 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascade: Composing Software-Hardware Attack Gadgets for Adversarial Threat Amplification in Compound AI Systems
Mar 12, 2026Rapid progress in generative AI has given rise to Compound AI systems - pipelines comprised of multiple large language models (LLM), software tools and database systems. Compound AI systems are constructed on a layered traditional software stack running on a distributed hardware infrastructure. Many of the diverse software components are vulnerable to traditional security flaws documented in the Common Vulnerabilities and Exposures (CVE) database, while the underlying distributed hardware infrastructure remains exposed to timing attacks, bit-flip faults, and power-based side channels. Today, research targets LLM-specific risks like model extraction, training data leakage, and unsafe generation -- overlooking the impact of traditional system vulnerabilities. This work investigates how traditional software and hardware vulnerabilities can complement LLM-specific algorithmic attacks to compromise the integrity of a compound AI pipeline. We demonstrate two novel attacks that combine system-level vulnerabilities with algorithmic weaknesses: (1) Exploiting a software code injection flaw along with a guardrail Rowhammer attack to inject an unaltered jailbreak prompt into an LLM, resulting in an AI safety violation, and (2) Manipulating a knowledge database to redirect an LLM agent to transmit sensitive user data to a malicious application, thus breaching confidentiality. These attacks highlight the need to address traditional vulnerabilities; we systematize the attack primitives and analyze their composition by grouping vulnerabilities by their objective and mapping them to distinct stages of an attack lifecycle. This approach enables a rigorous red-teaming exercise and lays the groundwork for future defense strategies.
Towards Reinforcement Learning for Exploration of Speculative Execution Vulnerabilities
Feb 24, 2025Speculative attacks such as Spectre can leak secret information without being discovered by the operating system. Speculative execution vulnerabilities are finicky and deep in the sense that to exploit them, it requires intensive manual labor and intimate knowledge of the hardware. In this paper, we introduce SpecRL, a framework that utilizes reinforcement learning to find speculative execution leaks in post-silicon (black box) microprocessors.
SoK: A Systems Perspective on Compound AI Threats and Countermeasures
Nov 20, 2024



Large language models (LLMs) used across enterprises often use proprietary models and operate on sensitive inputs and data. The wide range of attack vectors identified in prior research - targeting various software and hardware components used in training and inference - makes it extremely challenging to enforce confidentiality and integrity policies. As we advance towards constructing compound AI inference pipelines that integrate multiple large language models (LLMs), the attack surfaces expand significantly. Attackers now focus on the AI algorithms as well as the software and hardware components associated with these systems. While current research often examines these elements in isolation, we find that combining cross-layer attack observations can enable powerful end-to-end attacks with minimal assumptions about the threat model. Given, the sheer number of existing attacks at each layer, we need a holistic and systemized understanding of different attack vectors at each layer. This SoK discusses different software and hardware attacks applicable to compound AI systems and demonstrates how combining multiple attack mechanisms can reduce the threat model assumptions required for an isolated attack. Next, we systematize the ML attacks in lines with the Mitre Att&ck framework to better position each attack based on the threat model. Finally, we outline the existing countermeasures for both software and hardware layers and discuss the necessity of a comprehensive defense strategy to enable the secure and high-performance deployment of compound AI systems.
Obsidian: Cooperative State-Space Exploration for Performant Inference on Secure ML Accelerators
Sep 04, 2024Trusted execution environments (TEEs) for machine learning accelerators are indispensable in secure and efficient ML inference. Optimizing workloads through state-space exploration for the accelerator architectures improves performance and energy consumption. However, such explorations are expensive and slow due to the large search space. Current research has to use fast analytical models that forego critical hardware details and cross-layer opportunities unique to the hardware security primitives. While cycle-accurate models can theoretically reach better designs, their high runtime cost restricts them to a smaller state space. We present Obsidian, an optimization framework for finding the optimal mapping from ML kernels to a secure ML accelerator. Obsidian addresses the above challenge by exploring the state space using analytical and cycle-accurate models cooperatively. The two main exploration components include: (1) A secure accelerator analytical model, that includes the effect of secure hardware while traversing the large mapping state space and produce the best m model mappings; (2) A compiler profiling step on a cycle-accurate model, that captures runtime bottlenecks to further improve execution runtime, energy and resource utilization and find the optimal model mapping. We compare our results to a baseline secure accelerator, comprising of the state-of-the-art security schemes obtained from guardnn [ 33 ] and sesame [11]. The analytical model reduces the inference latency by 20.5% for a cloud and 8.4% for an edge deployment with an energy improvement of 24% and 19% respectively. The cycle-accurate model, further reduces the latency by 9.1% for a cloud and 12.2% for an edge with an energy improvement of 13.8% and 13.1%.
ConfusedPilot: Confused Deputy Risks in RAG-based LLMs
Aug 15, 2024Retrieval augmented generation (RAG) is a process where a large language model (LLM) retrieves useful information from a database and then generates the responses. It is becoming popular in enterprise settings for daily business operations. For example, Copilot for Microsoft 365 has accumulated millions of businesses. However, the security implications of adopting such RAG-based systems are unclear. In this paper, we introduce ConfusedPilot, a class of security vulnerabilities of RAG systems that confuse Copilot and cause integrity and confidentiality violations in its responses. First, we investigate a vulnerability that embeds malicious text in the modified prompt in RAG, corrupting the responses generated by the LLM. Second, we demonstrate a vulnerability that leaks secret data, which leverages the caching mechanism during retrieval. Third, we investigate how both vulnerabilities can be exploited to propagate misinformation within the enterprise and ultimately impact its operations, such as sales and manufacturing. We also discuss the root cause of these attacks by investigating the architecture of a RAG-based system. This study highlights the security vulnerabilities in today's RAG-based systems and proposes design guidelines to secure future RAG-based systems.
ConfusedPilot: Compromising Enterprise Information Integrity and Confidentiality with Copilot for Microsoft 365
Aug 09, 2024Retrieval augmented generation (RAG) is a process where a large language model (LLM) retrieves useful information from a database and then generates the responses. It is becoming popular in enterprise settings for daily business operations. For example, Copilot for Microsoft 365 has accumulated millions of businesses. However, the security implications of adopting such RAG-based systems are unclear. In this paper, we introduce ConfusedPilot, a class of security vulnerabilities of RAG systems that confuse Copilot and cause integrity and confidentiality violations in its responses. First, we investigate a vulnerability that embeds malicious text in the modified prompt in RAG, corrupting the responses generated by the LLM. Second, we demonstrate a vulnerability that leaks secret data, which leverages the caching mechanism during retrieval. Third, we investigate how both vulnerabilities can be exploited to propagate misinformation within the enterprise and ultimately impact its operations, such as sales and manufacturing. We also discuss the root cause of these attacks by investigating the architecture of a RAG-based system. This study highlights the security vulnerabilities in today's RAG-based systems and proposes design guidelines to secure future RAG-based systems.
Leveraging AI Planning For Detecting Cloud Security Vulnerabilities
Feb 16, 2024Cloud computing services provide scalable and cost-effective solutions for data storage, processing, and collaboration. Alongside their growing popularity, concerns related to their security vulnerabilities leading to data breaches and sophisticated attacks such as ransomware are growing. To address these, first, we propose a generic framework to express relations between different cloud objects such as users, datastores, security roles, to model access control policies in cloud systems. Access control misconfigurations are often the primary driver for cloud attacks. Second, we develop a PDDL model for detecting security vulnerabilities which can for example lead to widespread attacks such as ransomware, sensitive data exfiltration among others. A planner can then generate attacks to identify such vulnerabilities in the cloud. Finally, we test our approach on 14 real Amazon AWS cloud configurations of different commercial organizations. Our system can identify a broad range of security vulnerabilities, which state-of-the-art industry tools cannot detect.
Using Constraint Programming and Graph Representation Learning for Generating Interpretable Cloud Security Policies
May 08, 2022
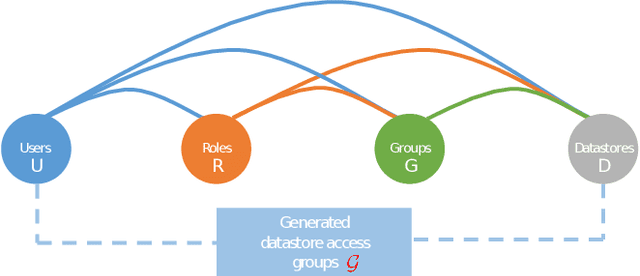


Modern software systems rely on mining insights from business sensitive data stored in public clouds. A data breach usually incurs significant (monetary) loss for a commercial organization. Conceptually, cloud security heavily relies on Identity Access Management (IAM) policies that IT admins need to properly configure and periodically update. Security negligence and human errors often lead to misconfiguring IAM policies which may open a backdoor for attackers. To address these challenges, first, we develop a novel framework that encodes generating optimal IAM policies using constraint programming (CP). We identify reducing dark permissions of cloud users as an optimality criterion, which intuitively implies minimizing unnecessary datastore access permissions. Second, to make IAM policies interpretable, we use graph representation learning applied to historical access patterns of users to augment our CP model with similarity constraints: similar users should be grouped together and share common IAM policies. Third, we describe multiple attack models and show that our optimized IAM policies significantly reduce the impact of security attacks using real data from 8 commercial organizations, and synthetic instances.
NeuroComb: Improving SAT Solving with Graph Neural Networks
Oct 28, 2021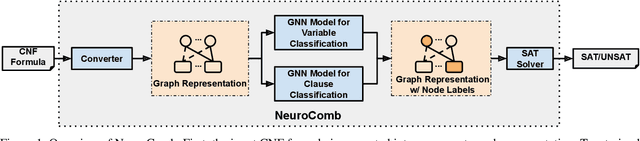
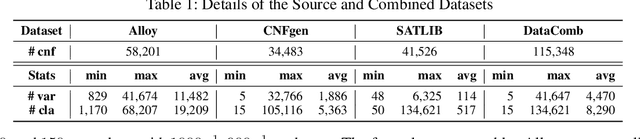
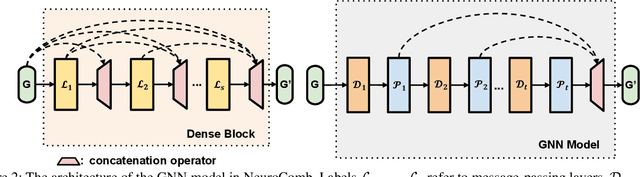
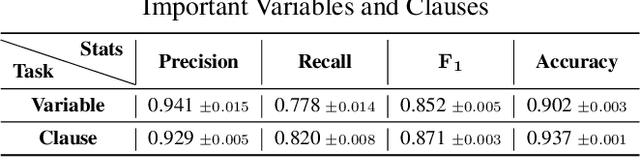
Propositional satisfiability (SAT) is an NP-complete problem that impacts many research fields, such as planning, verification, and security. Despite the remarkable success of modern SAT solvers, scalability still remains a challenge. Main stream modern SAT solvers are based on the Conflict-Driven Clause Learning (CDCL) algorithm. Recent work aimed to enhance CDCL SAT solvers by improving its variable branching heuristics through predictions generated by Graph Neural Networks (GNNs). However, so far this approach either has not made solving more effective, or has required frequent online accesses to substantial GPU resources. Aiming to make GNN improvements practical, this paper proposes an approach called NeuroComb, which builds on two insights: (1) predictions of important variables and clauses can be combined with dynamic branching into a more effective hybrid branching strategy, and (2) it is sufficient to query the neural model only once for the predictions before the SAT solving starts. Implemented as an enhancement to the classic MiniSat solver, NeuroComb allowed it to solve 18.5% more problems on the recent SATCOMP-2020 competition problem set. NeuroComb is therefore a practical approach to improving SAT solving through modern machine learning.
Power-Based Attacks on Spatial DNN Accelerators
Aug 28, 2021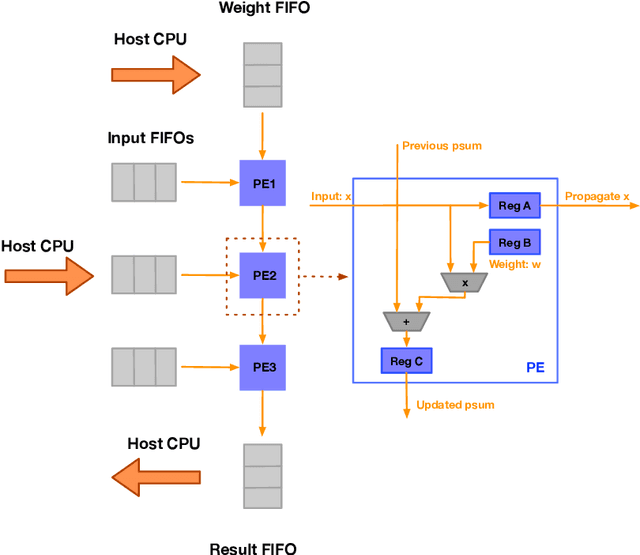

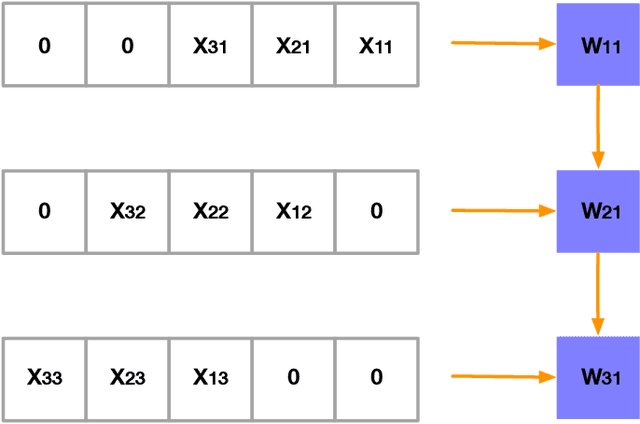
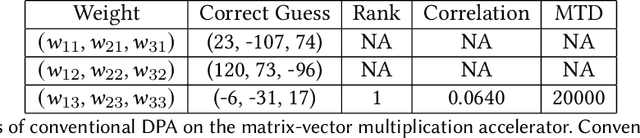
With proliferation of DNN-based applications, the confidentiality of DNN model is an important commercial goal. Spatial accelerators, that parallelize matrix/vector operations, are utilized for enhancing energy efficiency of DNN computation. Recently, model extraction attacks on simple accelerators, either with a single processing element or running a binarized network, were demonstrated using the methodology derived from differential power analysis (DPA) attack on cryptographic devices. This paper investigates the vulnerability of realistic spatial accelerators using general, 8-bit, number representation. We investigate two systolic array architectures with weight-stationary dataflow: (1) a 3 $\times$ 1 array for a dot-product operation, and (2) a 3 $\times$ 3 array for matrix-vector multiplication. Both are implemented on the SAKURA-G FPGA board. We show that both architectures are ultimately vulnerable. A conventional DPA succeeds fully on the 1D array, requiring 20K power measurements. However, the 2D array exhibits higher security even with 460K traces. We show that this is because the 2D array intrinsically entails multiple MACs simultaneously dependent on the same input. However, we find that a novel template-based DPA with multiple profiling phases is able to fully break the 2D array with only 40K traces. Corresponding countermeasures need to be investigated for spatial DNN accelerators.