but overlook environment novelty -- a critical element for enhancing an agent's generalizability. Measuring environment novelty is especially challenging due to the underspecified nature of environment parameters in UED, and existing approaches face significant limitations. To address this, this paper introduces the Coverage-based Evaluation of Novelty In Environment (CENIE) framework. CENIE proposes a scalable, domain-agnostic, and curriculum-aware approach to quantifying environment novelty by leveraging the student's state-action space coverage from previous curriculum experiences. We then propose an implementation of CENIE that models this coverage and measures environment novelty using Gaussian Mixture Models. By integrating both regret and novelty as complementary objectives for curriculum design, CENIE facilitates effective exploration across the state-action space while progressively increasing curriculum complexity. Empirical evaluations demonstrate that augmenting existing regret-based UED algorithms with CENIE achieves state-of-the-art performance across multiple benchmarks, underscoring the effectiveness of novelty-driven autocurricula for robust generalization.
On Learning Informative Trajectory Embeddings for Imitation, Classification and Regression
Jan 16, 2025



In real-world sequential decision making tasks like autonomous driving, robotics, and healthcare, learning from observed state-action trajectories is critical for tasks like imitation, classification, and clustering. For example, self-driving cars must replicate human driving behaviors, while robots and healthcare systems benefit from modeling decision sequences, whether or not they come from expert data. Existing trajectory encoding methods often focus on specific tasks or rely on reward signals, limiting their ability to generalize across domains and tasks. Inspired by the success of embedding models like CLIP and BERT in static domains, we propose a novel method for embedding state-action trajectories into a latent space that captures the skills and competencies in the dynamic underlying decision-making processes. This method operates without the need for reward labels, enabling better generalization across diverse domains and tasks. Our contributions are threefold: (1) We introduce a trajectory embedding approach that captures multiple abilities from state-action data. (2) The learned embeddings exhibit strong representational power across downstream tasks, including imitation, classification, clustering, and regression. (3) The embeddings demonstrate unique properties, such as controlling agent behaviors in IQ-Learn and an additive structure in the latent space. Experimental results confirm that our method outperforms traditional approaches, offering more flexible and powerful trajectory representations for various applications. Our code is available at https://github.com/Erasmo1015/vte.
Offline Safe Reinforcement Learning Using Trajectory Classification
Dec 19, 2024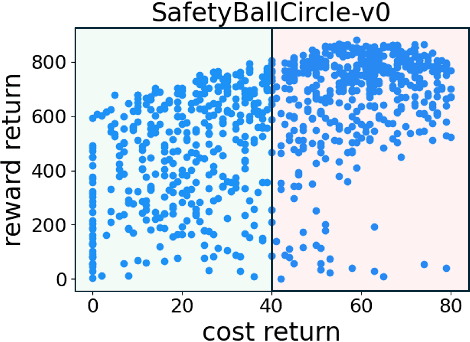

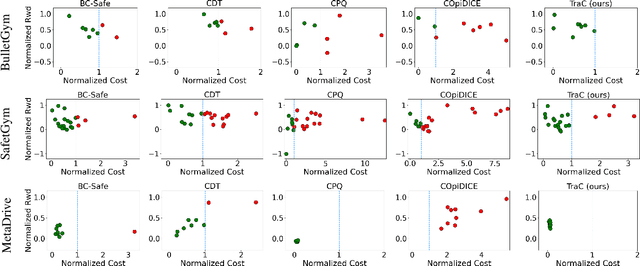

Offline safe reinforcement learning (RL) has emerged as a promising approach for learning safe behaviors without engaging in risky online interactions with the environment. Most existing methods in offline safe RL rely on cost constraints at each time step (derived from global cost constraints) and this can result in either overly conservative policies or violation of safety constraints. In this paper, we propose to learn a policy that generates desirable trajectories and avoids undesirable trajectories. To be specific, we first partition the pre-collected dataset of state-action trajectories into desirable and undesirable subsets. Intuitively, the desirable set contains high reward and safe trajectories, and undesirable set contains unsafe trajectories and low-reward safe trajectories. Second, we learn a policy that generates desirable trajectories and avoids undesirable trajectories, where (un)desirability scores are provided by a classifier learnt from the dataset of desirable and undesirable trajectories. This approach bypasses the computational complexity and stability issues of a min-max objective that is employed in existing methods. Theoretically, we also show our approach's strong connections to existing learning paradigms involving human feedback. Finally, we extensively evaluate our method using the DSRL benchmark for offline safe RL. Empirically, our method outperforms competitive baselines, achieving higher rewards and better constraint satisfaction across a wide variety of benchmark tasks.
IRL for Restless Multi-Armed Bandits with Applications in Maternal and Child Health
Dec 11, 2024Public health practitioners often have the goal of monitoring patients and maximizing patients' time spent in "favorable" or healthy states while being constrained to using limited resources. Restless multi-armed bandits (RMAB) are an effective model to solve this problem as they are helpful to allocate limited resources among many agents under resource constraints, where patients behave differently depending on whether they are intervened on or not. However, RMABs assume the reward function is known. This is unrealistic in many public health settings because patients face unique challenges and it is impossible for a human to know who is most deserving of any intervention at such a large scale. To address this shortcoming, this paper is the first to present the use of inverse reinforcement learning (IRL) to learn desired rewards for RMABs, and we demonstrate improved outcomes in a maternal and child health telehealth program. First we allow public health experts to specify their goals at an aggregate or population level and propose an algorithm to design expert trajectories at scale based on those goals. Second, our algorithm WHIRL uses gradient updates to optimize the objective, allowing for efficient and accurate learning of RMAB rewards. Third, we compare with existing baselines and outperform those in terms of run-time and accuracy. Finally, we evaluate and show the usefulness of WHIRL on thousands on beneficiaries from a real-world maternal and child health setting in India. We publicly release our code here: https://github.com/Gjain234/WHIRL.
Semantic loss guided data efficient supervised fine tuning for Safe Responses in LLMs
Dec 07, 2024



Large Language Models (LLMs) generating unsafe responses to toxic prompts is a significant issue in their applications. While various efforts aim to address this safety concern, previous approaches often demand substantial human data collection or rely on the less dependable option of using another LLM to generate corrective data. In this paper, we aim to take this problem and overcome limitations of requiring significant high-quality human data. Our method requires only a small set of unsafe responses to toxic prompts, easily obtained from the unsafe LLM itself. By employing a semantic cost combined with a negative Earth Mover Distance (EMD) loss, we guide the LLM away from generating unsafe responses. Additionally, we propose a novel lower bound for EMD loss, enabling more efficient optimization. Our results demonstrate superior performance and data efficiency compared to baselines, and we further examine the nuanced effects of over-alignment and potential degradation of language capabilities when using contrastive data.
UNIQ: Offline Inverse Q-learning for Avoiding Undesirable Demonstrations
Oct 10, 2024We address the problem of offline learning a policy that avoids undesirable demonstrations. Unlike conventional offline imitation learning approaches that aim to imitate expert or near-optimal demonstrations, our setting involves avoiding undesirable behavior (specified using undesirable demonstrations). To tackle this problem, unlike standard imitation learning where the aim is to minimize the distance between learning policy and expert demonstrations, we formulate the learning task as maximizing a statistical distance, in the space of state-action stationary distributions, between the learning policy and the undesirable policy. This significantly different approach results in a novel training objective that necessitates a new algorithm to address it. Our algorithm, UNIQ, tackles these challenges by building on the inverse Q-learning framework, framing the learning problem as a cooperative (non-adversarial) task. We then demonstrate how to efficiently leverage unlabeled data for practical training. Our method is evaluated on standard benchmark environments, where it consistently outperforms state-of-the-art baselines. The code implementation can be accessed at: https://github.com/hmhuy0/UNIQ.