 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Safe Policy Optimization From Heterogeneous Feedback
Dec 23, 2025Offline Preference-based Reinforcement Learning (PbRL) learns rewards and policies aligned with human preferences without the need for extensive reward engineering and direct interaction with human annotators. However, ensuring safety remains a critical challenge across many domains and tasks. Previous works on safe RL from human feedback (RLHF) first learn reward and cost models from offline data, then use constrained RL to optimize a safe policy. While such an approach works in the contextual bandits settings (LLMs), in long horizon continuous control tasks, errors in rewards and costs accumulate, leading to impairment in performance when used with constrained RL methods. To address these challenges, (a) instead of indirectly learning policies (from rewards and costs), we introduce a framework that learns a policy directly based on pairwise preferences regarding the agent's behavior in terms of rewards, as well as binary labels indicating the safety of trajectory segments; (b) we propose \textsc{PreSa} (Preference and Safety Alignment), a method that combines preference learning module with safety alignment in a constrained optimization problem. This optimization problem is solved within a Lagrangian paradigm that directly learns reward-maximizing safe policy \textit{without explicitly learning reward and cost models}, avoiding the need for constrained RL; (c) we evaluate our approach on continuous control tasks with both synthetic and real human feedback. Empirically, our method successfully learns safe policies with high rewards, outperforming state-of-the-art baselines, and offline safe RL approaches with ground-truth reward and cost.
TraCeS: Trajectory Based Credit Assignment From Sparse Safety Feedback
Apr 17, 2025In safe reinforcement learning (RL), auxiliary safety costs are used to align the agent to safe decision making. In practice, safety constraints, including cost functions and budgets, are unknown or hard to specify, as it requires anticipation of all possible unsafe behaviors. We therefore address a general setting where the true safety definition is unknown, and has to be learned from sparsely labeled data. Our key contributions are: first, we design a safety model that performs credit assignment to estimate each decision step's impact on the overall safety using a dataset of diverse trajectories and their corresponding binary safety labels (i.e., whether the corresponding trajectory is safe/unsafe). Second, we illustrate the architecture of our safety model to demonstrate its ability to learn a separate safety score for each timestep. Third, we reformulate the safe RL problem using the proposed safety model and derive an effective algorithm to optimize a safe yet rewarding policy. Finally, our empirical results corroborate our findings and show that this approach is effective in satisfying unknown safety definition, and scalable to various continuous control tasks.
Offline Safe Reinforcement Learning Using Trajectory Classification
Dec 19, 2024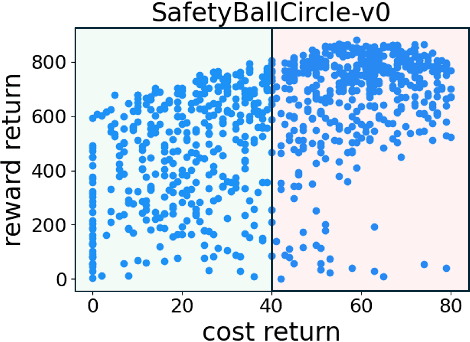


Offline safe reinforcement learning (RL) has emerged as a promising approach for learning safe behaviors without engaging in risky online interactions with the environment. Most existing methods in offline safe RL rely on cost constraints at each time step (derived from global cost constraints) and this can result in either overly conservative policies or violation of safety constraints. In this paper, we propose to learn a policy that generates desirable trajectories and avoids undesirable trajectories. To be specific, we first partition the pre-collected dataset of state-action trajectories into desirable and undesirable subsets. Intuitively, the desirable set contains high reward and safe trajectories, and undesirable set contains unsafe trajectories and low-reward safe trajectories. Second, we learn a policy that generates desirable trajectories and avoids undesirable trajectories, where (un)desirability scores are provided by a classifier learnt from the dataset of desirable and undesirable trajectories. This approach bypasses the computational complexity and stability issues of a min-max objective that is employed in existing methods. Theoretically, we also show our approach's strong connections to existing learning paradigms involving human feedback. Finally, we extensively evaluate our method using the DSRL benchmark for offline safe RL. Empirically, our method outperforms competitive baselines, achieving higher rewards and better constraint satisfaction across a wide variety of benchmark tasks.
A Factored MDP Approach To Moving Target Defense With Dynamic Threat Modeling and Cost Efficiency
Aug 16, 2024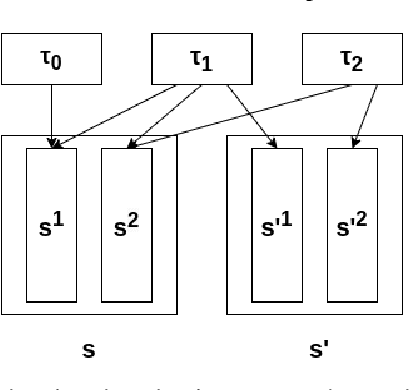


Moving Target Defense (MTD) has emerged as a proactive and dynamic framework to counteract evolving cyber threats. Traditional MTD approaches often rely on assumptions about the attackers knowledge and behavior. However, real-world scenarios are inherently more complex, with adaptive attackers and limited prior knowledge of their payoffs and intentions. This paper introduces a novel approach to MTD using a Markov Decision Process (MDP) model that does not rely on predefined attacker payoffs. Our framework integrates the attackers real-time responses into the defenders MDP using a dynamic Bayesian Network. By employing a factored MDP model, we provide a comprehensive and realistic system representation. We also incorporate incremental updates to an attack response predictor as new data emerges. This ensures an adaptive and robust defense mechanism. Additionally, we consider the costs of switching configurations in MTD, integrating them into the reward structure to balance execution and defense costs. We first highlight the challenges of the problem through a theoretical negative result on regret. However, empirical evaluations demonstrate the frameworks effectiveness in scenarios marked by high uncertainty and dynamically changing attack landscapes.
Safe Reinforcement Learning with Learned Non-Markovian Safety Constraints
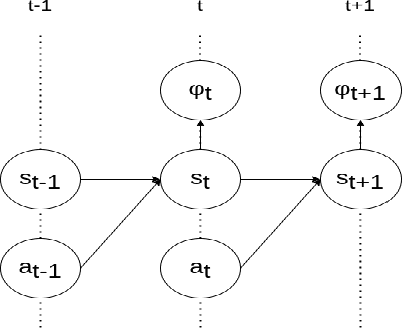
May 05, 2024In safe Reinforcement Learning (RL), safety cost is typically defined as a function dependent on the immediate state and actions. In practice, safety constraints can often be non-Markovian due to the insufficient fidelity of state representation, and safety cost may not be known. We therefore address a general setting where safety labels (e.g., safe or unsafe) are associated with state-action trajectories. Our key contributions are: first, we design a safety model that specifically performs credit assignment to assess contributions of partial state-action trajectories on safety. This safety model is trained using a labeled safety dataset. Second, using RL-as-inference strategy we derive an effective algorithm for optimizing a safe policy using the learned safety model. Finally, we devise a method to dynamically adapt the tradeoff coefficient between reward maximization and safety compliance. We rewrite the constrained optimization problem into its dual problem and derive a gradient-based method to dynamically adjust the tradeoff coefficient during training. Our empirical results demonstrate that this approach is highly scalable and able to satisfy sophisticated non-Markovian safety constraints.
Leveraging AI Planning For Detecting Cloud Security Vulnerabilities
Feb 16, 2024Cloud computing services provide scalable and cost-effective solutions for data storage, processing, and collaboration. Alongside their growing popularity, concerns related to their security vulnerabilities leading to data breaches and sophisticated attacks such as ransomware are growing. To address these, first, we propose a generic framework to express relations between different cloud objects such as users, datastores, security roles, to model access control policies in cloud systems. Access control misconfigurations are often the primary driver for cloud attacks. Second, we develop a PDDL model for detecting security vulnerabilities which can for example lead to widespread attacks such as ransomware, sensitive data exfiltration among others. A planner can then generate attacks to identify such vulnerabilities in the cloud. Finally, we test our approach on 14 real Amazon AWS cloud configurations of different commercial organizations. Our system can identify a broad range of security vulnerabilities, which state-of-the-art industry tools cannot detect.
FlowPG: Action-constrained Policy Gradient with Normalizing Flows
Feb 07, 2024Action-constrained reinforcement learning (ACRL) is a popular approach for solving safety-critical and resource-allocation related decision making problems. A major challenge in ACRL is to ensure agent taking a valid action satisfying constraints in each RL step. Commonly used approach of using a projection layer on top of the policy network requires solving an optimization program which can result in longer training time, slow convergence, and zero gradient problem. To address this, first we use a normalizing flow model to learn an invertible, differentiable mapping between the feasible action space and the support of a simple distribution on a latent variable, such as Gaussian. Second, learning the flow model requires sampling from the feasible action space, which is also challenging. We develop multiple methods, based on Hamiltonian Monte-Carlo and probabilistic sentential decision diagrams for such action sampling for convex and non-convex constraints. Third, we integrate the learned normalizing flow with the DDPG algorithm. By design, a well-trained normalizing flow will transform policy output into a valid action without requiring an optimization solver. Empirically, our approach results in significantly fewer constraint violations (upto an order-of-magnitude for several instances) and is multiple times faster on a variety of continuous control tasks.
Unified Training of Universal Time Series Forecasting Transformers
Feb 04, 2024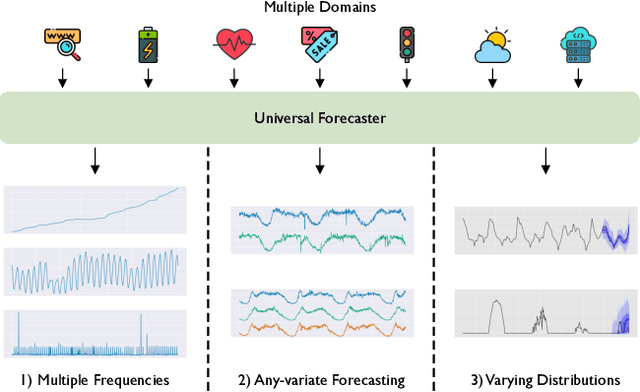

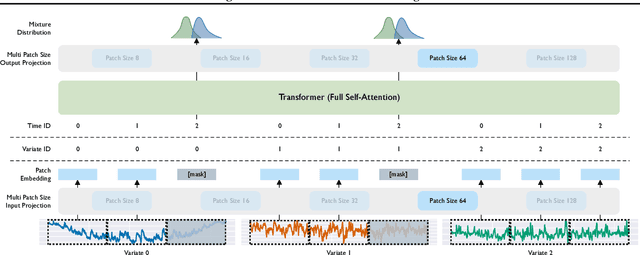

Deep learning for time series forecasting has traditionally operated within a one-model-per-dataset framework, limiting its potential to leverage the game-changing impact of large pre-trained models. The concept of universal forecasting, emerging from pre-training on a vast collection of time series datasets, envisions a single Large Time Series Model capable of addressing diverse downstream forecasting tasks. However, constructing such a model poses unique challenges specific to time series data: i) cross-frequency learning, ii) accommodating an arbitrary number of variates for multivariate time series, and iii) addressing the varying distributional properties inherent in large-scale data. To address these challenges, we present novel enhancements to the conventional time series Transformer architecture, resulting in our proposed Masked Encoder-based Universal Time Series Forecasting Transformer (Moirai). Trained on our newly introduced Large-scale Open Time Series Archive (LOTSA) featuring over 27B observations across nine domains, Moirai achieves competitive or superior performance as a zero-shot forecaster when compared to full-shot models. Code, model weights, and data will be released.
Pushing the Limits of Pre-training for Time Series Forecasting in the CloudOps Domain
Oct 10, 2023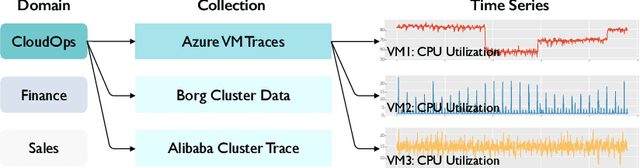

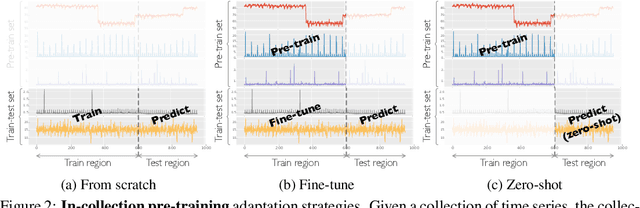

Time series has been left behind in the era of pre-training and transfer learning. While research in the fields of natural language processing and computer vision are enjoying progressively larger datasets to train massive models, the most popular time series datasets consist of only tens of thousands of time steps, limiting our ability to study the effectiveness of pre-training and scaling. Recent studies have also cast doubt on the need for expressive models and scale. To alleviate these issues, we introduce three large-scale time series forecasting datasets from the cloud operations (CloudOps) domain, the largest having billions of observations, enabling further study into pre-training and scaling of time series models. We build the empirical groundwork for studying pre-training and scaling of time series models and pave the way for future research by identifying a promising candidate architecture. We show that it is a strong zero-shot baseline and benefits from further scaling, both in model and dataset size. Accompanying these datasets and results is a suite of comprehensive benchmark results comparing classical and deep learning baselines to our pre-trained method - achieving a 27% reduction in error on the largest dataset. Code and datasets will be released.
Safe MDP Planning by Learning Temporal Patterns of Undesirable Trajectories and Averting Negative Side Effects
Apr 06, 2023In safe MDP planning, a cost function based on the current state and action is often used to specify safety aspects. In the real world, often the state representation used may lack sufficient fidelity to specify such safety constraints. Operating based on an incomplete model can often produce unintended negative side effects (NSEs). To address these challenges, first, we associate safety signals with state-action trajectories (rather than just an immediate state-action). This makes our safety model highly general. We also assume categorical safety labels are given for different trajectories, rather than a numerical cost function, which is harder to specify by the problem designer. We then employ a supervised learning model to learn such non-Markovian safety patterns. Second, we develop a Lagrange multiplier method, which incorporates the safety model and the underlying MDP model in a single computation graph to facilitate agent learning of safe behaviors. Finally, our empirical results on a variety of discrete and continuous domains show that this approach can satisfy complex non-Markovian safety constraints while optimizing an agent's total returns, is highly scalable, and is also better than the previous best approach for Markovian NSEs.