 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly as Non-Conformity via Training-Free Graph Laplacian Energy Minimization
May 27, 2026Detecting subtle visual anomalies in images remains challenging, particularly when only normal samples are available a priori. Such unsupervised anomaly detection is typically solved by measuring feature similarity of a query patch to a memory of normal patches. However, similarity alone does not reveal how strongly a query patch violates the structure of the normal feature manifold. We propose a training-free Laplacian graph energy optimization formulation, named ANoCo that scores Anomaly by the cost of Non-Conformity of a query patch to align with a fixed normal manifold. For each query patch, we construct a bipartite query to normal graph weighted by cosine affinity, explicitly removing query-query and normal-normal edges to prevent evidence dilution. We formulate anomaly scoring as a convex Laplacian energy with anchored normal nodes, and solve in closed form. In particular, we do not use the optimized features themselves-the anomaly score is the magnitude of the update required to satisfy normality constraints, reframing the graph Laplacian as a non-conformity operator rather than a smoothing prior. The proposed method introduces no learnable parameters, message passing, or sampling, and has complexity comparable to a single linear solve. Across standard benchmarks, it delivers strong image-level AUROC, stable localization maps, and improved robustness over prior methods, demonstrating the effectiveness of using optimization-induced feature drift as anomaly measure.
Unlocking Robust Semantic Segmentation Performance via Label-only Elastic Deformations against Implicit Label Noise
Aug 14, 2025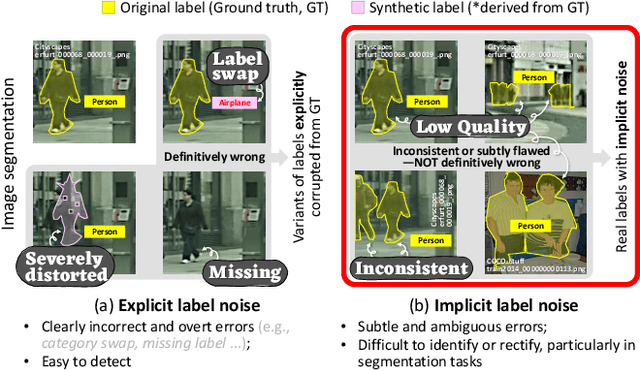
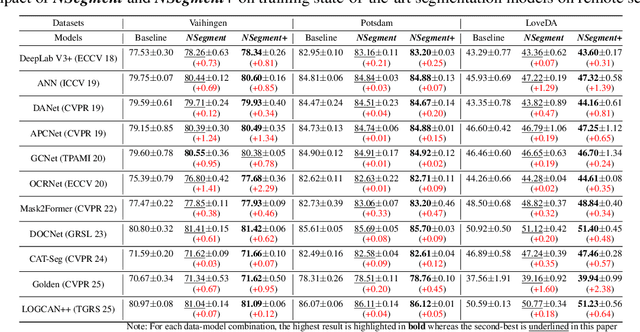


While previous studies on image segmentation focus on handling severe (or explicit) label noise, real-world datasets also exhibit subtle (or implicit) label imperfections. These arise from inherent challenges, such as ambiguous object boundaries and annotator variability. Although not explicitly present, such mild and latent noise can still impair model performance. Typical data augmentation methods, which apply identical transformations to the image and its label, risk amplifying these subtle imperfections and limiting the model's generalization capacity. In this paper, we introduce NSegment+, a novel augmentation framework that decouples image and label transformations to address such realistic noise for semantic segmentation. By introducing controlled elastic deformations only to segmentation labels while preserving the original images, our method encourages models to focus on learning robust representations of object structures despite minor label inconsistencies. Extensive experiments demonstrate that NSegment+ consistently improves performance, achieving mIoU gains of up to +2.29, +2.38, +1.75, and +3.39 in average on Vaihingen, LoveDA, Cityscapes, and PASCAL VOC, respectively-even without bells and whistles, highlighting the importance of addressing implicit label noise. These gains can be further amplified when combined with other training tricks, including CutMix and Label Smoothing.
Light Robust Monocular Depth Estimation For Outdoor Environment Via Monochrome And Color Camera Fusion
Feb 24, 2022

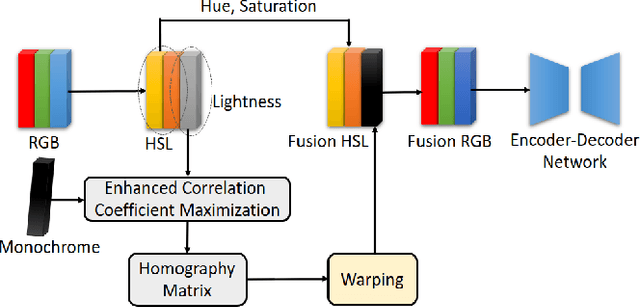
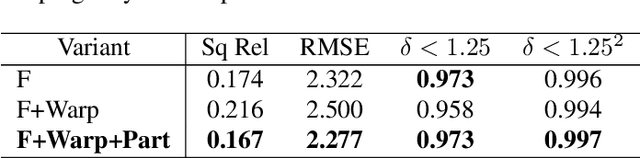
Depth estimation plays a important role in SLAM, odometry, and autonomous driving. Especially, monocular depth estimation is profitable technology because of its low cost, memory, and computation. However, it is not a sufficiently predicting depth map due to a camera often failing to get a clean image because of light conditions. To solve this problem, various sensor fusion method has been proposed. Even though it is a powerful method, sensor fusion requires expensive sensors, additional memory, and high computational performance. In this paper, we present color image and monochrome image pixel-level fusion and stereo matching with partially enhanced correlation coefficient maximization. Our methods not only outperform the state-of-the-art works across all metrics but also efficient in terms of cost, memory, and computation. We also validate the effectiveness of our design with an ablation study.
Task-Driven Deep Image Enhancement Network for Autonomous Driving in Bad Weather
Oct 14, 2021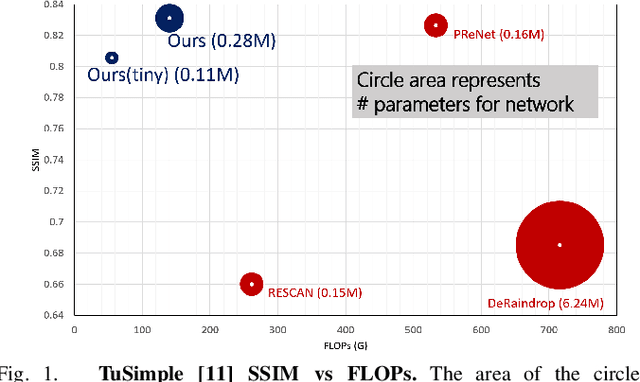
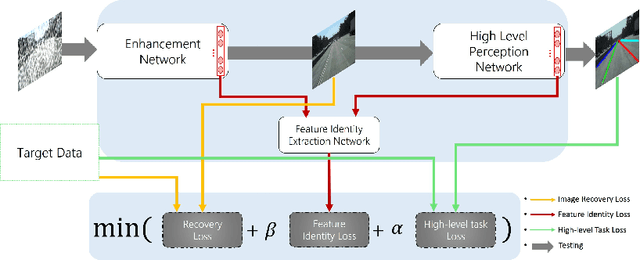
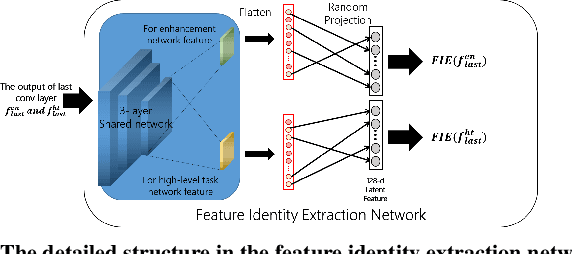

Visual perception in autonomous driving is a crucial part of a vehicle to navigate safely and sustainably in different traffic conditions. However, in bad weather such as heavy rain and haze, the performance of visual perception is greatly affected by several degrading effects. Recently, deep learning-based perception methods have addressed multiple degrading effects to reflect real-world bad weather cases but have shown limited success due to 1) high computational costs for deployment on mobile devices and 2) poor relevance between image enhancement and visual perception in terms of the model ability. To solve these issues, we propose a task-driven image enhancement network connected to the high-level vision task, which takes in an image corrupted by bad weather as input. Specifically, we introduce a novel low memory network to reduce most of the layer connections of dense blocks for less memory and computational cost while maintaining high performance. We also introduce a new task-driven training strategy to robustly guide the high-level task model suitable for both high-quality restoration of images and highly accurate perception. Experiment results demonstrate that the proposed method improves the performance among lane and 2D object detection, and depth estimation largely under adverse weather in terms of both low memory and accuracy.
Imbalanced Image Classification with Complement Cross Entropy
Sep 04, 2020

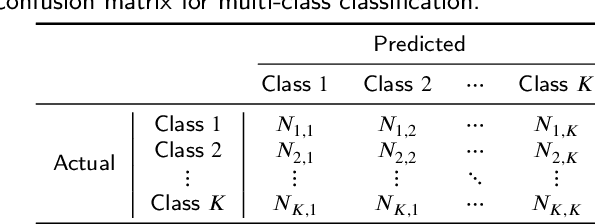
Recently, deep learning models have achieved great success in computer vision applications, relying on large-scale class-balanced datasets. However, imbalanced class distributions still limit the wide applicability of these models due to degradation in performance. To solve this problem, we focus on the study of cross entropy: it mostly ignores output scores on wrong classes. In this work, we discover that neutralizing predicted probabilities on incorrect classes helps improve accuracy of prediction for imbalanced image classification. This paper proposes a simple but effective loss named complement cross entropy (CCE) based on this finding. Our loss makes the ground truth class overwhelm the other classes in terms of softmax probability, by neutralizing probabilities of incorrect classes, without additional training procedures. Along with it, this loss facilitates the models to learn key information especially from samples on minority classes. It ensures more accurate and robust classification results for imbalanced class distributions. Extensive experiments on imbalanced datasets demonstrate the effectiveness of our method compared to other state-of-the-art methods.
Context-Aware Multi-Task Learning for Traffic Scene Recognition in Autonomous Vehicles
Apr 03, 2020
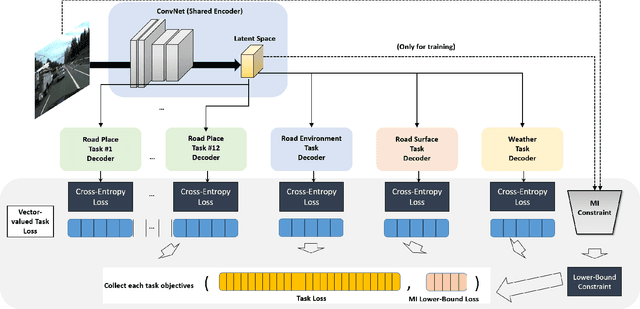

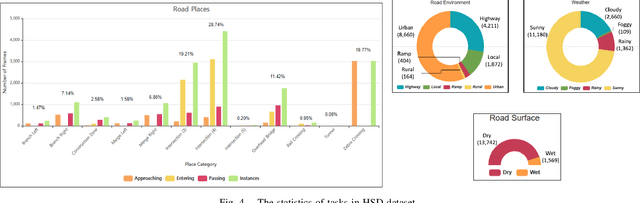
Traffic scene recognition, which requires various visual classification tasks, is a critical ingredient in autonomous vehicles. However, most existing approaches treat each relevant task independently from one another, never considering the entire system as a whole. Because of this, they are limited to utilizing a task-specific set of features for all possible tasks of inference-time, which ignores the capability to leverage common task-invariant contextual knowledge for the task at hand. To address this problem, we propose an algorithm to jointly learn the task-specific and shared representations by adopting a multi-task learning network. Specifically, we present a lower bound for the mutual information constraint between shared feature embedding and input that is considered to be able to extract common contextual information across tasks while preserving essential information of each task jointly. The learned representations capture richer contextual information without additional task-specific network. Extensive experiments on the large-scale dataset HSD demonstrate the effectiveness and superiority of our network over state-of-the-art methods.
Unsupervised Pixel-level Road Defect Detection via Adversarial Image-to-Frequency Transform
Feb 03, 2020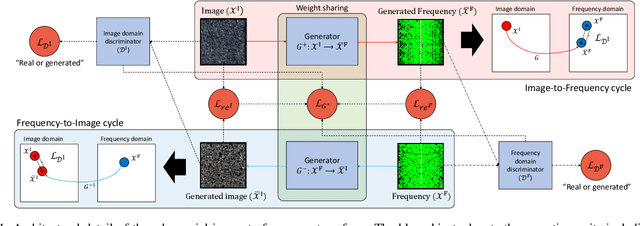
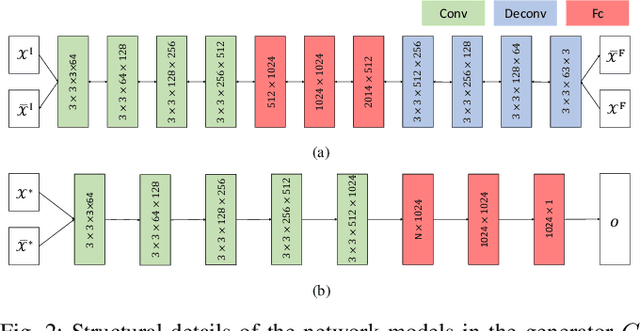
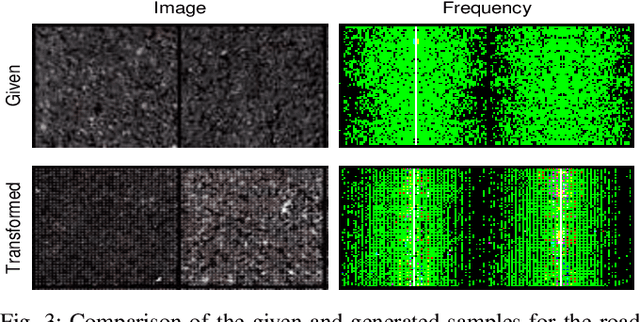
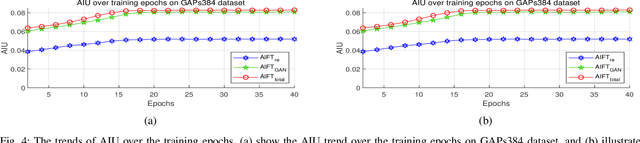
In the past few years, the performance of road defect detection has been remarkably improved thanks to advancements on various studies on computer vision and deep learning. Although a large-scale and well-annotated datasets enhance the performance of detecting road pavement defects to some extent, it is still challengeable to derive a model which can perform reliably for various road conditions in practice, because it is intractable to construct a dataset considering diverse road conditions and defect patterns. To end this, we propose an unsupervised approach to detecting road defects, using Adversarial Image-to-Frequency Transform (AIFT). AIFT adopts the unsupervised manner and adversarial learning in deriving the defect detection model, so AIFT does not need annotations for road pavement defects. We evaluate the efficiency of AIFT using GAPs384 dataset, Cracktree200 dataset, CRACK500 dataset, and CFD dataset. The experimental results demonstrate that the proposed approach detects various road detects, and it outperforms existing state-of-the-art approaches.
Boosting Network Weight Separability via Feed-Backward Reconstruction
Oct 20, 2019


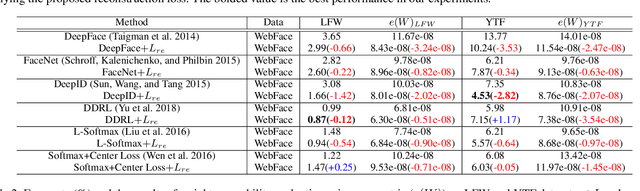
This paper proposes a new evaluation metric and boosting method for weight separability in neural network design. In contrast to general visual recognition methods designed to encourage both intra-class compactness and inter-class separability of latent features, we focus on estimating linear independence of column vectors in weight matrix and improving the separability of weight vectors. To this end, we propose an evaluation metric for weight separability based on semi-orthogonality of a matrix and Frobenius distance, and the feed-backward reconstruction loss which explicitly encourages weight separability between the column vectors in the weight matrix. The experimental results on image classification and face recognition demonstrate that the weight separability boosting via minimization of feed-backward reconstruction loss can improve the visual recognition performance, hence universally boosting the performance on various visual recognition tasks.
Unconstrained Road Marking Recognition with Generative Adversarial Networks
Oct 10, 2019
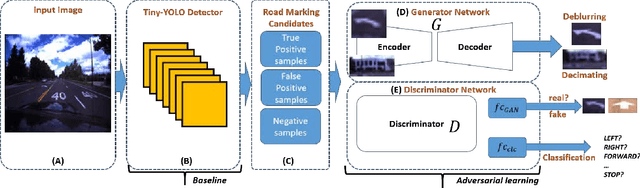
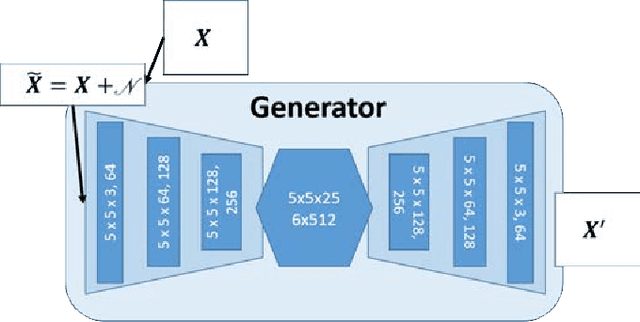
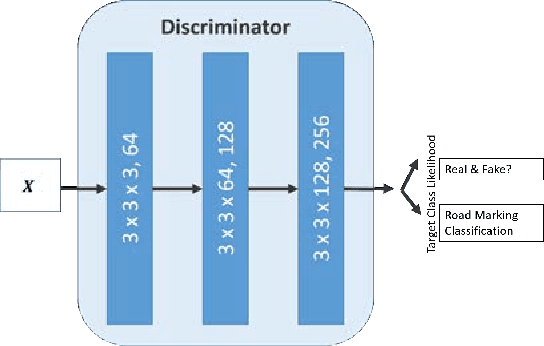
Recent road marking recognition has achieved great success in the past few years along with the rapid development of deep learning. Although considerable advances have been made, they are often over-dependent on unrepresentative datasets and constrained conditions. In this paper, to overcome these drawbacks, we propose an alternative method that achieves higher accuracy and generates high-quality samples as data augmentation. With the following two major contributions: 1) The proposed deblurring network can successfully recover a clean road marking from a blurred one by adopting generative adversarial networks (GAN). 2) The proposed data augmentation method, based on mutual information, can preserve and learn semantic context from the given dataset. We construct and train a class-conditional GAN to increase the size of training set, which makes it suitable to recognize target. The experimental results have shown that our proposed framework generates deblurred clean samples from blurry ones, and outperforms other methods even with unconstrained road marking datasets.
Practical License Plate Recognition in Unconstrained Surveillance Systems with Adversarial Super-Resolution
Oct 10, 2019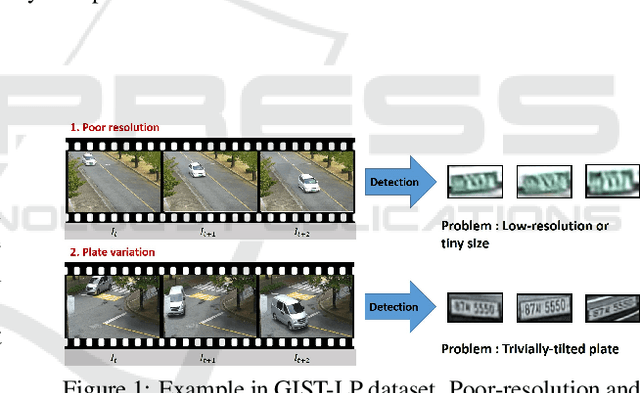
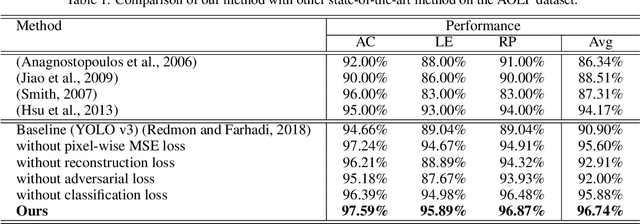
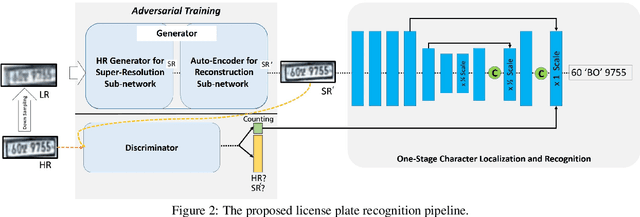
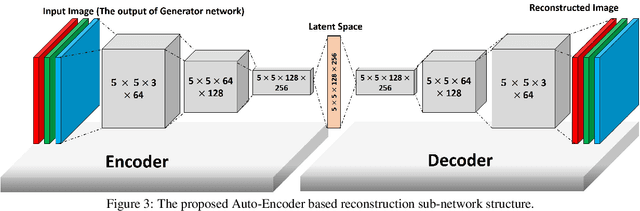
Although most current license plate (LP) recognition applications have been significantly advanced, they are still limited to ideal environments where training data are carefully annotated with constrained scenes. In this paper, we propose a novel license plate recognition method to handle unconstrained real world traffic scenes. To overcome these difficulties, we use adversarial super-resolution (SR), and one-stage character segmentation and recognition. Combined with a deep convolutional network based on VGG-net, our method provides simple but reasonable training procedure. Moreover, we introduce GIST-LP, a challenging LP dataset where image samples are effectively collected from unconstrained surveillance scenes. Experimental results on AOLP and GIST-LP dataset illustrate that our method, without any scene-specific adaptation, outperforms current LP recognition approaches in accuracy and provides visual enhancement in our SR results that are easier to understand than original data.