 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciFlow: Empowering Lightweight Optical Flow Models with Self-Cleaning Iterations
Apr 11, 2024



Optical flow estimation is crucial to a variety of vision tasks. Despite substantial recent advancements, achieving real-time on-device optical flow estimation remains a complex challenge. First, an optical flow model must be sufficiently lightweight to meet computation and memory constraints to ensure real-time performance on devices. Second, the necessity for real-time on-device operation imposes constraints that weaken the model's capacity to adequately handle ambiguities in flow estimation, thereby intensifying the difficulty of preserving flow accuracy. This paper introduces two synergistic techniques, Self-Cleaning Iteration (SCI) and Regression Focal Loss (RFL), designed to enhance the capabilities of optical flow models, with a focus on addressing optical flow regression ambiguities. These techniques prove particularly effective in mitigating error propagation, a prevalent issue in optical flow models that employ iterative refinement. Notably, these techniques add negligible to zero overhead in model parameters and inference latency, thereby preserving real-time on-device efficiency. The effectiveness of our proposed SCI and RFL techniques, collectively referred to as SciFlow for brevity, is demonstrated across two distinct lightweight optical flow model architectures in our experiments. Remarkably, SciFlow enables substantial reduction in error metrics (EPE and Fl-all) over the baseline models by up to 6.3% and 10.5% for in-domain scenarios and by up to 6.2% and 13.5% for cross-domain scenarios on the Sintel and KITTI 2015 datasets, respectively.
OCAI: Improving Optical Flow Estimation by Occlusion and Consistency Aware Interpolation
Mar 26, 2024



The scarcity of ground-truth labels poses one major challenge in developing optical flow estimation models that are both generalizable and robust. While current methods rely on data augmentation, they have yet to fully exploit the rich information available in labeled video sequences. We propose OCAI, a method that supports robust frame interpolation by generating intermediate video frames alongside optical flows in between. Utilizing a forward warping approach, OCAI employs occlusion awareness to resolve ambiguities in pixel values and fills in missing values by leveraging the forward-backward consistency of optical flows. Additionally, we introduce a teacher-student style semi-supervised learning method on top of the interpolated frames. Using a pair of unlabeled frames and the teacher model's predicted optical flow, we generate interpolated frames and flows to train a student model. The teacher's weights are maintained using Exponential Moving Averaging of the student. Our evaluations demonstrate perceptually superior interpolation quality and enhanced optical flow accuracy on established benchmarks such as Sintel and KITTI.
DIFT: Dynamic Iterative Field Transforms for Memory Efficient Optical Flow
Jun 09, 2023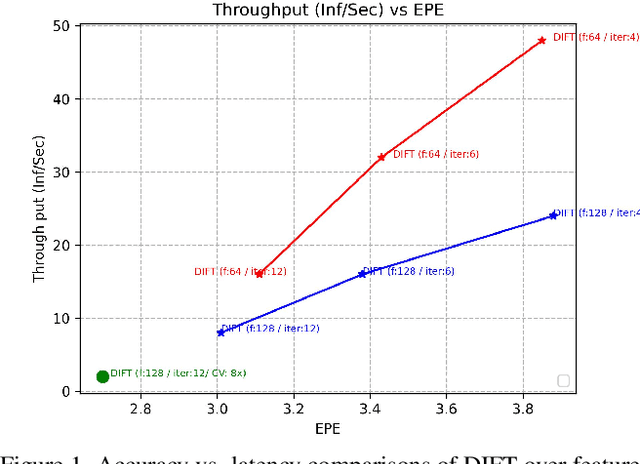

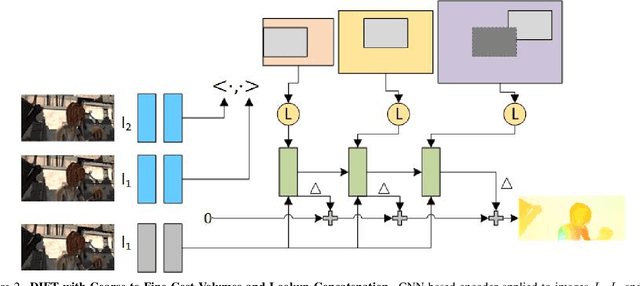

Recent advancements in neural network-based optical flow estimation often come with prohibitively high computational and memory requirements, presenting challenges in their model adaptation for mobile and low-power use cases. In this paper, we introduce a lightweight low-latency and memory-efficient model, Dynamic Iterative Field Transforms (DIFT), for optical flow estimation feasible for edge applications such as mobile, XR, micro UAVs, robotics and cameras. DIFT follows an iterative refinement framework leveraging variable resolution of cost volumes for correspondence estimation. We propose a memory efficient solution for cost volume processing to reduce peak memory. Also, we present a novel dynamic coarse-to-fine cost volume processing during various stages of refinement to avoid multiple levels of cost volumes. We demonstrate first real-time cost-volume based optical flow DL architecture on Snapdragon 8 Gen 1 HTP efficient mobile AI accelerator with 32 inf/sec and 5.89 EPE (endpoint error) on KITTI with manageable accuracy-performance tradeoffs.
Guided Speech Enhancement Network
Mar 13, 2023High quality speech capture has been widely studied for both voice communication and human computer interface reasons. To improve the capture performance, we can often find multi-microphone speech enhancement techniques deployed on various devices. Multi-microphone speech enhancement problem is often decomposed into two decoupled steps: a beamformer that provides spatial filtering and a single-channel speech enhancement model that cleans up the beamformer output. In this work, we propose a speech enhancement solution that takes both the raw microphone and beamformer outputs as the input for an ML model. We devise a simple yet effective training scheme that allows the model to learn from the cues of the beamformer by contrasting the two inputs and greatly boost its capability in spatial rejection, while conducting the general tasks of denoising and dereverberation. The proposed solution takes advantage of classical spatial filtering algorithms instead of competing with them. By design, the beamformer module then could be selected separately and does not require a large amount of data to be optimized for a given form factor, and the network model can be considered as a standalone module which is highly transferable independently from the microphone array. We name the ML module in our solution as GSENet, short for Guided Speech Enhancement Network. We demonstrate its effectiveness on real world data collected on multi-microphone devices in terms of the suppression of noise and interfering speech.
Efficient Heterogeneous Video Segmentation at the Edge
Aug 24, 2022
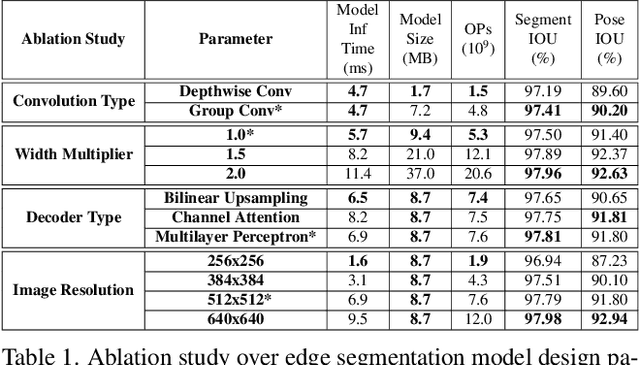
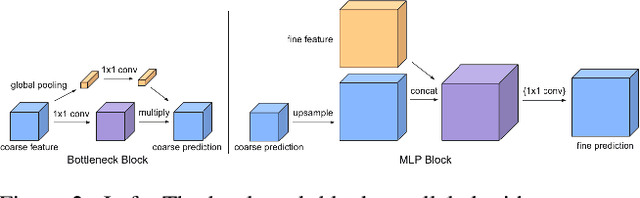
We introduce an efficient video segmentation system for resource-limited edge devices leveraging heterogeneous compute. Specifically, we design network models by searching across multiple dimensions of specifications for the neural architectures and operations on top of already light-weight backbones, targeting commercially available edge inference engines. We further analyze and optimize the heterogeneous data flows in our systems across the CPU, the GPU and the NPU. Our approach has empirically factored well into our real-time AR system, enabling remarkably higher accuracy with quadrupled effective resolutions, yet at much shorter end-to-end latency, much higher frame rate, and even lower power consumption on edge platforms.
Imposing Consistency for Optical Flow Estimation
Apr 14, 2022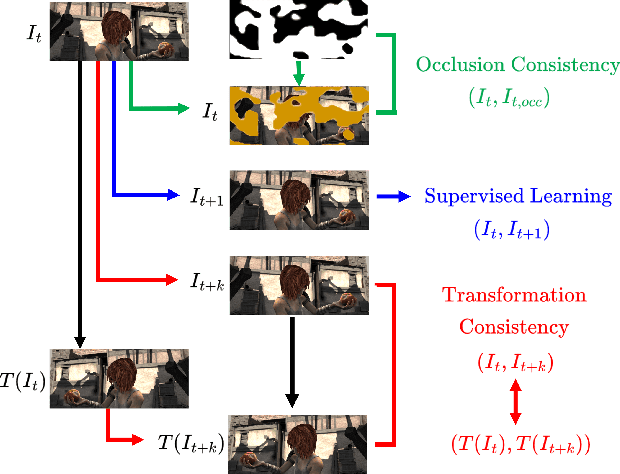
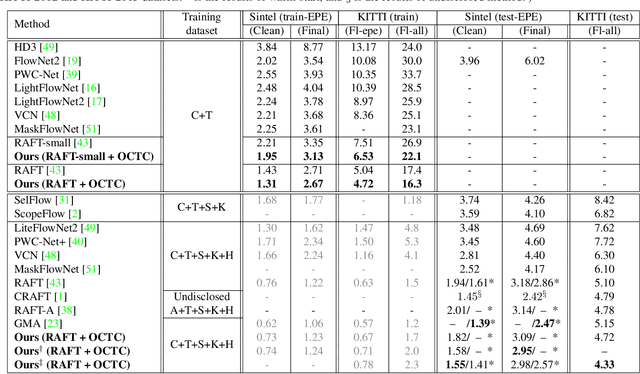

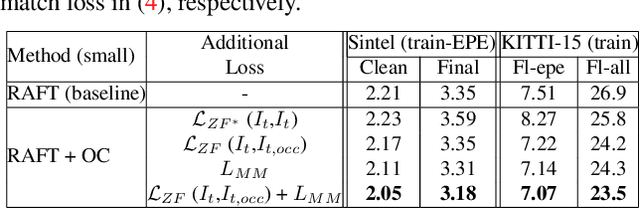
Imposing consistency through proxy tasks has been shown to enhance data-driven learning and enable self-supervision in various tasks. This paper introduces novel and effective consistency strategies for optical flow estimation, a problem where labels from real-world data are very challenging to derive. More specifically, we propose occlusion consistency and zero forcing in the forms of self-supervised learning and transformation consistency in the form of semi-supervised learning. We apply these consistency techniques in a way that the network model learns to describe pixel-level motions better while requiring no additional annotations. We demonstrate that our consistency strategies applied to a strong baseline network model using the original datasets and labels provide further improvements, attaining the state-of-the-art results on the KITTI-2015 scene flow benchmark in the non-stereo category. Our method achieves the best foreground accuracy (4.33% in Fl-all) over both the stereo and non-stereo categories, even though using only monocular image inputs.
Ordering Chaos: Memory-Aware Scheduling of Irregularly Wired Neural Networks for Edge Devices
Mar 04, 2020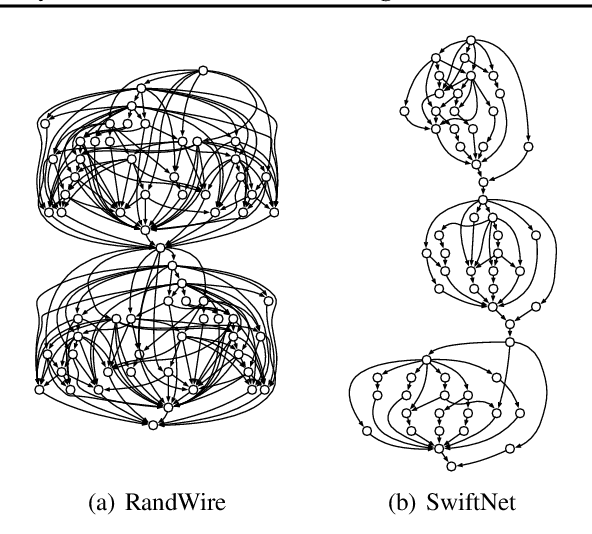
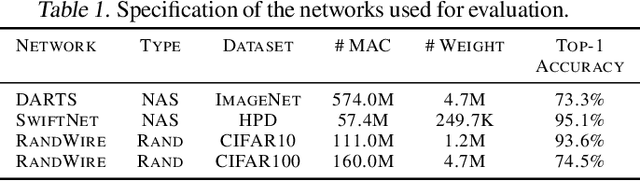
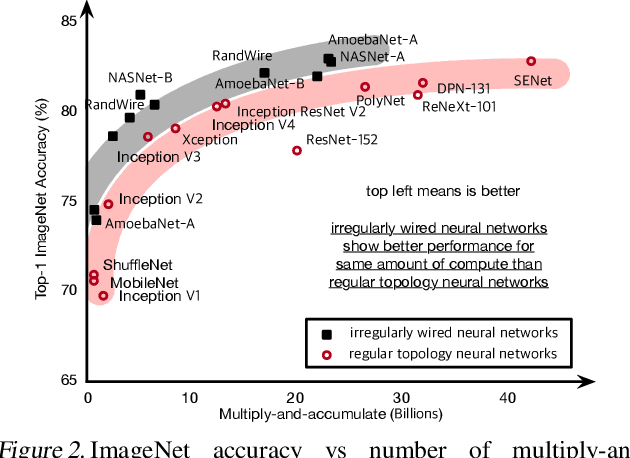
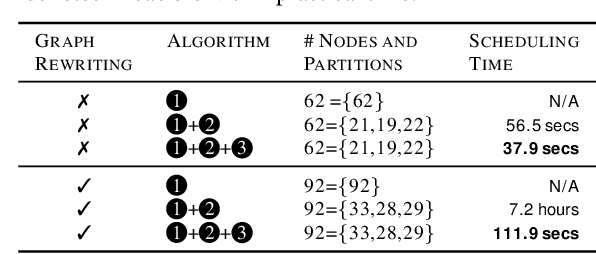
Recent advances demonstrate that irregularly wired neural networks from Neural Architecture Search (NAS) and Random Wiring can not only automate the design of deep neural networks but also emit models that outperform previous manual designs. These designs are especially effective while designing neural architectures under hard resource constraints (memory, MACs, . . . ) which highlights the importance of this class of designing neural networks. However, such a move creates complication in the previously streamlined pattern of execution. In fact one of the main challenges is that the order of such nodes in the neural network significantly effects the memory footprint of the intermediate activations. Current compilers do not schedule with regard to activation memory footprint that it significantly increases its peak compared to the optimum, rendering it not applicable for edge devices. To address this standing issue, we present a memory-aware compiler, dubbed SERENITY, that utilizes dynamic programming to find a sequence that finds a schedule with optimal memory footprint. Our solution also comprises of graph rewriting technique that allows further reduction beyond the optimum. As such, SERENITY achieves optimal peak memory, and the graph rewriting technique further improves this resulting in 1.68x improvement with dynamic programming-based scheduler and 1.86x with graph rewriting, against TensorFlow Lite with less than one minute overhead.