 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-Based Deep Quantization of Neural Networks through Sinusoidal Adaptive Regularization
Feb 29, 2020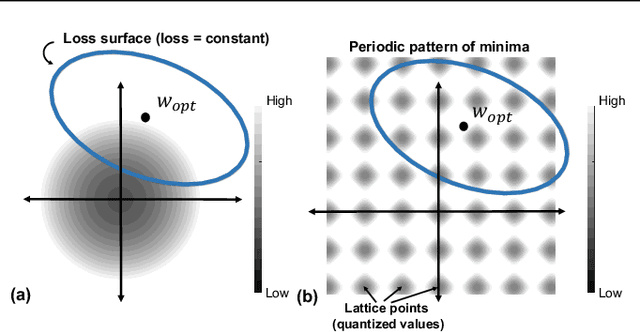
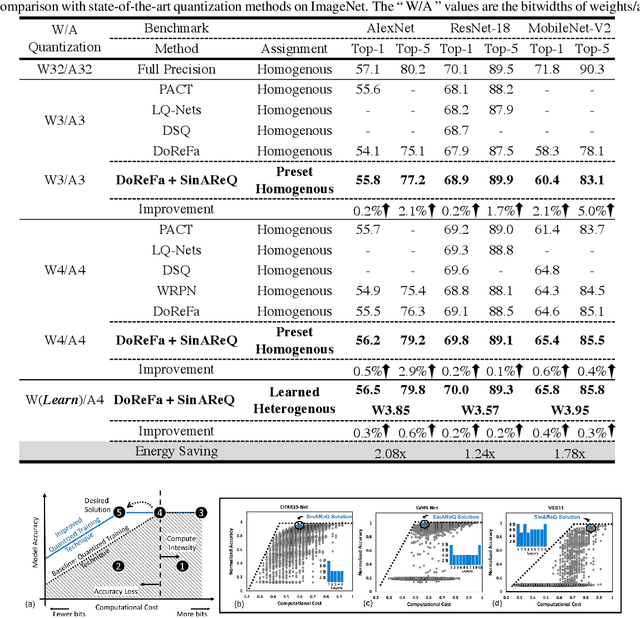
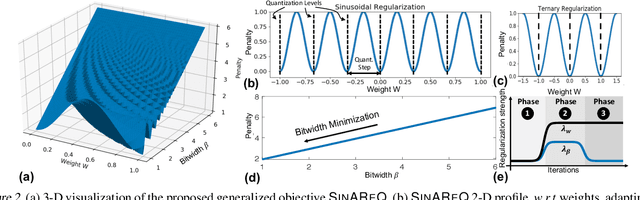
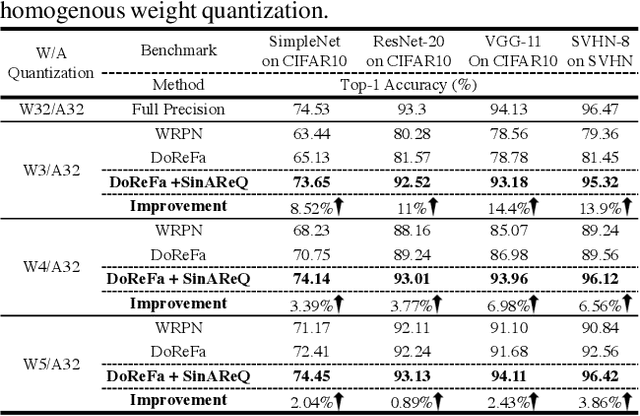
As deep neural networks make their ways into different domains, their compute efficiency is becoming a first-order constraint. Deep quantization, which reduces the bitwidth of the operations (below 8 bits), offers a unique opportunity as it can reduce both the storage and compute requirements of the network super-linearly. However, if not employed with diligence, this can lead to significant accuracy loss. Due to the strong inter-dependence between layers and exhibiting different characteristics across the same network, choosing an optimal bitwidth per layer granularity is not a straight forward. As such, deep quantization opens a large hyper-parameter space, the exploration of which is a major challenge. We propose a novel sinusoidal regularization, called SINAREQ, for deep quantized training. Leveraging the sinusoidal properties, we seek to learn multiple quantization parameterization in conjunction during gradient-based training process. Specifically, we learn (i) a per-layer quantization bitwidth along with (ii) a scale factor through learning the period of the sinusoidal function. At the same time, we exploit the periodicity, differentiability, and the local convexity profile in sinusoidal functions to automatically propel (iii) network weights towards values quantized at levels that are jointly determined. We show how SINAREQ balance compute efficiency and accuracy, and provide a heterogeneous bitwidth assignment for quantization of a large variety of deep networks (AlexNet, CIFAR-10, MobileNet, ResNet-18, ResNet-20, SVHN, and VGG-11) that virtually preserves the accuracy. Furthermore, we carry out experimentation using fixed homogenous bitwidths with 3- to 5-bit assignment and show the versatility of SINAREQ in enhancing quantized training algorithms (DoReFa and WRPN) with about 4.8% accuracy improvements on average, and then outperforming multiple state-of-the-art techniques.
Chameleon: Adaptive Code Optimization for Expedited Deep Neural Network Compilation
Jan 23, 2020



Achieving faster execution with shorter compilation time can foster further diversity and innovation in neural networks. However, the current paradigm of executing neural networks either relies on hand-optimized libraries, traditional compilation heuristics, or very recently genetic algorithms and other stochastic methods. These methods suffer from frequent costly hardware measurements rendering them not only too time consuming but also suboptimal. As such, we devise a solution that can learn to quickly adapt to a previously unseen design space for code optimization, both accelerating the search and improving the output performance. This solution dubbed Chameleon leverages reinforcement learning whose solution takes fewer steps to converge, and develops an adaptive sampling algorithm that not only focuses on the costly samples (real hardware measurements) on representative points but also uses a domain-knowledge inspired logic to improve the samples itself. Experimentation with real hardware shows that Chameleon provides 4.45x speed up in optimization time over AutoTVM, while also improving inference time of the modern deep networks by 5.6%.
Divide and Conquer: Leveraging Intermediate Feature Representations for Quantized Training of Neural Networks
Jul 24, 2019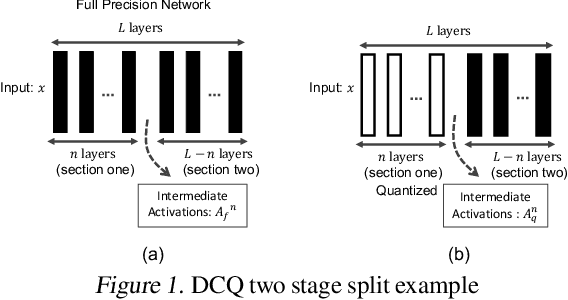
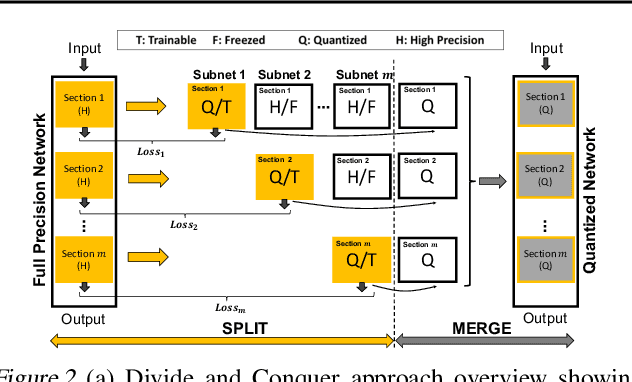
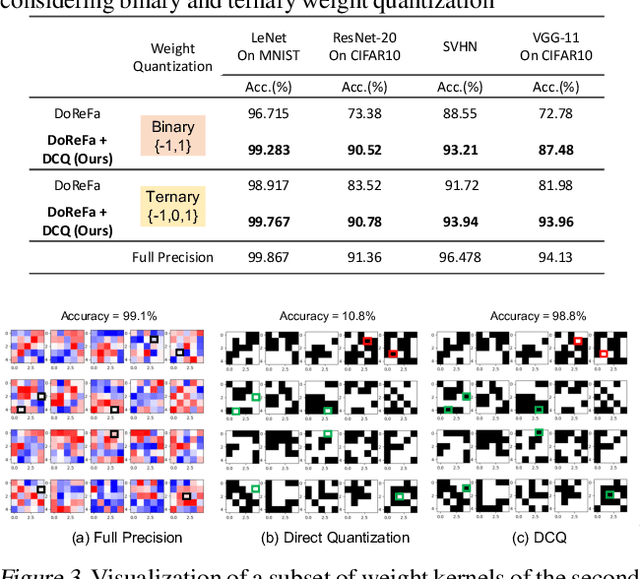
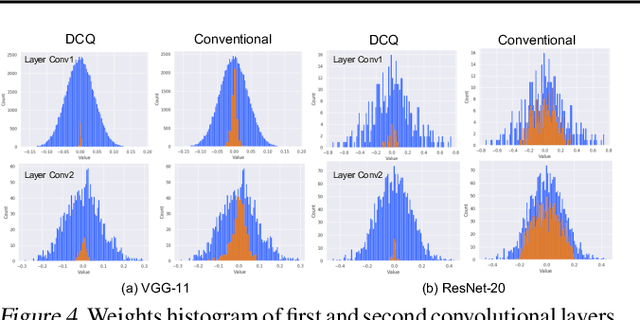
The deep layers of modern neural networks extract a rather rich set of features as an input propagates through the network. This paper sets out to harvest these rich intermediate representations for quantization with minimal accuracy loss while significantly reducing the memory footprint and compute intensity of the DNN. This paper utilizes knowledge distillation through teacher-student paradigm (Hinton et al., 2015) in a novel setting that exploits the feature extraction capability of DNNs for higher-accuracy quantization. As such, our algorithm logically divides a pretrained full-precision DNN to multiple sections, each of which exposes intermediate features to train a team of students independently in the quantized domain. This divide and conquer strategy, in fact, makes the training of each student section possible in isolation while all these independently trained sections are later stitched together to form the equivalent fully quantized network. Experiments on various DNNs (LeNet, ResNet-20, SVHN and VGG-11) show that, on average, this approach - called DCQ (Divide and Conquer Quantization) - achieves on average 9.7% accuracy improvement to a state-of-the-art quantized training technique, DoReFa (Zhou et al., 2016) for binary and ternary networks.
Reinforcement Learning and Adaptive Sampling for Optimized DNN Compilation
May 30, 2019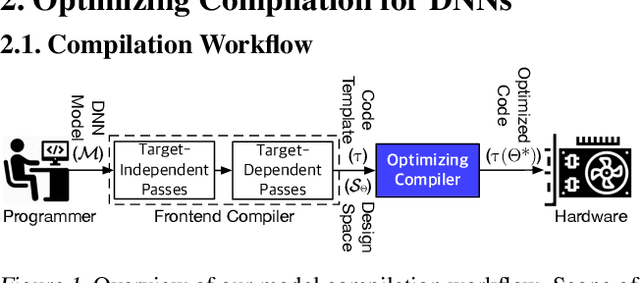
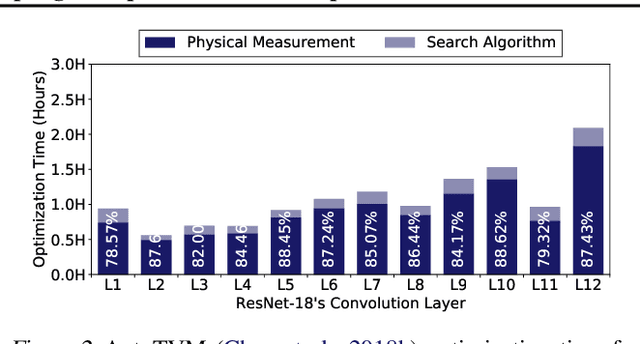
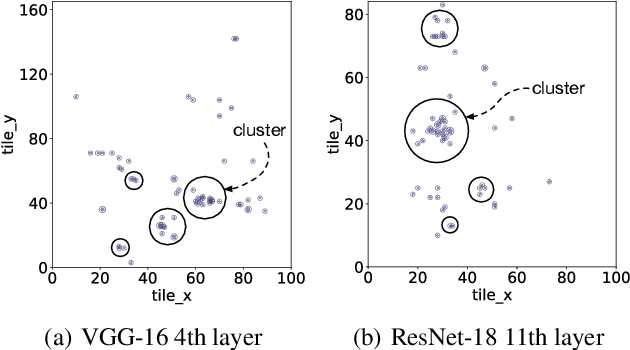
Achieving faster execution with shorter compilation time can enable further diversity and innovation in neural networks. However, the current paradigm of executing neural networks either relies on hand-optimized libraries, traditional compilation heuristics, or very recently, simulated annealing and genetic algorithms. Our work takes a unique approach by formulating compiler optimizations for neural networks as a reinforcement learning problem, whose solution takes fewer steps to converge. This solution, dubbed ReLeASE, comes with a sampling algorithm that leverages clustering to focus the costly samples (real hardware measurements) on representative points, subsuming an entire subspace. Our adaptive sampling not only reduces the number of samples, but also improves the quality of samples for better exploration in shorter time. As such, experimentation with real hardware shows that reinforcement learning with adaptive sampling provides 4.45x speed up in optimization time over AutoTVM, while also improving inference time of the modern deep networks by 5.6%. Further experiments also confirm that our adaptive sampling can even improve AutoTVM's simulated annealing by 4.00x.
SinReQ: Generalized Sinusoidal Regularization for Automatic Low-Bitwidth Deep Quantized Training
May 04, 2019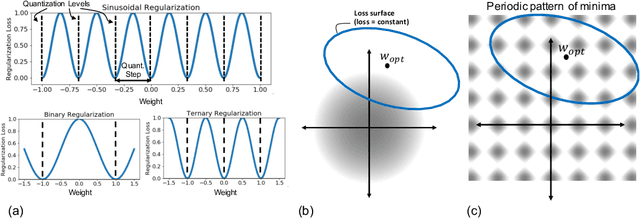
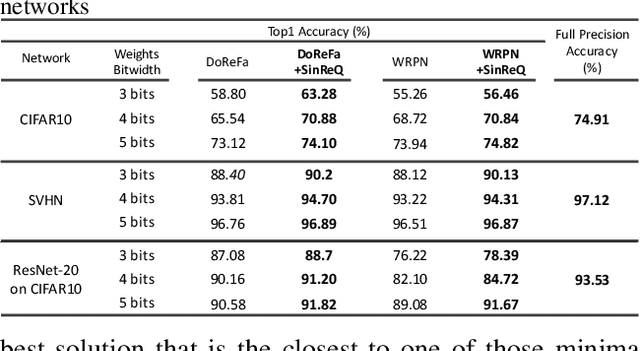
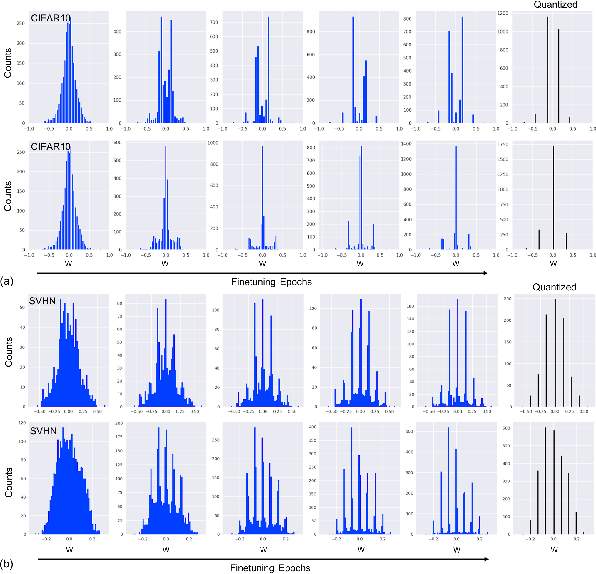
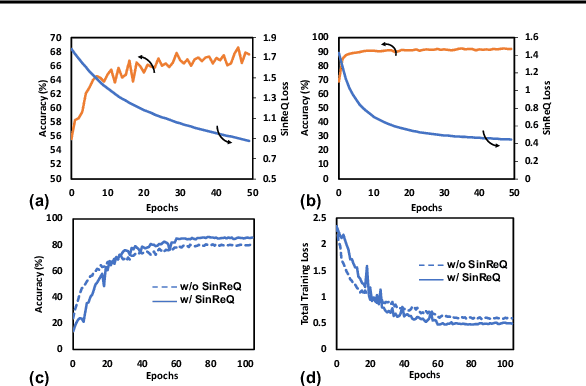
Quantization of neural networks offers significant promise in reducing their compute and storage cost. Albeit alluring, without domain experts to come up with special handcrafted optimization techniques or ad-hoc manipulation of the original network architecture, deep quantization (below 8 bits) results in unrecoverable accuracy gap between the quantized model and the full-precision counterpart. We propose a novel sinusoidal regularization, dubbed SinReQ, for low precision deep quantized training. The proposed method is aimed at automatically yielding semi-quantized weights at pre-defined target bitwidths during conventional training. The proposed regularization is realized by adding a periodic function (sinusoidal regularizer) to the original objective function. We exploit the inherent periodicity with a desired convexity profile in sinusoidal functions to automatically propel weights towards target quantization levels during conventional training. Our method combines generality by providing the flexibility for arbitrary-bit quantization, and customization by optimizing different layer-wise regularizers simultaneously. Preliminary results for experiments on CIFAR10, SVHN show that integrating SinReQ within the training algorithm achieves 2.82%, and 2.11% accuracy improvements to DoReFa (Zhou et al., 2016), and WRPN (Mishra et al., 2018) methods respectively.
ReLeQ: An Automatic Reinforcement Learning Approach for Deep Quantization of Neural Networks
Dec 10, 2018
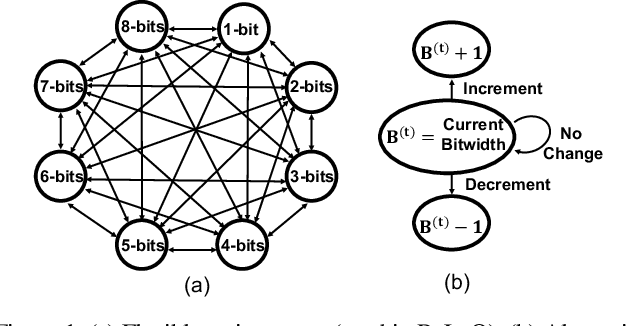
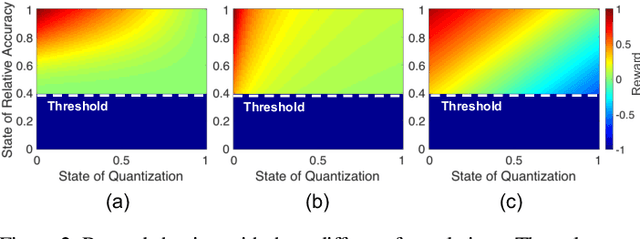
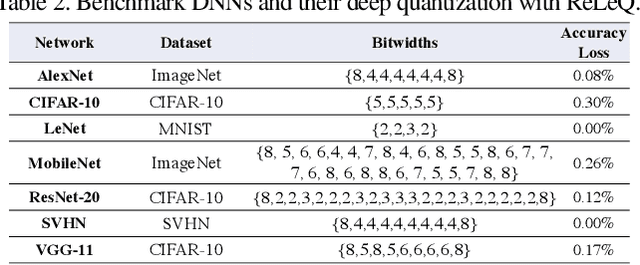
Despite numerous state-of-the-art applications of Deep Neural Networks (DNNs) in a wide range of real-world tasks, two major challenges hinder further advances in DNNs: hyperparameter optimization and constrained power resources, which is a significant concern in embedded devices. DNNs become increasingly difficult to train and deploy as they grow in size due to both computational intensity and the large memory footprint. Recent efforts show that quantizing weights of deep neural networks to lower bitwidths takes a significant step toward mitigating the mentioned issues, by reducing memory bandwidth and using limited computational resources which is important for deploying DNN models to devices with limited resources. This paper builds upon the algorithmic insight that the bitwidth of operations in DNNs can be reduced without compromising their classification accuracy. Deep quantization (quantizing bitwidths below eight) while maintaining accuracy, requires magnificent manual effort and hyper-parameter tuning as well as re-training. This paper tackles the aforementioned problems by designing an end to end framework, dubbed ReLeQ, to automate DNN quantization. We formulate DNN quantization as an optimization problem and use a state-of-the-art policy gradient based Reinforcement Learning (RL) algorithm, Proximal Policy Optimization (PPO) to efficiently explore the large design space of DNN quantization and solve the defined optimization problem. To show the effectiveness of ReLeQ, we evaluated it across several neural networks including MNIST, CIFAR10, SVHN. ReLeQ quantizes the weights of these networks to average bitwidths of 2.25, 5 and 4 respectively while maintaining the final accuracy loss below 0.3%.