 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrdering Chaos: Memory-Aware Scheduling of Irregularly Wired Neural Networks for Edge Devices
Mar 04, 2020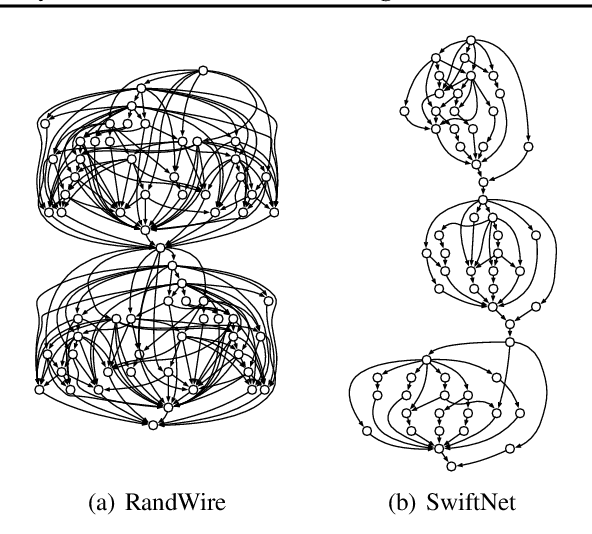
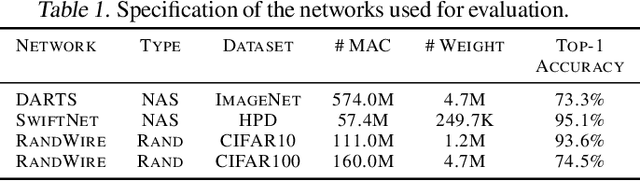
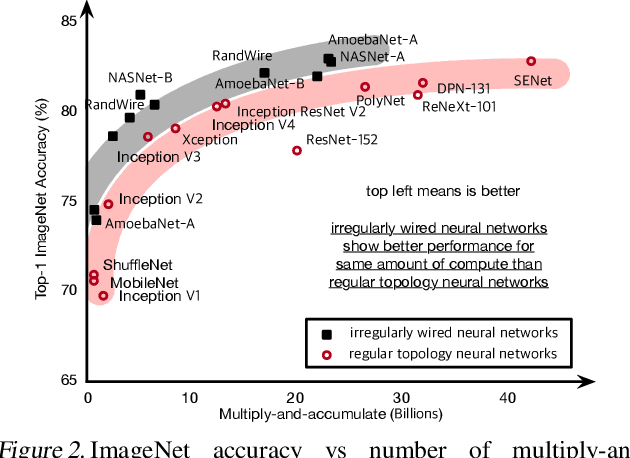
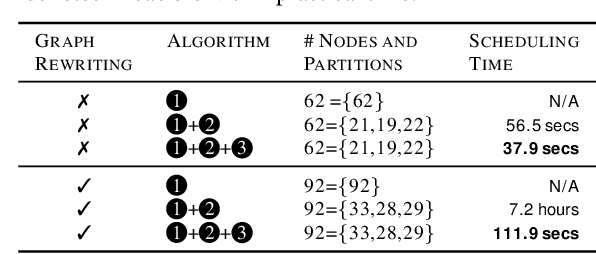
Recent advances demonstrate that irregularly wired neural networks from Neural Architecture Search (NAS) and Random Wiring can not only automate the design of deep neural networks but also emit models that outperform previous manual designs. These designs are especially effective while designing neural architectures under hard resource constraints (memory, MACs, . . . ) which highlights the importance of this class of designing neural networks. However, such a move creates complication in the previously streamlined pattern of execution. In fact one of the main challenges is that the order of such nodes in the neural network significantly effects the memory footprint of the intermediate activations. Current compilers do not schedule with regard to activation memory footprint that it significantly increases its peak compared to the optimum, rendering it not applicable for edge devices. To address this standing issue, we present a memory-aware compiler, dubbed SERENITY, that utilizes dynamic programming to find a sequence that finds a schedule with optimal memory footprint. Our solution also comprises of graph rewriting technique that allows further reduction beyond the optimum. As such, SERENITY achieves optimal peak memory, and the graph rewriting technique further improves this resulting in 1.68x improvement with dynamic programming-based scheduler and 1.86x with graph rewriting, against TensorFlow Lite with less than one minute overhead.
Chameleon: Adaptive Code Optimization for Expedited Deep Neural Network Compilation
Jan 23, 2020



Achieving faster execution with shorter compilation time can foster further diversity and innovation in neural networks. However, the current paradigm of executing neural networks either relies on hand-optimized libraries, traditional compilation heuristics, or very recently genetic algorithms and other stochastic methods. These methods suffer from frequent costly hardware measurements rendering them not only too time consuming but also suboptimal. As such, we devise a solution that can learn to quickly adapt to a previously unseen design space for code optimization, both accelerating the search and improving the output performance. This solution dubbed Chameleon leverages reinforcement learning whose solution takes fewer steps to converge, and develops an adaptive sampling algorithm that not only focuses on the costly samples (real hardware measurements) on representative points but also uses a domain-knowledge inspired logic to improve the samples itself. Experimentation with real hardware shows that Chameleon provides 4.45x speed up in optimization time over AutoTVM, while also improving inference time of the modern deep networks by 5.6%.
Reinforcement Learning and Adaptive Sampling for Optimized DNN Compilation
May 30, 2019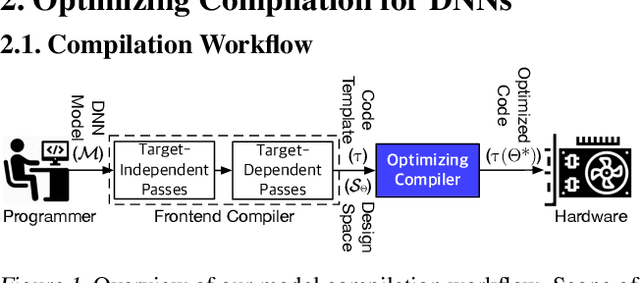
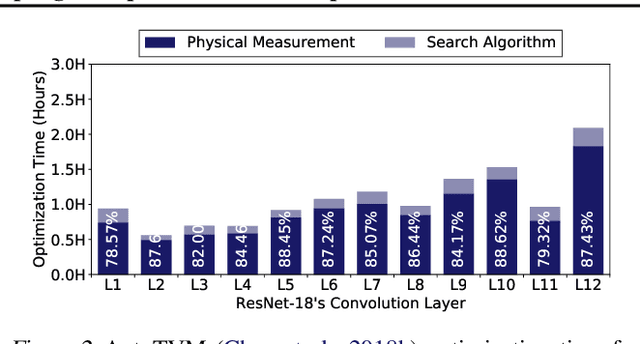
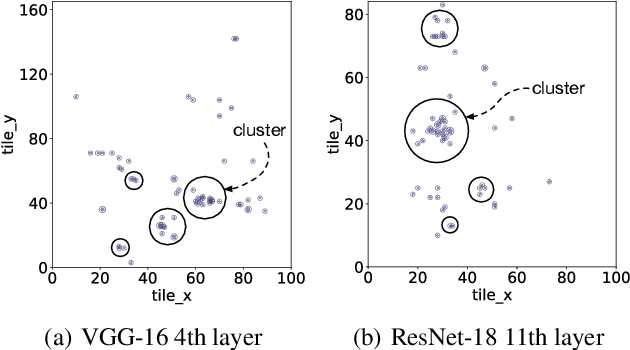
Achieving faster execution with shorter compilation time can enable further diversity and innovation in neural networks. However, the current paradigm of executing neural networks either relies on hand-optimized libraries, traditional compilation heuristics, or very recently, simulated annealing and genetic algorithms. Our work takes a unique approach by formulating compiler optimizations for neural networks as a reinforcement learning problem, whose solution takes fewer steps to converge. This solution, dubbed ReLeASE, comes with a sampling algorithm that leverages clustering to focus the costly samples (real hardware measurements) on representative points, subsuming an entire subspace. Our adaptive sampling not only reduces the number of samples, but also improves the quality of samples for better exploration in shorter time. As such, experimentation with real hardware shows that reinforcement learning with adaptive sampling provides 4.45x speed up in optimization time over AutoTVM, while also improving inference time of the modern deep networks by 5.6%. Further experiments also confirm that our adaptive sampling can even improve AutoTVM's simulated annealing by 4.00x.