 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObsidian: Cooperative State-Space Exploration for Performant Inference on Secure ML Accelerators
Sep 04, 2024Trusted execution environments (TEEs) for machine learning accelerators are indispensable in secure and efficient ML inference. Optimizing workloads through state-space exploration for the accelerator architectures improves performance and energy consumption. However, such explorations are expensive and slow due to the large search space. Current research has to use fast analytical models that forego critical hardware details and cross-layer opportunities unique to the hardware security primitives. While cycle-accurate models can theoretically reach better designs, their high runtime cost restricts them to a smaller state space. We present Obsidian, an optimization framework for finding the optimal mapping from ML kernels to a secure ML accelerator. Obsidian addresses the above challenge by exploring the state space using analytical and cycle-accurate models cooperatively. The two main exploration components include: (1) A secure accelerator analytical model, that includes the effect of secure hardware while traversing the large mapping state space and produce the best m model mappings; (2) A compiler profiling step on a cycle-accurate model, that captures runtime bottlenecks to further improve execution runtime, energy and resource utilization and find the optimal model mapping. We compare our results to a baseline secure accelerator, comprising of the state-of-the-art security schemes obtained from guardnn [ 33 ] and sesame [11]. The analytical model reduces the inference latency by 20.5% for a cloud and 8.4% for an edge deployment with an energy improvement of 24% and 19% respectively. The cycle-accurate model, further reduces the latency by 9.1% for a cloud and 12.2% for an edge with an energy improvement of 13.8% and 13.1%.
Shredder: Learning Noise to Protect Privacy with Partial DNN Inference on the Edge
May 26, 2019
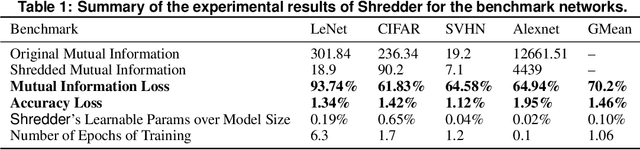
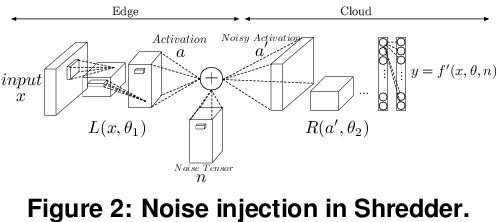
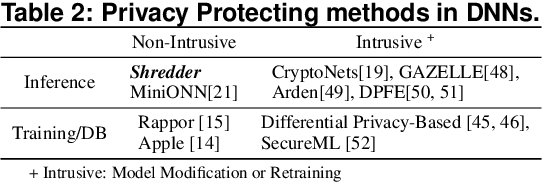
A wide variety of DNN applications increasingly rely on the cloud to perform their huge computation. This heavy trend toward cloud-hosted inference services raises serious privacy concerns. This model requires the sending of private and privileged data over the network to remote servers, exposing it to the service provider. Even if the provider is trusted, the data can still be vulnerable over communication channels or via side-channel attacks [1,2] at the provider. To that end, this paper aims to reduce the information content of the communicated data without compromising the cloud service's ability to provide a DNN inference with acceptably high accuracy. This paper presents an end-to-end framework, called Shredder, that, without altering the topology or the weights of a pre-trained network, learns an additive noise distribution that significantly reduces the information content of communicated data while maintaining the inference accuracy. Shredder learns the additive noise by casting it as a tensor of trainable parameters enabling us to devise a loss functions that strikes a balance between accuracy and information degradation. The loss function exposes a knob for a disciplined and controlled asymmetric trade-off between privacy and accuracy. While keeping the DNN intact, Shredder enables inference on noisy data without the need to update the model or the cloud. Experimentation with real-world DNNs shows that Shredder reduces the mutual information between the input and the communicated data to the cloud by 70.2% compared to the original execution while only sacrificing 1.46% loss in accuracy.