 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlphaFace: High Fidelity and Real-time Face Swapper Robust to Facial Pose
Jan 23, 2026Existing face-swapping methods often deliver competitive results in constrained settings but exhibit substantial quality degradation when handling extreme facial poses. To improve facial pose robustness, explicit geometric features are applied, but this approach remains problematic since it introduces additional dependencies and increases computational cost. Diffusion-based methods have achieved remarkable results; however, they are impractical for real-time processing. We introduce AlphaFace, which leverages an open-source vision-language model and CLIP image and text embeddings to apply novel visual and textual semantic contrastive losses. AlphaFace enables stronger identity representation and more precise attribute preservation, all while maintaining real-time performance. Comprehensive experiments across FF++, MPIE, and LPFF demonstrate that AlphaFace surpasses state-of-the-art methods in pose-challenging cases. The project is publicly available on `https://github.com/andrewyu90/Alphaface_Official.git'.
From News to Returns: A Granger-Causal Hypergraph Transformer on the Sphere
Oct 05, 2025We propose the Causal Sphere Hypergraph Transformer (CSHT), a novel architecture for interpretable financial time-series forecasting that unifies \emph{Granger-causal hypergraph structure}, \emph{Riemannian geometry}, and \emph{causally masked Transformer attention}. CSHT models the directional influence of financial news and sentiment on asset returns by extracting multivariate Granger-causal dependencies, which are encoded as directional hyperedges on the surface of a hypersphere. Attention is constrained via angular masks that preserve both temporal directionality and geometric consistency. Evaluated on S\&P 500 data from 2018 to 2023, including the 2020 COVID-19 shock, CSHT consistently outperforms baselines across return prediction, regime classification, and top-asset ranking tasks. By enforcing predictive causal structure and embedding variables in a Riemannian manifold, CSHT delivers both \emph{robust generalisation across market regimes} and \emph{transparent attribution pathways} from macroeconomic events to stock-level responses. These results suggest that CSHT is a principled and practical solution for trustworthy financial forecasting under uncertainty.
Adversarial Diffusion Model for Unsupervised Domain-Adaptive Semantic Segmentation
Dec 22, 2024Semantic segmentation requires labour-intensive labelling tasks to obtain the supervision signals, and because of this issue, it is encouraged that using domain adaptation, which transfers information from the existing labelled source domains to unlabelled or weakly labelled target domains, is essential. However, it is intractable to find a well-generalised representation which can describe two domains due to probabilistic or geometric difference between the two domains. This paper presents a novel method, the Conditional and Inter-coder Connected Latent Diffusion (CICLD) based Semantic Segmentation Model, to advance unsupervised domain adaptation (UDA) for semantic segmentation tasks. Leveraging the strengths of latent diffusion models and adversarial learning, our method effectively bridges the gap between synthetic and real-world imagery. CICLD incorporates a conditioning mechanism to improve contextual understanding during segmentation and an inter-coder connection to preserve fine-grained details and spatial hierarchies. Additionally, adversarial learning aligns latent feature distributions across source, mixed, and target domains, further enhancing generalisation. Extensive experiments are conducted across three benchmark datasets-GTA5, Synthia, and Cityscape-shows that CICLD outperforms state-of-the-art UDA methods. Notably, the proposed method achieves a mean Intersection over Union (mIoU) of 74.4 for the GTA5 to Cityscape UDA setting and 67.2 mIoU for the Synthia to Cityscape UDA setting. This project is publicly available on 'https://github.com/andreYoo/CICLD'.
Breaking Down Financial News Impact: A Novel AI Approach with Geometric Hypergraphs
Aug 31, 2024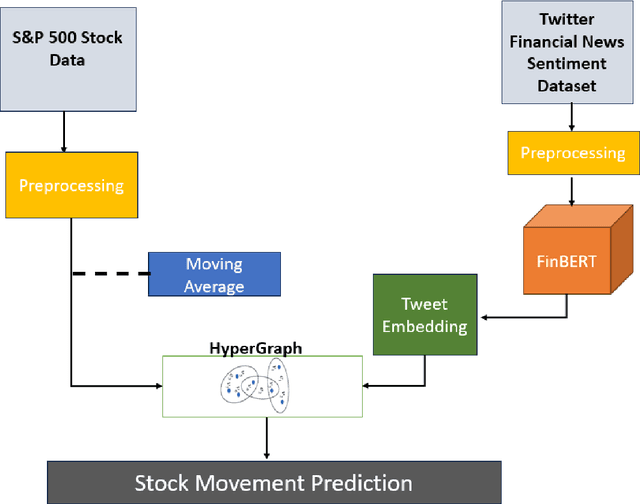
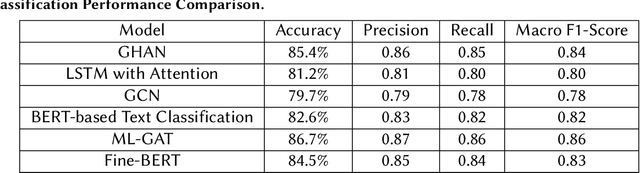
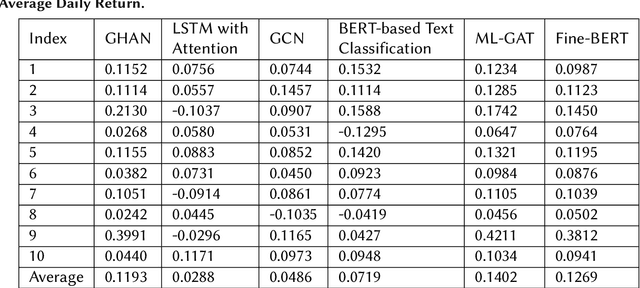
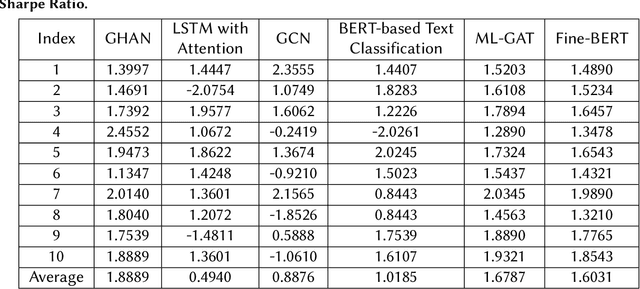
In the fast-paced and volatile financial markets, accurately predicting stock movements based on financial news is critical for investors and analysts. Traditional models often struggle to capture the intricate and dynamic relationships between news events and market reactions, limiting their ability to provide actionable insights. This paper introduces a novel approach leveraging Explainable Artificial Intelligence (XAI) through the development of a Geometric Hypergraph Attention Network (GHAN) to analyze the impact of financial news on market behaviours. Geometric hypergraphs extend traditional graph structures by allowing edges to connect multiple nodes, effectively modelling high-order relationships and interactions among financial entities and news events. This unique capability enables the capture of complex dependencies, such as the simultaneous impact of a single news event on multiple stocks or sectors, which traditional models frequently overlook. By incorporating attention mechanisms within hypergraphs, GHAN enhances the model's ability to focus on the most relevant information, ensuring more accurate predictions and better interpretability. Additionally, we employ BERT-based embeddings to capture the semantic richness of financial news texts, providing a nuanced understanding of the content. Using a comprehensive financial news dataset, our GHAN model addresses key challenges in financial news impact analysis, including the complexity of high-order interactions, the necessity for model interpretability, and the dynamic nature of financial markets. Integrating attention mechanisms and SHAP values within GHAN ensures transparency, highlighting the most influential factors driving market predictions. Empirical validation demonstrates the superior effectiveness of our approach over traditional sentiment analysis and time-series models.
Multi-class Road Defect Detection and Segmentation using Spatial and Channel-wise Attention for Autonomous Road Repairing
Feb 06, 2024



Road pavement detection and segmentation are critical for developing autonomous road repair systems. However, developing an instance segmentation method that simultaneously performs multi-class defect detection and segmentation is challenging due to the textural simplicity of road pavement image, the diversity of defect geometries, and the morphological ambiguity between classes. We propose a novel end-to-end method for multi-class road defect detection and segmentation. The proposed method comprises multiple spatial and channel-wise attention blocks available to learn global representations across spatial and channel-wise dimensions. Through these attention blocks, more globally generalised representations of morphological information (spatial characteristics) of road defects and colour and depth information of images can be learned. To demonstrate the effectiveness of our framework, we conducted various ablation studies and comparisons with prior methods on a newly collected dataset annotated with nine road defect classes. The experiments show that our proposed method outperforms existing state-of-the-art methods for multi-class road defect detection and segmentation methods.
Road Surface Defect Detection -- From Image-based to Non-image-based: A Survey
Feb 06, 2024



Ensuring traffic safety is crucial, which necessitates the detection and prevention of road surface defects. As a result, there has been a growing interest in the literature on the subject, leading to the development of various road surface defect detection methods. The methods for detecting road defects can be categorised in various ways depending on the input data types or training methodologies. The predominant approach involves image-based methods, which analyse pixel intensities and surface textures to identify defects. Despite their popularity, image-based methods share the distinct limitation of vulnerability to weather and lighting changes. To address this issue, researchers have explored the use of additional sensors, such as laser scanners or LiDARs, providing explicit depth information to enable the detection of defects in terms of scale and volume. However, the exploration of data beyond images has not been sufficiently investigated. In this survey paper, we provide a comprehensive review of road surface defect detection studies, categorising them based on input data types and methodologies used. Additionally, we review recently proposed non-image-based methods and discuss several challenges and open problems associated with these techniques.
Adversarial Denoising Diffusion Model for Unsupervised Anomaly Detection
Dec 07, 2023In this paper, we propose the Adversarial Denoising Diffusion Model (ADDM). The ADDM is based on the Denoising Diffusion Probabilistic Model (DDPM) but complementarily trained by adversarial learning. The proposed adversarial learning is achieved by classifying model-based denoised samples and samples to which random Gaussian noise is added to a specific sampling step. With the addition of explicit adversarial learning on data samples, ADDM can learn the semantic characteristics of the data more robustly during training, which achieves a similar data sampling performance with much fewer sampling steps than DDPM. We apply ADDM to anomaly detection in unsupervised MRI images. Experimental results show that the proposed ADDM outperformed existing generative model-based unsupervised anomaly detection methods. In particular, compared to other DDPM-based anomaly detection methods, the proposed ADDM shows better performance with the same number of sampling steps and similar performance with 50% fewer sampling steps.
An Iterative Method for Unsupervised Robust Anomaly Detection Under Data Contamination
Sep 18, 2023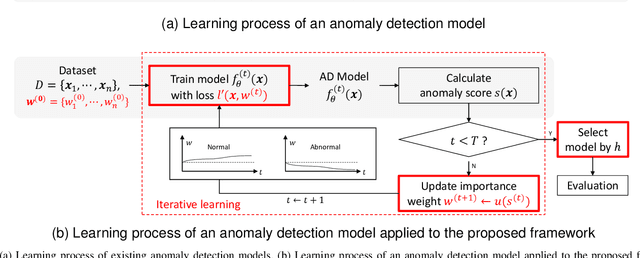
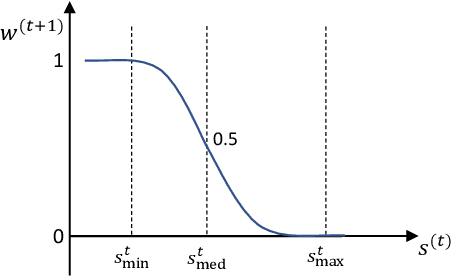
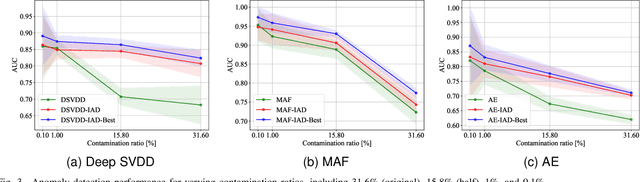
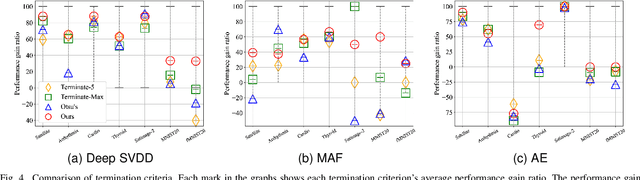
Most deep anomaly detection models are based on learning normality from datasets due to the difficulty of defining abnormality by its diverse and inconsistent nature. Therefore, it has been a common practice to learn normality under the assumption that anomalous data are absent in a training dataset, which we call normality assumption. However, in practice, the normality assumption is often violated due to the nature of real data distributions that includes anomalous tails, i.e., a contaminated dataset. Thereby, the gap between the assumption and actual training data affects detrimentally in learning of an anomaly detection model. In this work, we propose a learning framework to reduce this gap and achieve better normality representation. Our key idea is to identify sample-wise normality and utilize it as an importance weight, which is updated iteratively during the training. Our framework is designed to be model-agnostic and hyperparameter insensitive so that it applies to a wide range of existing methods without careful parameter tuning. We apply our framework to three different representative approaches of deep anomaly detection that are classified into one-class classification-, probabilistic model-, and reconstruction-based approaches. In addition, we address the importance of a termination condition for iterative methods and propose a termination criterion inspired by the anomaly detection objective. We validate that our framework improves the robustness of the anomaly detection models under different levels of contamination ratios on five anomaly detection benchmark datasets and two image datasets. On various contaminated datasets, our framework improves the performance of three representative anomaly detection methods, measured by area under the ROC curve.
Active anomaly detection based on deep one-class classification
Sep 18, 2023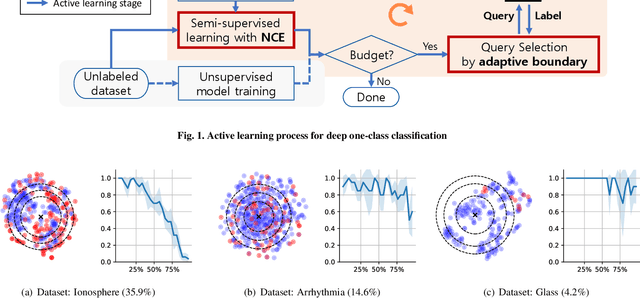
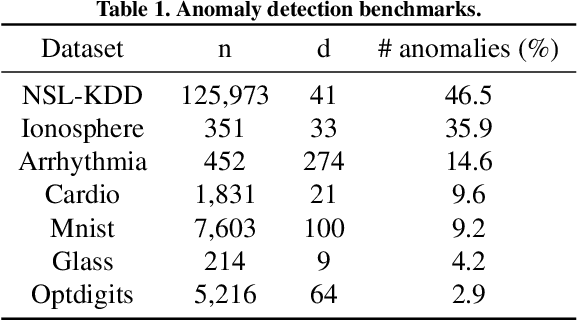
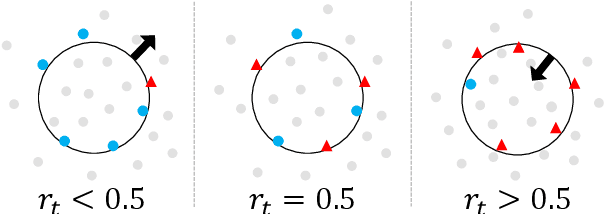
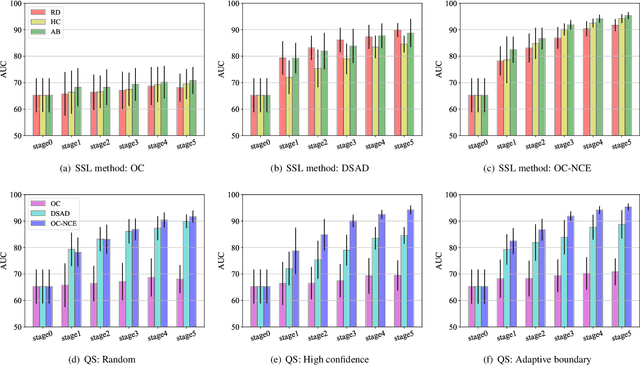
Active learning has been utilized as an efficient tool in building anomaly detection models by leveraging expert feedback. In an active learning framework, a model queries samples to be labeled by experts and re-trains the model with the labeled data samples. It unburdens in obtaining annotated datasets while improving anomaly detection performance. However, most of the existing studies focus on helping experts identify as many abnormal data samples as possible, which is a sub-optimal approach for one-class classification-based deep anomaly detection. In this paper, we tackle two essential problems of active learning for Deep SVDD: query strategy and semi-supervised learning method. First, rather than solely identifying anomalies, our query strategy selects uncertain samples according to an adaptive boundary. Second, we apply noise contrastive estimation in training a one-class classification model to incorporate both labeled normal and abnormal data effectively. We analyze that the proposed query strategy and semi-supervised loss individually improve an active learning process of anomaly detection and further improve when combined together on seven anomaly detection datasets.
* Pattern Recognition Letters 2023
Unsupervised Deep One-Class Classification with Adaptive Threshold based on Training Dynamics
Feb 13, 2023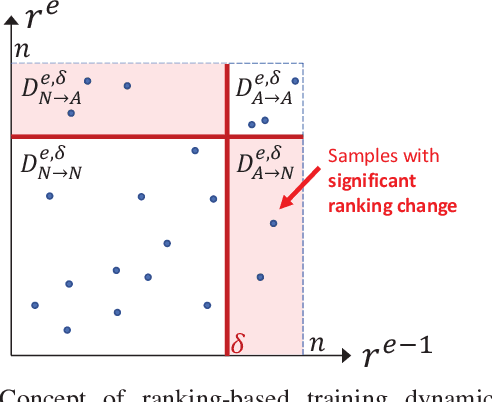
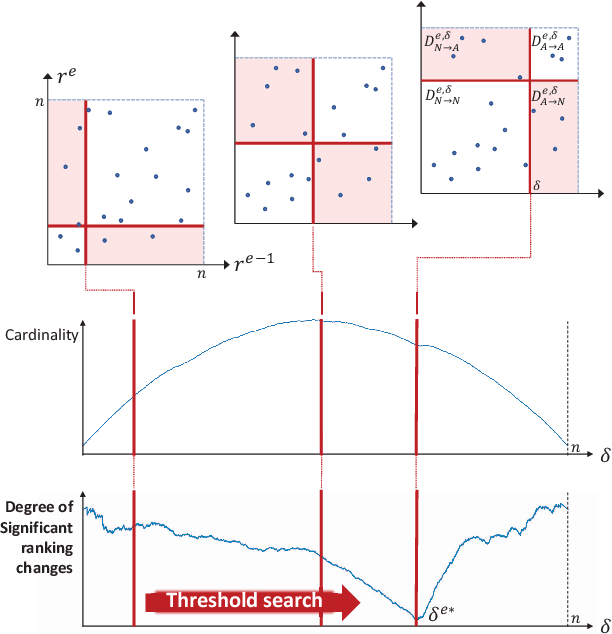
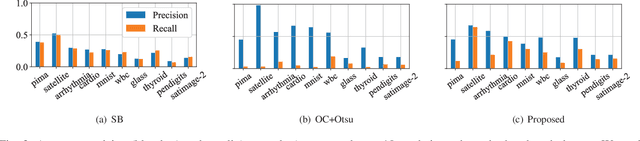
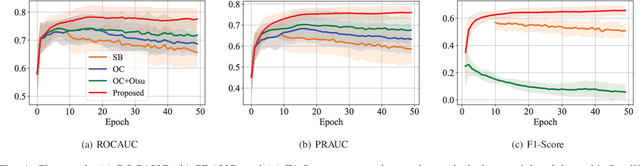
One-class classification has been a prevailing method in building deep anomaly detection models under the assumption that a dataset consisting of normal samples is available. In practice, however, abnormal samples are often mixed in a training dataset, and they detrimentally affect the training of deep models, which limits their applicability. For robust normality learning of deep practical models, we propose an unsupervised deep one-class classification that learns normality from pseudo-labeled normal samples, i.e., outlier detection in single cluster scenarios. To this end, we propose a pseudo-labeling method by an adaptive threshold selected by ranking-based training dynamics. The experiments on 10 anomaly detection benchmarks show that our method effectively improves performance on anomaly detection by sizable margins.