 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOLT: Lightweight Multi-LLM Collaboration through Shared MCTS Reasoning for Model Compilation
Feb 02, 2026Model serving costs dominate AI systems, making compiler optimization essential for scalable deployment. Recent works show that a large language model (LLM) can guide compiler search by reasoning over program structure and optimization history. However, using a single large model throughout the search is expensive, while smaller models are less reliable when used alone. Thus, this paper seeks to answer whether multi-LLM collaborative reasoning relying primarily on small LLMs can match or exceed the performance of a single large model. As such, we propose a lightweight collaborative multi-LLM framework, dubbed COLT, for compiler optimization that enables coordinated reasoning across multiple models within a single Monte Carlo tree search (MCTS) process. A key contribution is the use of a single shared MCTS tree as the collaboration substrate across LLMs, enabling the reuse of transformation prefixes and cross-model value propagation. Hence, we circumvent both heavy internal reasoning mechanisms and conventional agentic machinery that relies on external planners, multiple concurrent LLMs, databases, external memory/versioning of intermediate results, and controllers by simply endogenizing model selection within the lightweight MCTS optimization loop. Every iteration, the acting LLM proposes a joint action: (compiler transformation, model to be queried next). We also introduce a model-aware tree policy that biases search toward smaller models while preserving exploration, and a course-alteration mechanism that escalates to the largest model when the search exhibits persistent regressions attributable to smaller models.
An Open-Source ML-Based Full-Stack Optimization Framework for Machine Learning Accelerators
Aug 23, 2023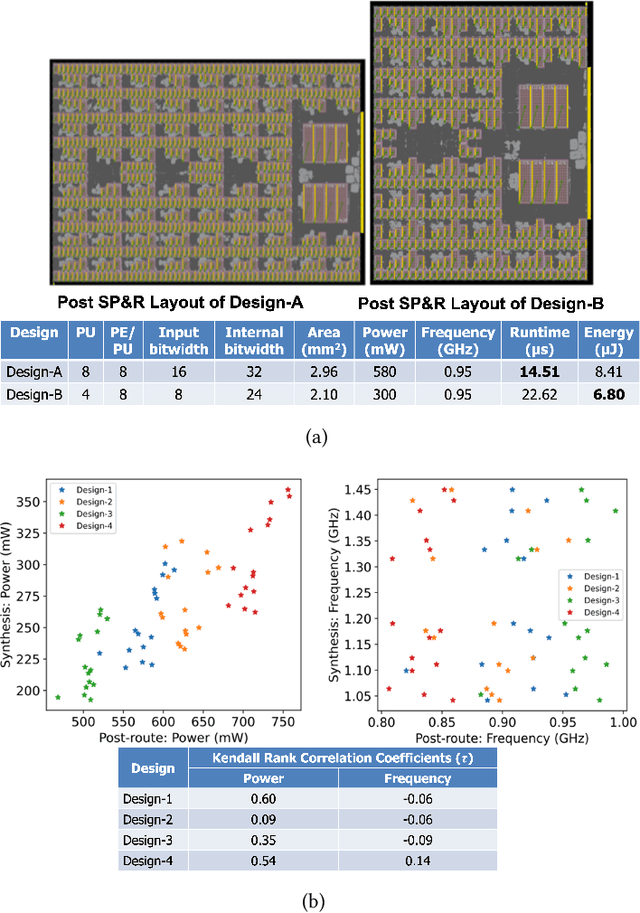
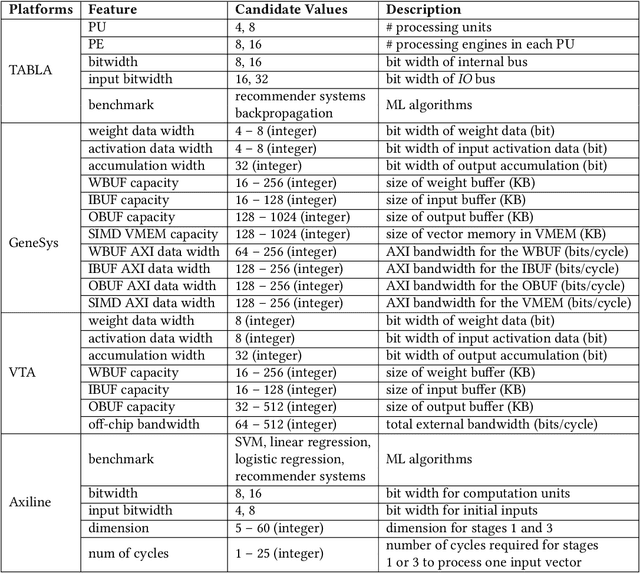
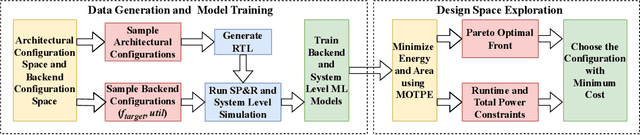
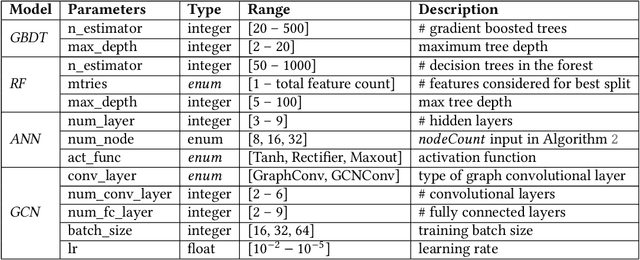
Parameterizable machine learning (ML) accelerators are the product of recent breakthroughs in ML. To fully enable their design space exploration (DSE), we propose a physical-design-driven, learning-based prediction framework for hardware-accelerated deep neural network (DNN) and non-DNN ML algorithms. It adopts a unified approach that combines backend power, performance, and area (PPA) analysis with frontend performance simulation, thereby achieving a realistic estimation of both backend PPA and system metrics such as runtime and energy. In addition, our framework includes a fully automated DSE technique, which optimizes backend and system metrics through an automated search of architectural and backend parameters. Experimental studies show that our approach consistently predicts backend PPA and system metrics with an average 7% or less prediction error for the ASIC implementation of two deep learning accelerator platforms, VTA and VeriGOOD-ML, in both a commercial 12 nm process and a research-oriented 45 nm process.
Performance Analysis of DNN Inference/Training with Convolution and non-Convolution Operations
Jun 29, 2023Today's performance analysis frameworks for deep learning accelerators suffer from two significant limitations. First, although modern convolutional neural network (CNNs) consist of many types of layers other than convolution, especially during training, these frameworks largely focus on convolution layers only. Second, these frameworks are generally targeted towards inference, and lack support for training operations. This work proposes a novel performance analysis framework, SimDIT, for general ASIC-based systolic hardware accelerator platforms. The modeling effort of SimDIT comprehensively covers convolution and non-convolution operations of both CNN inference and training on a highly parameterizable hardware substrate. SimDIT is integrated with a backend silicon implementation flow and provides detailed end-to-end performance statistics (i.e., data access cost, cycle counts, energy, and power) for executing CNN inference and training workloads. SimDIT-enabled performance analysis reveals that on a 64X64 processing array, non-convolution operations constitute 59.5% of total runtime for ResNet-50 training workload. In addition, by optimally distributing available off-chip DRAM bandwidth and on-chip SRAM resources, SimDIT achieves 18X performance improvement over a generic static resource allocation for ResNet-50 inference.
Accelerating Attention through Gradient-Based Learned Runtime Pruning
Apr 15, 2022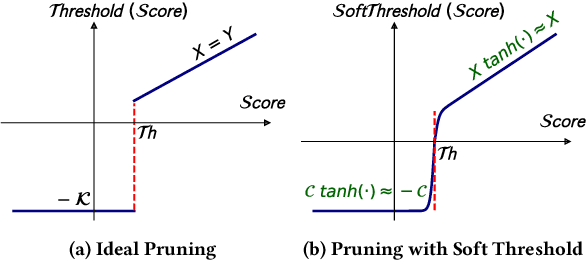



Self-attention is a key enabler of state-of-art accuracy for various transformer-based Natural Language Processing models. This attention mechanism calculates a correlation score for each word with respect to the other words in a sentence. Commonly, only a small subset of words highly correlates with the word under attention, which is only determined at runtime. As such, a significant amount of computation is inconsequential due to low attention scores and can potentially be pruned. The main challenge is finding the threshold for the scores below which subsequent computation will be inconsequential. Although such a threshold is discrete, this paper formulates its search through a soft differentiable regularizer integrated into the loss function of the training. This formulation piggy backs on the back-propagation training to analytically co-optimize the threshold and the weights simultaneously, striking a formally optimal balance between accuracy and computation pruning. To best utilize this mathematical innovation, we devise a bit-serial architecture, dubbed LeOPArd, for transformer language models with bit-level early termination microarchitectural mechanism. We evaluate our design across 43 back-end tasks for MemN2N, BERT, ALBERT, GPT-2, and Vision transformer models. Post-layout results show that, on average, LeOPArd yields 1.9x and 3.9x speedup and energy reduction, respectively, while keeping the average accuracy virtually intact (<0.2% degradation)
Conscious AI
May 12, 2021Recent advances in artificial intelligence (AI) have achieved human-scale speed and accuracy for classification tasks. In turn, these capabilities have made AI a viable replacement for many human activities that at their core involve classification, such as basic mechanical and analytical tasks in low-level service jobs. Current systems do not need to be conscious to recognize patterns and classify them. However, for AI to progress to more complicated tasks requiring intuition and empathy, it must develop capabilities such as metathinking, creativity, and empathy akin to human self-awareness or consciousness. We contend that such a paradigm shift is possible only through a fundamental shift in the state of artificial intelligence toward consciousness, a shift similar to what took place for humans through the process of natural selection and evolution. As such, this paper aims to theoretically explore the requirements for the emergence of consciousness in AI. It also provides a principled understanding of how conscious AI can be detected and how it might be manifested in contrast to the dominant paradigm that seeks to ultimately create machines that are linguistically indistinguishable from humans.
Privacy in Deep Learning: A Survey
May 09, 2020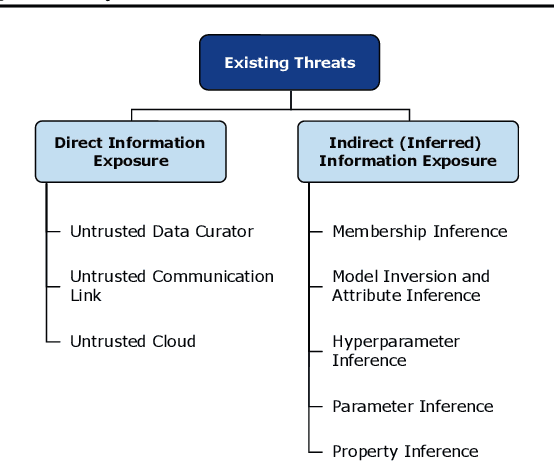


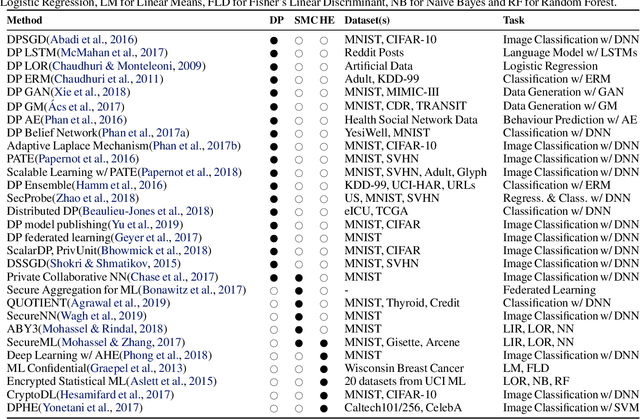
The ever-growing advances of deep learning in many areas including vision, recommendation systems, natural language processing, etc., have led to the adoption of Deep Neural Networks (DNNs) in production systems. The availability of large datasets and high computational power are the main contributors to these advances. The datasets are usually crowdsourced and may contain sensitive information. This poses serious privacy concerns as this data can be misused or leaked through various vulnerabilities. Even if the cloud provider and the communication link is trusted, there are still threats of inference attacks where an attacker could speculate properties of the data used for training, or find the underlying model architecture and parameters. In this survey, we review the privacy concerns brought by deep learning, and the mitigating techniques introduced to tackle these issues. We also show that there is a gap in the literature regarding test-time inference privacy, and propose possible future research directions.
Bit-Parallel Vector Composability for Neural Acceleration
Apr 11, 2020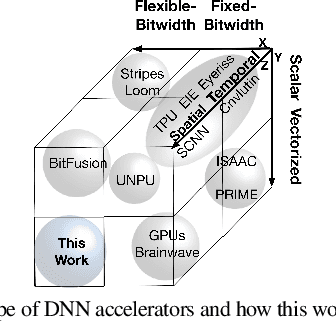
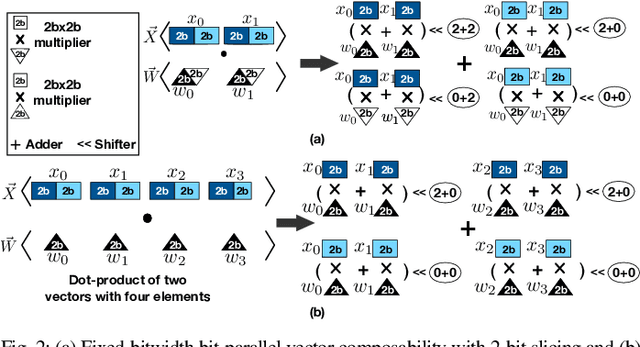
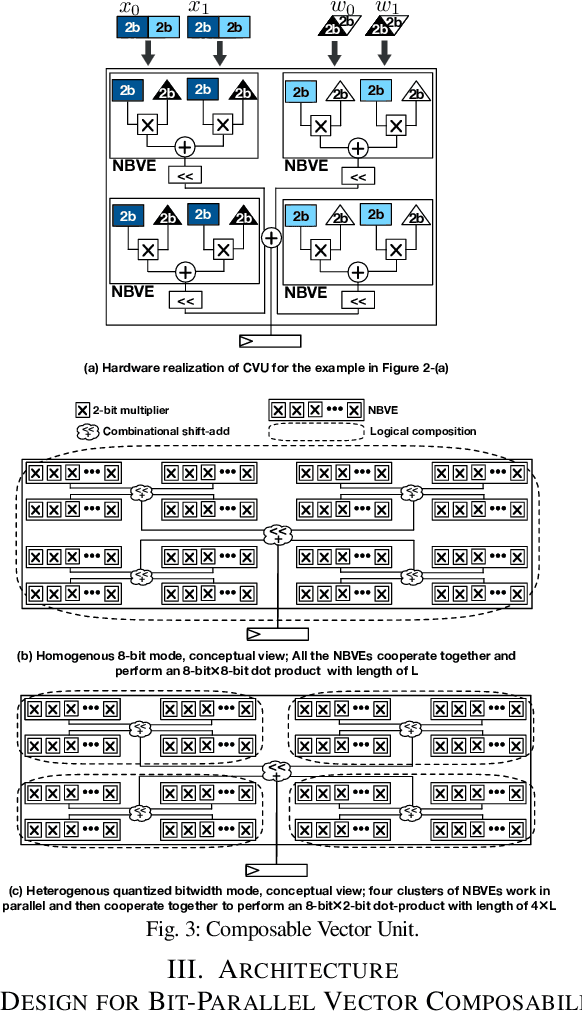
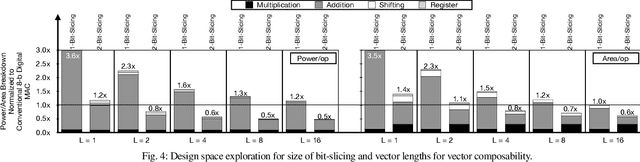
Conventional neural accelerators rely on isolated self-sufficient functional units that perform an atomic operation while communicating the results through an operand delivery-aggregation logic. Each single unit processes all the bits of their operands atomically and produce all the bits of the results in isolation. This paper explores a different design style, where each unit is only responsible for a slice of the bit-level operations to interleave and combine the benefits of bit-level parallelism with the abundant data-level parallelism in deep neural networks. A dynamic collection of these units cooperate at runtime to generate bits of the results, collectively. Such cooperation requires extracting new grouping between the bits, which is only possible if the operands and operations are vectorizable. The abundance of Data Level Parallelism and mostly repeated execution patterns, provides a unique opportunity to define and leverage this new dimension of Bit-Parallel Vector Composability. This design intersperses bit parallelism within data-level parallelism and dynamically interweaves the two together. As such, the building block of our neural accelerator is a Composable Vector Unit that is a collection of Narrower-Bitwidth Vector Engines, which are dynamically composed or decomposed at the bit granularity. Using six diverse CNN and LSTM deep networks, we evaluate this design style across four design points: with and without algorithmic bitwidth heterogeneity and with and without availability of a high-bandwidth off-chip memory. Across these four design points, Bit-Parallel Vector Composability brings (1.4x to 3.5x) speedup and (1.1x to 2.7x) energy reduction. We also comprehensively compare our design style to the Nvidia RTX 2080 TI GPU, which also supports INT-4 execution. The benefits range between 28.0x and 33.7x improvement in Performance-per-Watt.
A Principled Approach to Learning Stochastic Representations for Privacy in Deep Neural Inference
Mar 26, 2020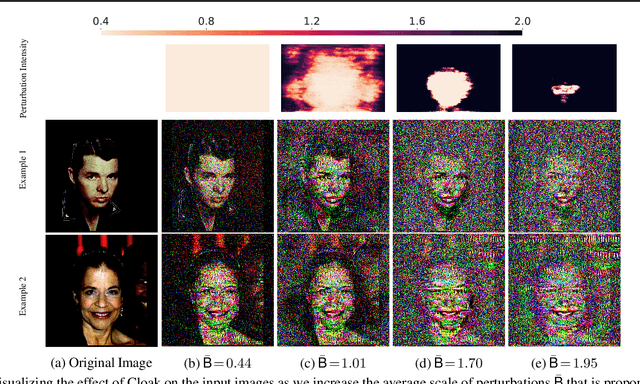
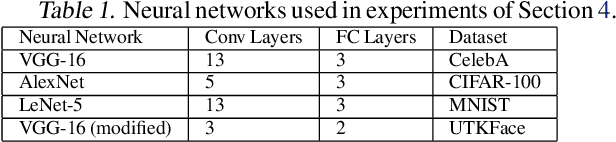
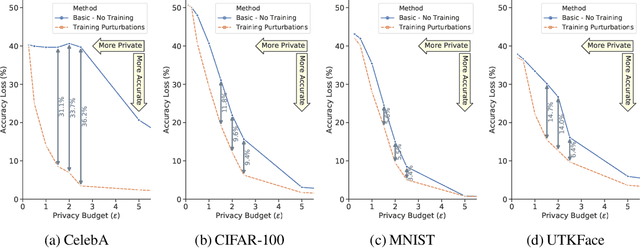
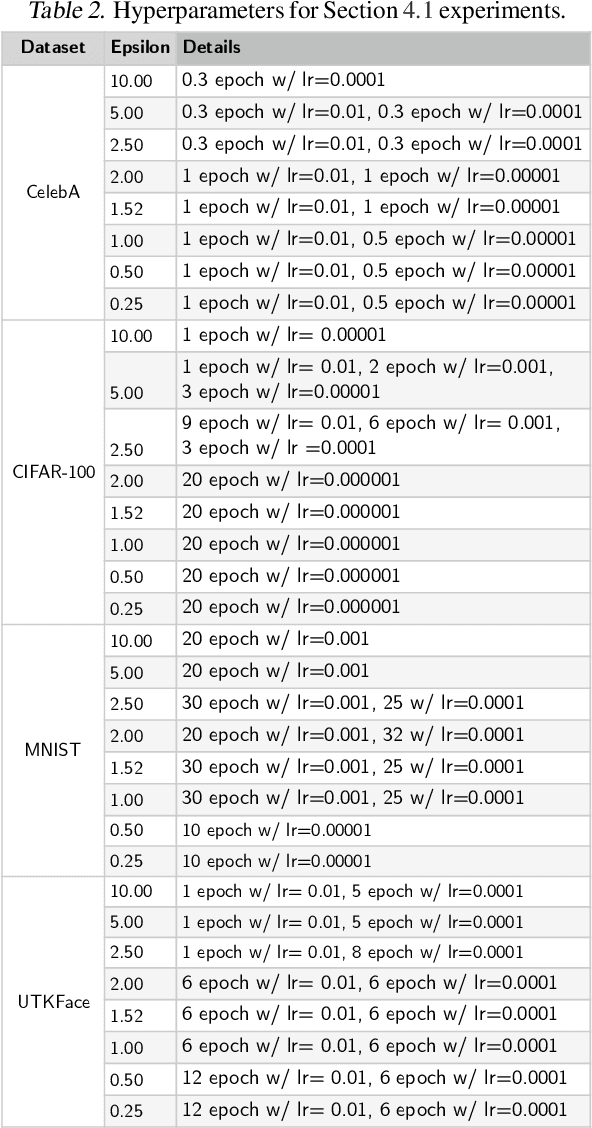
INFerence-as-a-Service (INFaaS) in the cloud has enabled the prevalent use of Deep Neural Networks (DNNs) in home automation, targeted advertising, machine vision, etc. The cloud receives the inference request as a raw input, containing a rich set of private information, that can be misused or leaked, possibly inadvertently. This prevalent setting can compromise the privacy of users during the inference phase. This paper sets out to provide a principled approach, dubbed Cloak, that finds optimal stochastic perturbations to obfuscate the private data before it is sent to the cloud. To this end, Cloak reduces the information content of the transmitted data while conserving the essential pieces that enable the request to be serviced accurately. The key idea is formulating the discovery of this stochasticity as an offline gradient-based optimization problem that reformulates a pre-trained DNN (with optimized known weights) as an analytical function of the stochastic perturbations. Using Laplace distribution as a parametric model for the stochastic perturbations, Cloak learns the optimal parameters using gradient descent and Monte Carlo sampling. This set of optimized Laplace distributions further guarantee that the injected stochasticity satisfies the -differential privacy criterion. Experimental evaluations with real-world datasets show that, on average, the injected stochasticity can reduce the information content in the input data by 80.07%, while incurring 7.12% accuracy loss.
Ordering Chaos: Memory-Aware Scheduling of Irregularly Wired Neural Networks for Edge Devices
Mar 04, 2020
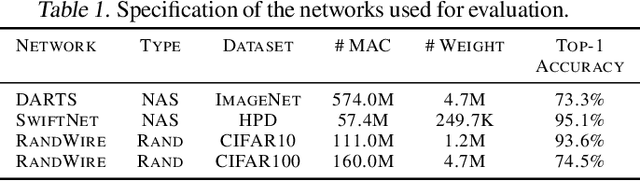
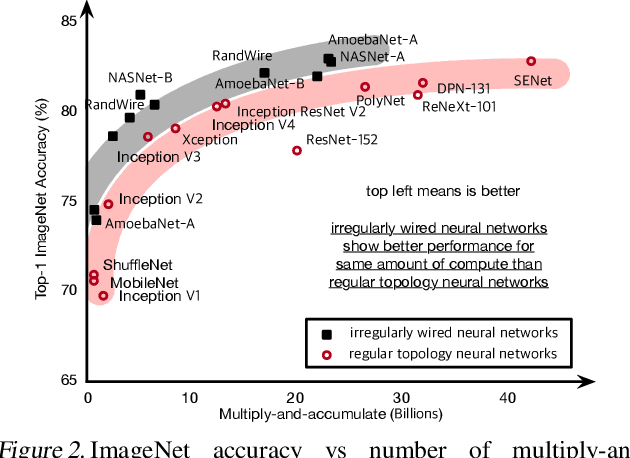
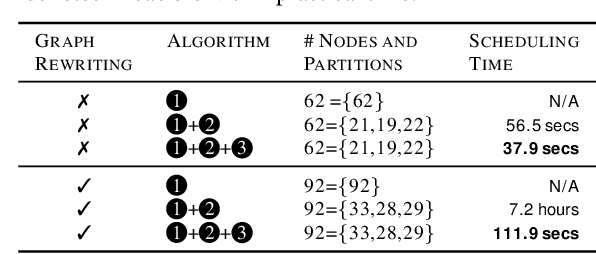
Recent advances demonstrate that irregularly wired neural networks from Neural Architecture Search (NAS) and Random Wiring can not only automate the design of deep neural networks but also emit models that outperform previous manual designs. These designs are especially effective while designing neural architectures under hard resource constraints (memory, MACs, . . . ) which highlights the importance of this class of designing neural networks. However, such a move creates complication in the previously streamlined pattern of execution. In fact one of the main challenges is that the order of such nodes in the neural network significantly effects the memory footprint of the intermediate activations. Current compilers do not schedule with regard to activation memory footprint that it significantly increases its peak compared to the optimum, rendering it not applicable for edge devices. To address this standing issue, we present a memory-aware compiler, dubbed SERENITY, that utilizes dynamic programming to find a sequence that finds a schedule with optimal memory footprint. Our solution also comprises of graph rewriting technique that allows further reduction beyond the optimum. As such, SERENITY achieves optimal peak memory, and the graph rewriting technique further improves this resulting in 1.68x improvement with dynamic programming-based scheduler and 1.86x with graph rewriting, against TensorFlow Lite with less than one minute overhead.
Gradient-Based Deep Quantization of Neural Networks through Sinusoidal Adaptive Regularization
Feb 29, 2020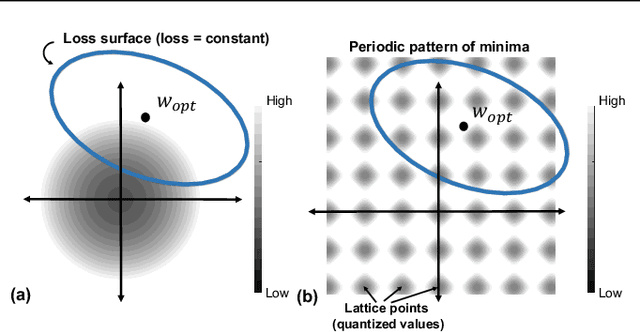
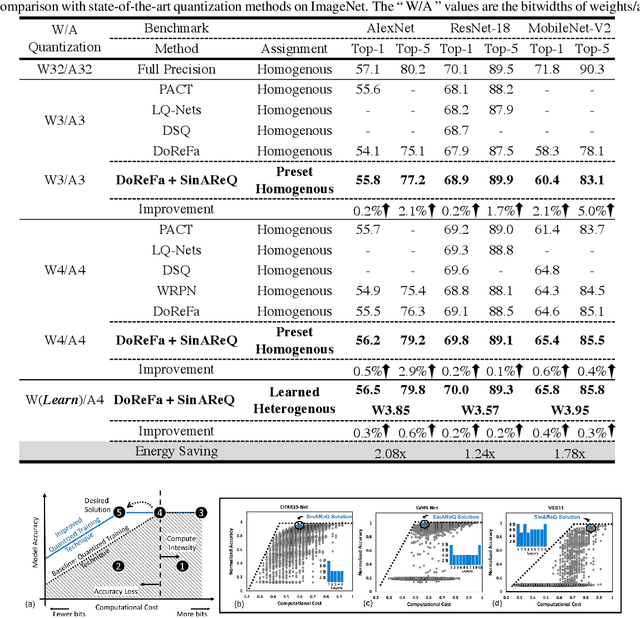
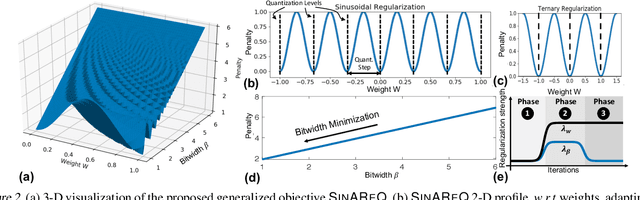
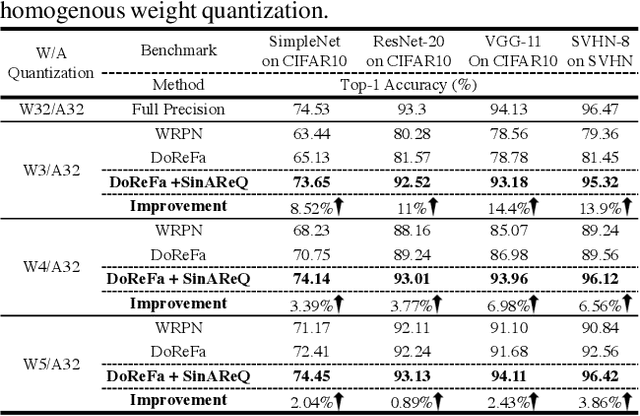
As deep neural networks make their ways into different domains, their compute efficiency is becoming a first-order constraint. Deep quantization, which reduces the bitwidth of the operations (below 8 bits), offers a unique opportunity as it can reduce both the storage and compute requirements of the network super-linearly. However, if not employed with diligence, this can lead to significant accuracy loss. Due to the strong inter-dependence between layers and exhibiting different characteristics across the same network, choosing an optimal bitwidth per layer granularity is not a straight forward. As such, deep quantization opens a large hyper-parameter space, the exploration of which is a major challenge. We propose a novel sinusoidal regularization, called SINAREQ, for deep quantized training. Leveraging the sinusoidal properties, we seek to learn multiple quantization parameterization in conjunction during gradient-based training process. Specifically, we learn (i) a per-layer quantization bitwidth along with (ii) a scale factor through learning the period of the sinusoidal function. At the same time, we exploit the periodicity, differentiability, and the local convexity profile in sinusoidal functions to automatically propel (iii) network weights towards values quantized at levels that are jointly determined. We show how SINAREQ balance compute efficiency and accuracy, and provide a heterogeneous bitwidth assignment for quantization of a large variety of deep networks (AlexNet, CIFAR-10, MobileNet, ResNet-18, ResNet-20, SVHN, and VGG-11) that virtually preserves the accuracy. Furthermore, we carry out experimentation using fixed homogenous bitwidths with 3- to 5-bit assignment and show the versatility of SINAREQ in enhancing quantized training algorithms (DoReFa and WRPN) with about 4.8% accuracy improvements on average, and then outperforming multiple state-of-the-art techniques.