 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Parallel Monte Carlo Tree Search for Efficient Test-time Compute Scaling
Apr 01, 2026Monte Carlo Tree Search (MCTS) is an effective test-time compute scaling (TTCS) method for improving the reasoning performance of large language models, but its highly variable execution time leads to severe long-tail latency in practice. Existing optimizations such as positive early exit, reduce latency in favorable cases but are less effective when search continues without meaningful progress. We introduce {\it negative early exit}, which prunes unproductive MCTS trajectories, and an {\it adaptive boosting mechanism} that reallocates reclaimed computation to reduce resource contention among concurrent searches. Integrated into vLLM, these techniques substantially reduce p99 end-to-end latency while improving throughput and maintaining reasoning accuracy.
Scaling On-Device GPU Inference for Large Generative Models
May 01, 2025


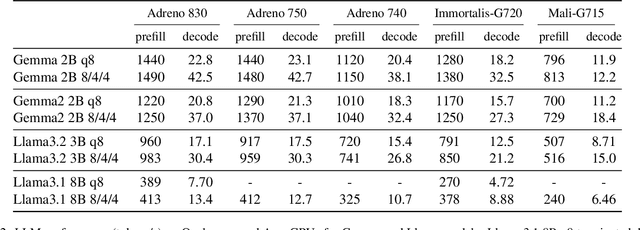
Driven by the advancements in generative AI, large machine learning models have revolutionized domains such as image processing, audio synthesis, and speech recognition. While server-based deployments remain the locus of peak performance, the imperative for on-device inference, necessitated by privacy and efficiency considerations, persists. Recognizing GPUs as the on-device ML accelerator with the widest reach, we present ML Drift--an optimized framework that extends the capabilities of state-of-the-art GPU-accelerated inference engines. ML Drift enables on-device execution of generative AI workloads which contain 10 to 100x more parameters than existing on-device generative AI models. ML Drift addresses intricate engineering challenges associated with cross-GPU API development, and ensures broad compatibility across mobile and desktop/laptop platforms, thereby facilitating the deployment of significantly more complex models on resource-constrained devices. Our GPU-accelerated ML/AI inference engine achieves an order-of-magnitude performance improvement relative to existing open-source GPU inference engines.
Study of Subjective and Objective Quality in Super-Resolution Enhanced Broadcast Images on a Novel SR-IQA Dataset
Sep 26, 2024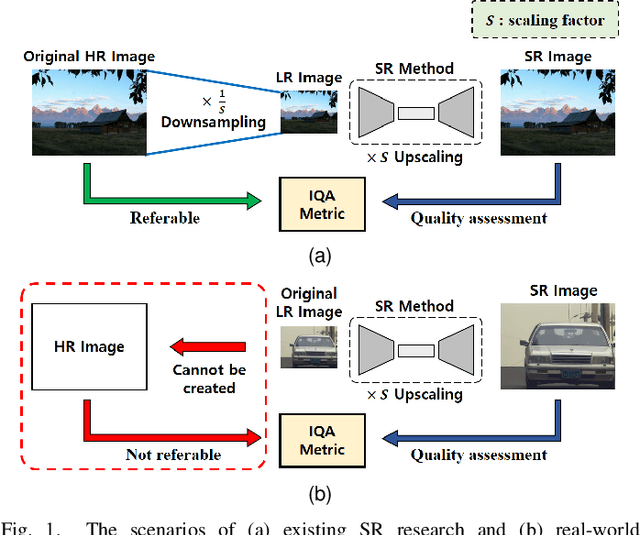
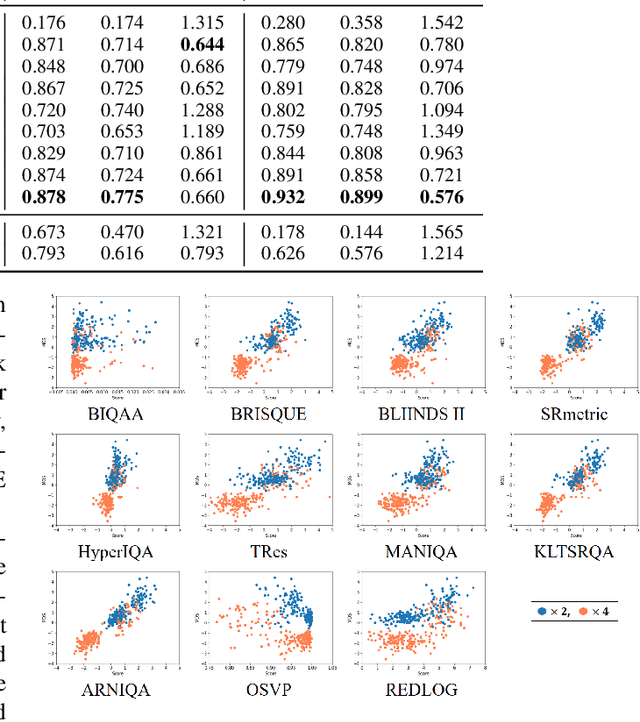
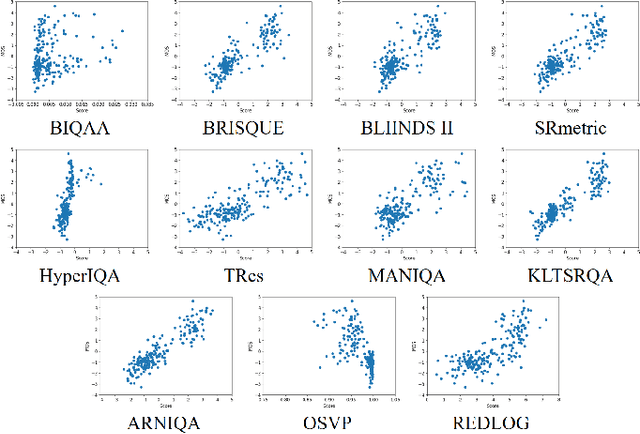
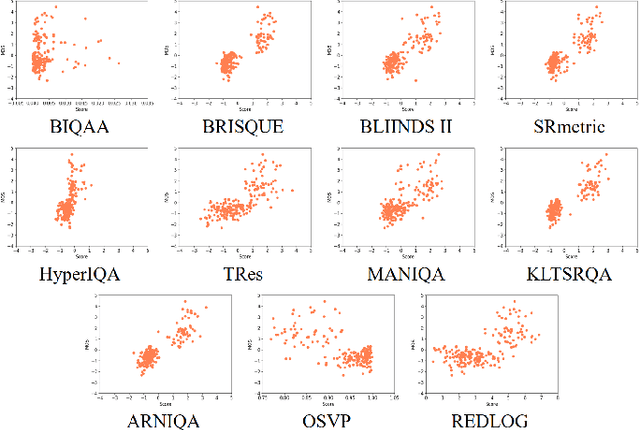
To display low-quality broadcast content on high-resolution screens in full-screen format, the application of Super-Resolution (SR), a key consumer technology, is essential. Recently, SR methods have been developed that not only increase resolution while preserving the original image information but also enhance the perceived quality. However, evaluating the quality of SR images generated from low-quality sources, such as SR-enhanced broadcast content, is challenging due to the need to consider both distortions and improvements. Additionally, assessing SR image quality without original high-quality sources presents another significant challenge. Unfortunately, there has been a dearth of research specifically addressing the Image Quality Assessment (IQA) of SR images under these conditions. In this work, we introduce a new IQA dataset for SR broadcast images in both 2K and 4K resolutions. We conducted a subjective quality evaluation to obtain the Mean Opinion Score (MOS) for these SR images and performed a comprehensive human study to identify the key factors influencing the perceived quality. Finally, we evaluated the performance of existing IQA metrics on our dataset. This study reveals the limitations of current metrics, highlighting the need for a more robust IQA metric that better correlates with the perceived quality of SR images.
Speed Is All You Need: On-Device Acceleration of Large Diffusion Models via GPU-Aware Optimizations
Apr 21, 2023



The rapid development and application of foundation models have revolutionized the field of artificial intelligence. Large diffusion models have gained significant attention for their ability to generate photorealistic images and support various tasks. On-device deployment of these models provides benefits such as lower server costs, offline functionality, and improved user privacy. However, common large diffusion models have over 1 billion parameters and pose challenges due to restricted computational and memory resources on devices. We present a series of implementation optimizations for large diffusion models that achieve the fastest reported inference latency to-date (under 12 seconds for Stable Diffusion 1.4 without int8 quantization on Samsung S23 Ultra for a 512x512 image with 20 iterations) on GPU-equipped mobile devices. These enhancements broaden the applicability of generative AI and improve the overall user experience across a wide range of devices.
Efficient Heterogeneous Video Segmentation at the Edge
Aug 24, 2022
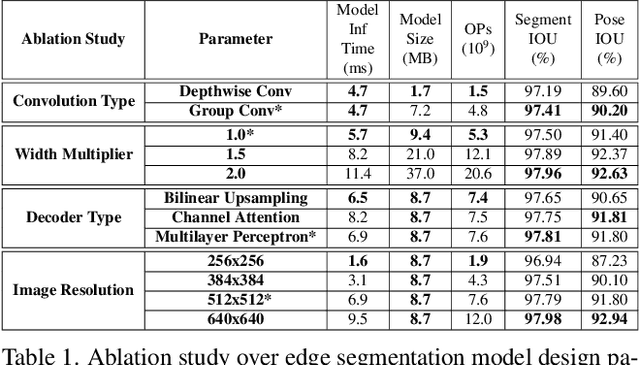
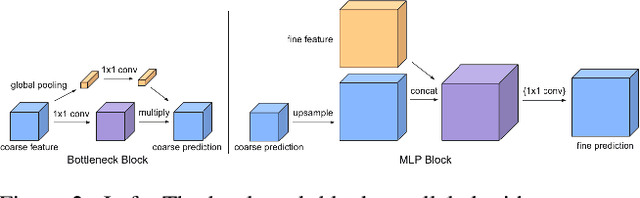
We introduce an efficient video segmentation system for resource-limited edge devices leveraging heterogeneous compute. Specifically, we design network models by searching across multiple dimensions of specifications for the neural architectures and operations on top of already light-weight backbones, targeting commercially available edge inference engines. We further analyze and optimize the heterogeneous data flows in our systems across the CPU, the GPU and the NPU. Our approach has empirically factored well into our real-time AR system, enabling remarkably higher accuracy with quadrupled effective resolutions, yet at much shorter end-to-end latency, much higher frame rate, and even lower power consumption on edge platforms.
Deep learning-based framework for cardiac function assessment in embryonic zebrafish from heart beating videos
Feb 24, 2021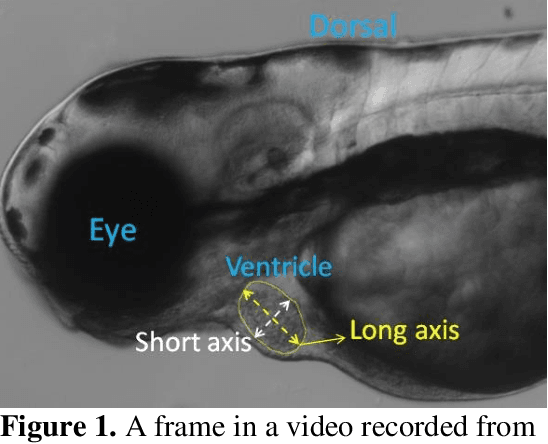
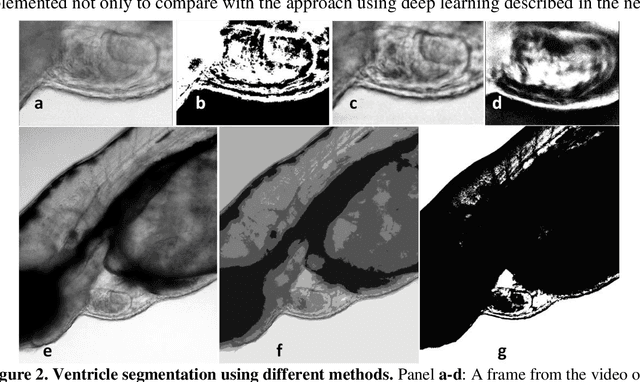
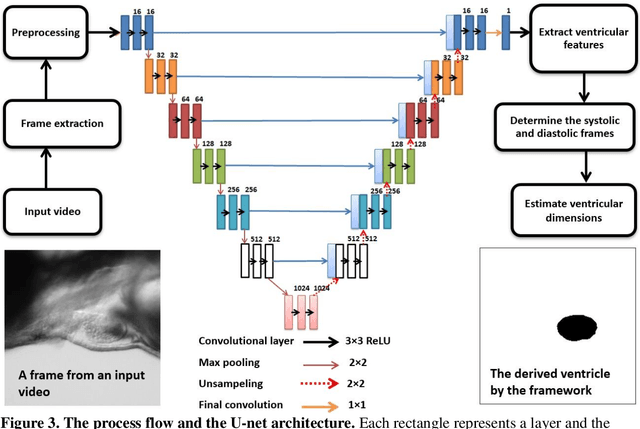
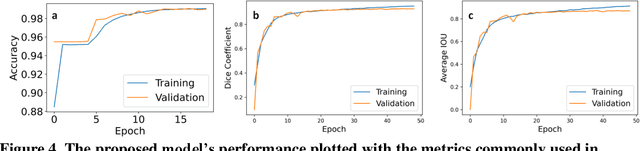
Zebrafish is a powerful and widely-used model system for a host of biological investigations including cardiovascular studies and genetic screening. Zebrafish are readily assessable during developmental stages; however, the current methods for quantification and monitoring of cardiac functions mostly involve tedious manual work and inconsistent estimations. In this paper, we developed and validated a Zebrafish Automatic Cardiovascular Assessment Framework (ZACAF) based on a U-net deep learning model for automated assessment of cardiovascular indices, such as ejection fraction (EF) and fractional shortening (FS) from microscopic videos of wildtype and cardiomyopathy mutant zebrafish embryos. Our approach yielded favorable performance with accuracy above 90% compared with manual processing. We used only black and white regular microscopic recordings with frame rates of 5-20 frames per second (fps); thus, the framework could be widely applicable with any laboratory resources and infrastructure. Most importantly, the automatic feature holds promise to enable efficient, consistent and reliable processing and analysis capacity for large amounts of videos, which can be generated by diverse collaborating teams.
Efficient Memory Management for Deep Neural Net Inference
Feb 16, 2020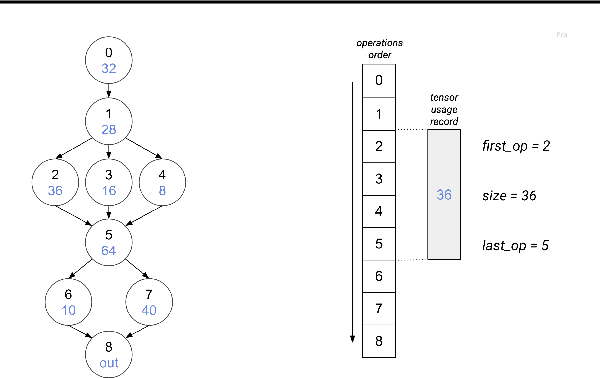
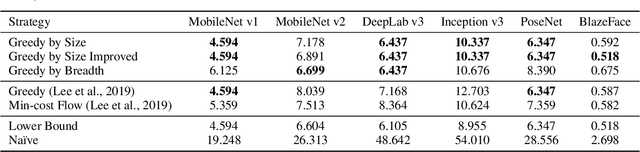
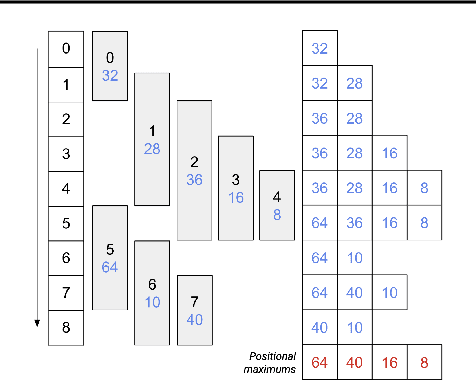
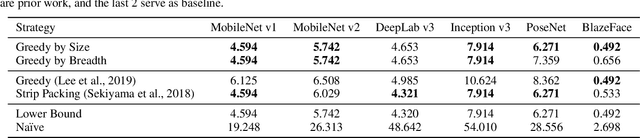
While deep neural net inference was considered a task for servers only, latest advances in technology allow the task of inference to be moved to mobile and embedded devices, desired for various reasons ranging from latency to privacy. These devices are not only limited by their compute power and battery, but also by their inferior physical memory and cache, and thus, an efficient memory manager becomes a crucial component for deep neural net inference at the edge. We explore various strategies to smartly share memory buffers among intermediate tensors in deep neural nets. Employing these can result in up to 11% smaller memory footprint than the state of the art.
Unconstrained Road Marking Recognition with Generative Adversarial Networks
Oct 10, 2019
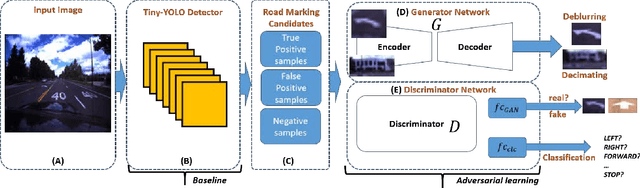
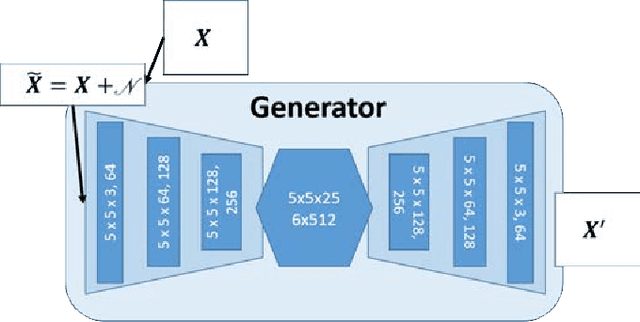
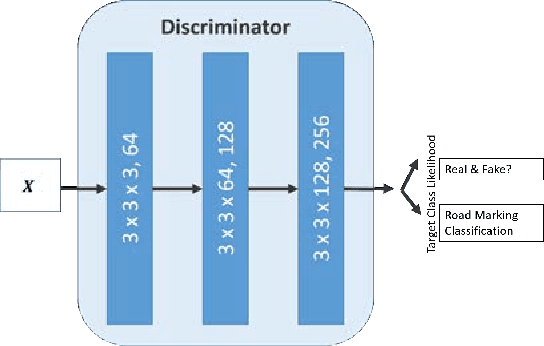
Recent road marking recognition has achieved great success in the past few years along with the rapid development of deep learning. Although considerable advances have been made, they are often over-dependent on unrepresentative datasets and constrained conditions. In this paper, to overcome these drawbacks, we propose an alternative method that achieves higher accuracy and generates high-quality samples as data augmentation. With the following two major contributions: 1) The proposed deblurring network can successfully recover a clean road marking from a blurred one by adopting generative adversarial networks (GAN). 2) The proposed data augmentation method, based on mutual information, can preserve and learn semantic context from the given dataset. We construct and train a class-conditional GAN to increase the size of training set, which makes it suitable to recognize target. The experimental results have shown that our proposed framework generates deblurred clean samples from blurry ones, and outperforms other methods even with unconstrained road marking datasets.
SNIDER: Single Noisy Image Denoising and Rectification for Improving License Plate Recognition
Oct 09, 2019
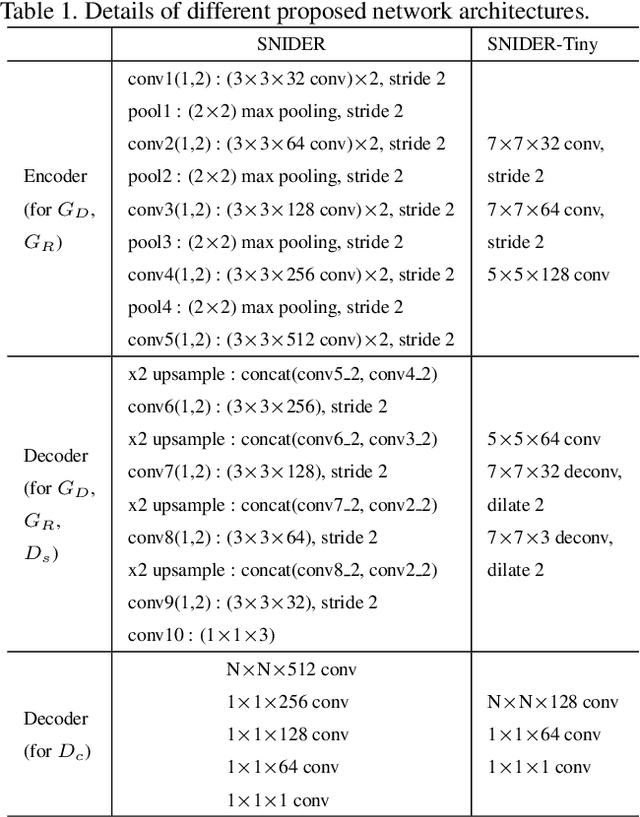
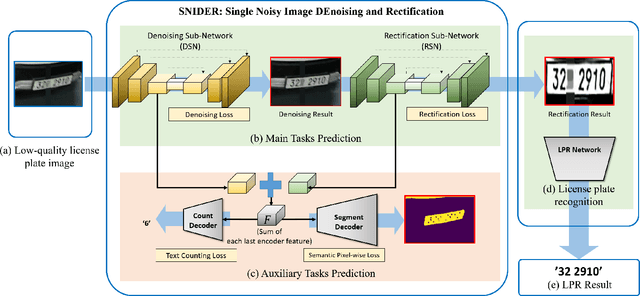
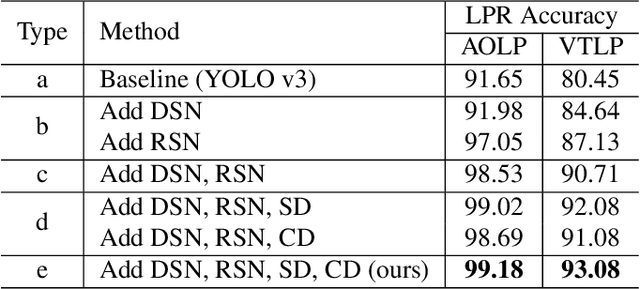
In this paper, we present an algorithm for real-world license plate recognition (LPR) from a low-quality image. Our method is built upon a framework that includes denoising and rectification, and each task is conducted by Convolutional Neural Networks. Existing denoising and rectification have been treated separately as a single network in previous research. In contrast to the previous work, we here propose an end-to-end trainable network for image recovery, Single Noisy Image DEnoising and Rectification (SNIDER), which focuses on solving both the problems jointly. It overcomes those obstacles by designing a novel network to address the denoising and rectification jointly. Moreover, we propose a way to leverage optimization with the auxiliary tasks for multi-task fitting and novel training losses. Extensive experiments on two challenging LPR datasets demonstrate the effectiveness of our proposed method in recovering the high-quality license plate image from the low-quality one and show that the the proposed method outperforms other state-of-the-art methods.
On-Device Neural Net Inference with Mobile GPUs
Jul 03, 2019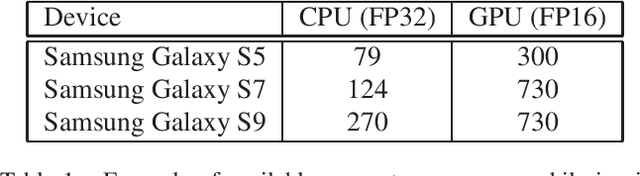
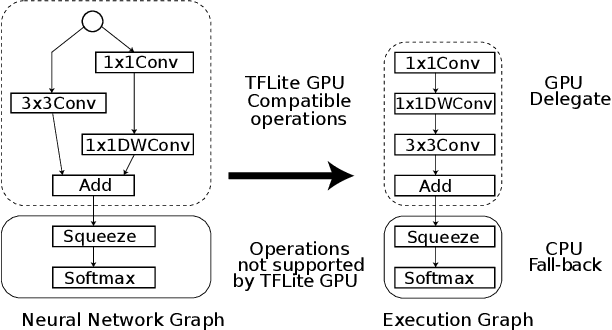
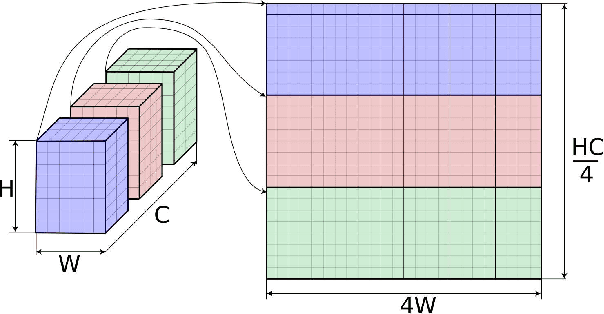

On-device inference of machine learning models for mobile phones is desirable due to its lower latency and increased privacy. Running such a compute-intensive task solely on the mobile CPU, however, can be difficult due to limited computing power, thermal constraints, and energy consumption. App developers and researchers have begun exploiting hardware accelerators to overcome these challenges. Recently, device manufacturers are adding neural processing units into high-end phones for on-device inference, but these account for only a small fraction of hand-held devices. In this paper, we present how we leverage the mobile GPU, a ubiquitous hardware accelerator on virtually every phone, to run inference of deep neural networks in real-time for both Android and iOS devices. By describing our architecture, we also discuss how to design networks that are mobile GPU-friendly. Our state-of-the-art mobile GPU inference engine is integrated into the open-source project TensorFlow Lite and publicly available at https://tensorflow.org/lite.