 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivide and Conquer: Leveraging Intermediate Feature Representations for Quantized Training of Neural Networks
Paper and Code
Jul 24, 2019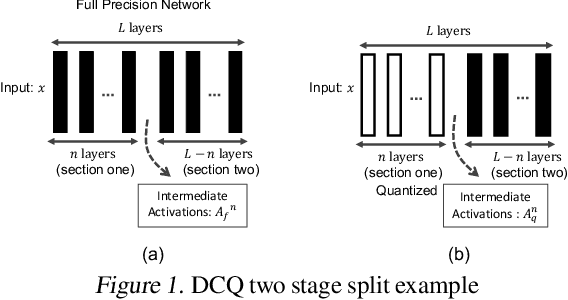
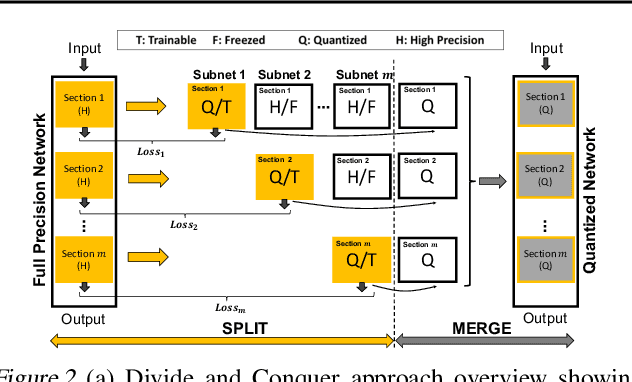
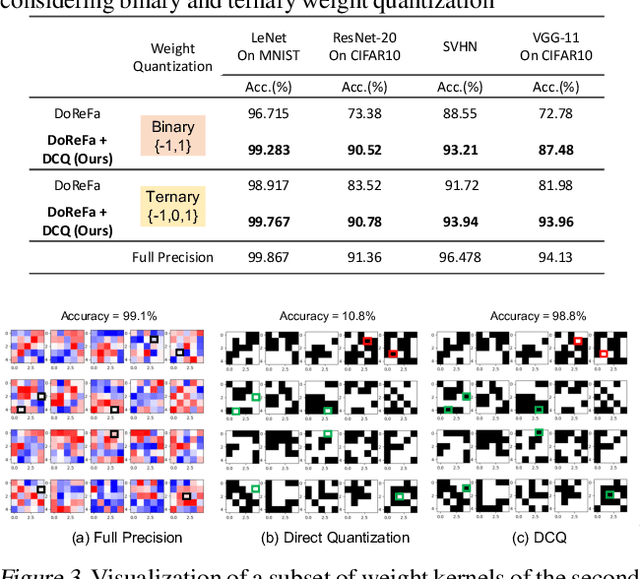
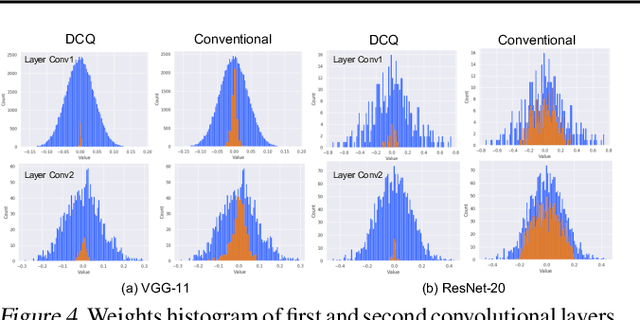
The deep layers of modern neural networks extract a rather rich set of features as an input propagates through the network. This paper sets out to harvest these rich intermediate representations for quantization with minimal accuracy loss while significantly reducing the memory footprint and compute intensity of the DNN. This paper utilizes knowledge distillation through teacher-student paradigm (Hinton et al., 2015) in a novel setting that exploits the feature extraction capability of DNNs for higher-accuracy quantization. As such, our algorithm logically divides a pretrained full-precision DNN to multiple sections, each of which exposes intermediate features to train a team of students independently in the quantized domain. This divide and conquer strategy, in fact, makes the training of each student section possible in isolation while all these independently trained sections are later stitched together to form the equivalent fully quantized network. Experiments on various DNNs (LeNet, ResNet-20, SVHN and VGG-11) show that, on average, this approach - called DCQ (Divide and Conquer Quantization) - achieves on average 9.7% accuracy improvement to a state-of-the-art quantized training technique, DoReFa (Zhou et al., 2016) for binary and ternary networks.