 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState-Inference-Based Prompting for Natural Language Trading with Game NPCs
Jul 09, 2025Large Language Models enable dynamic game interactions but struggle with rule-governed trading systems. Current implementations suffer from rule violations, such as item hallucinations and calculation errors, that erode player trust. Here, State-Inference-Based Prompting (SIBP) enables reliable trading through autonomous dialogue state inference and context-specific rule adherence. The approach decomposes trading into six states within a unified prompt framework, implementing context-aware item referencing and placeholder-based price calculations. Evaluation across 100 trading dialogues demonstrates >97% state compliance, >95% referencing accuracy, and 99.7% calculation precision. SIBP maintains computational efficiency while outperforming baseline approaches, establishing a practical foundation for trustworthy NPC interactions in commercial games.
Active anomaly detection based on deep one-class classification
Sep 18, 2023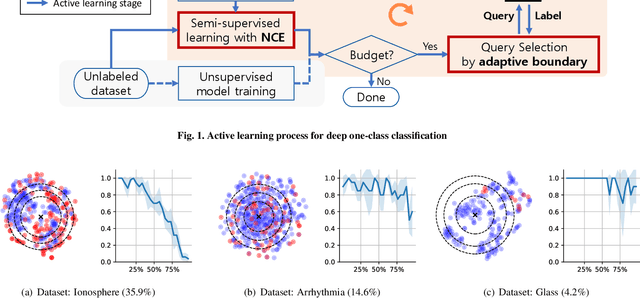
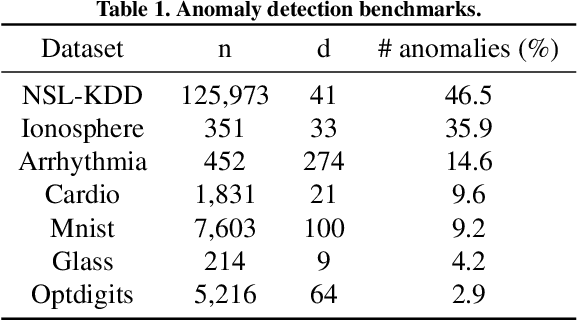
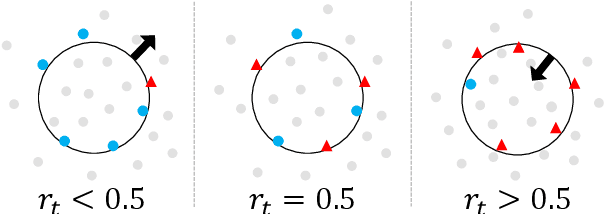
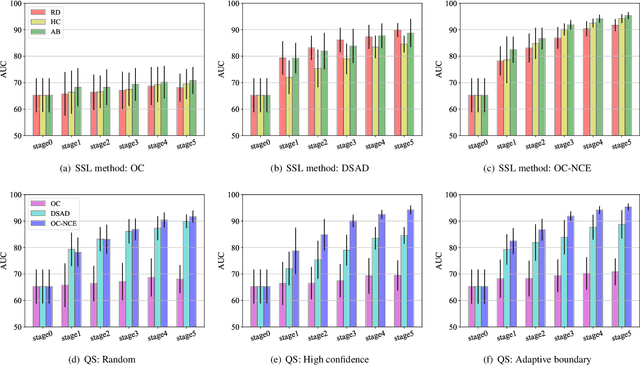
Active learning has been utilized as an efficient tool in building anomaly detection models by leveraging expert feedback. In an active learning framework, a model queries samples to be labeled by experts and re-trains the model with the labeled data samples. It unburdens in obtaining annotated datasets while improving anomaly detection performance. However, most of the existing studies focus on helping experts identify as many abnormal data samples as possible, which is a sub-optimal approach for one-class classification-based deep anomaly detection. In this paper, we tackle two essential problems of active learning for Deep SVDD: query strategy and semi-supervised learning method. First, rather than solely identifying anomalies, our query strategy selects uncertain samples according to an adaptive boundary. Second, we apply noise contrastive estimation in training a one-class classification model to incorporate both labeled normal and abnormal data effectively. We analyze that the proposed query strategy and semi-supervised loss individually improve an active learning process of anomaly detection and further improve when combined together on seven anomaly detection datasets.
* Pattern Recognition Letters 2023
An Iterative Method for Unsupervised Robust Anomaly Detection Under Data Contamination
Sep 18, 2023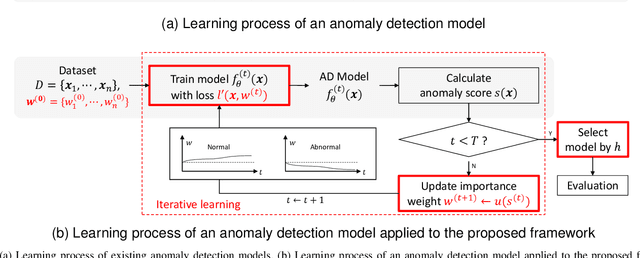
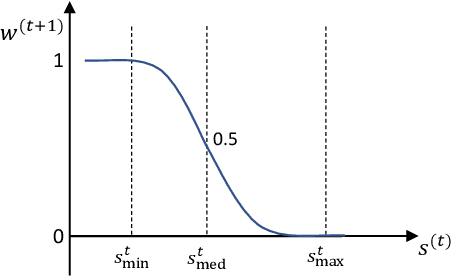
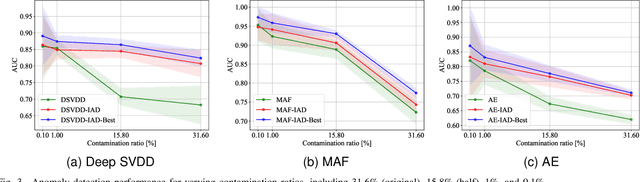
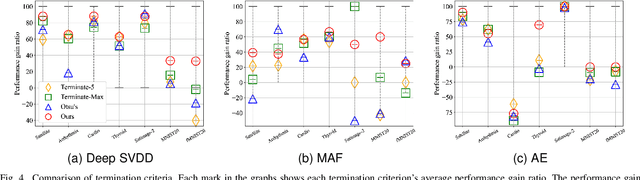
Most deep anomaly detection models are based on learning normality from datasets due to the difficulty of defining abnormality by its diverse and inconsistent nature. Therefore, it has been a common practice to learn normality under the assumption that anomalous data are absent in a training dataset, which we call normality assumption. However, in practice, the normality assumption is often violated due to the nature of real data distributions that includes anomalous tails, i.e., a contaminated dataset. Thereby, the gap between the assumption and actual training data affects detrimentally in learning of an anomaly detection model. In this work, we propose a learning framework to reduce this gap and achieve better normality representation. Our key idea is to identify sample-wise normality and utilize it as an importance weight, which is updated iteratively during the training. Our framework is designed to be model-agnostic and hyperparameter insensitive so that it applies to a wide range of existing methods without careful parameter tuning. We apply our framework to three different representative approaches of deep anomaly detection that are classified into one-class classification-, probabilistic model-, and reconstruction-based approaches. In addition, we address the importance of a termination condition for iterative methods and propose a termination criterion inspired by the anomaly detection objective. We validate that our framework improves the robustness of the anomaly detection models under different levels of contamination ratios on five anomaly detection benchmark datasets and two image datasets. On various contaminated datasets, our framework improves the performance of three representative anomaly detection methods, measured by area under the ROC curve.
Unsupervised Deep One-Class Classification with Adaptive Threshold based on Training Dynamics
Feb 13, 2023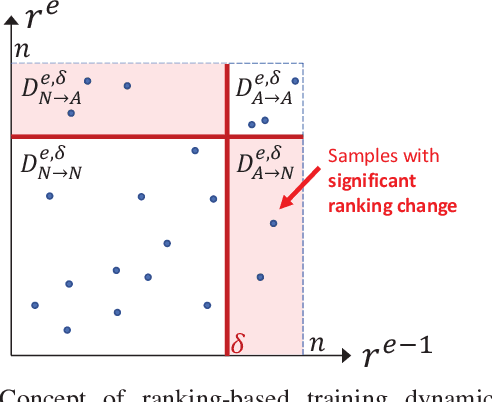
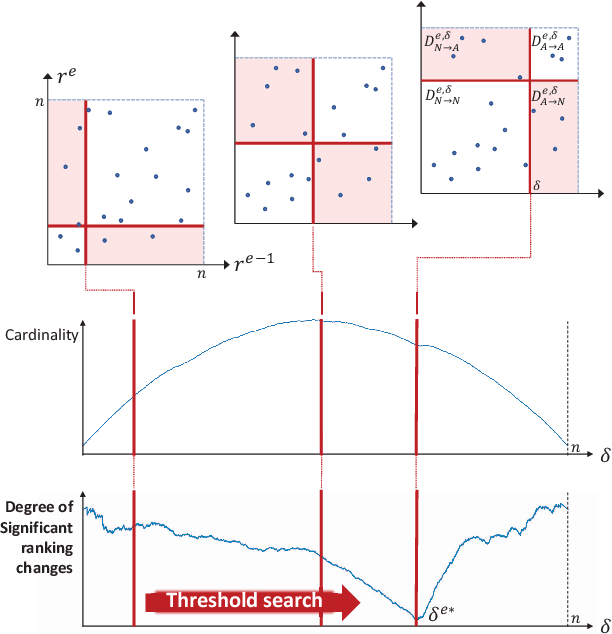
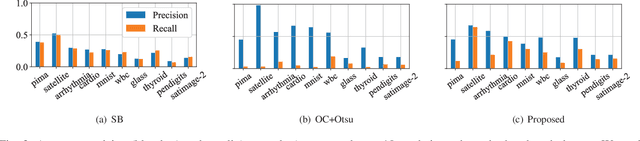
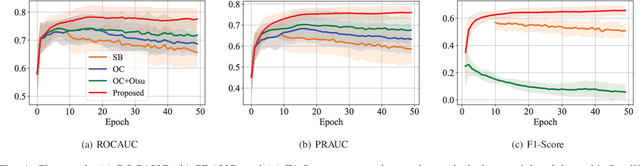
One-class classification has been a prevailing method in building deep anomaly detection models under the assumption that a dataset consisting of normal samples is available. In practice, however, abnormal samples are often mixed in a training dataset, and they detrimentally affect the training of deep models, which limits their applicability. For robust normality learning of deep practical models, we propose an unsupervised deep one-class classification that learns normality from pseudo-labeled normal samples, i.e., outlier detection in single cluster scenarios. To this end, we propose a pseudo-labeling method by an adaptive threshold selected by ranking-based training dynamics. The experiments on 10 anomaly detection benchmarks show that our method effectively improves performance on anomaly detection by sizable margins.
DiffTune$^+$: Hyperparameter-Free Auto-Tuning using Auto-Differentiation
Dec 06, 2022


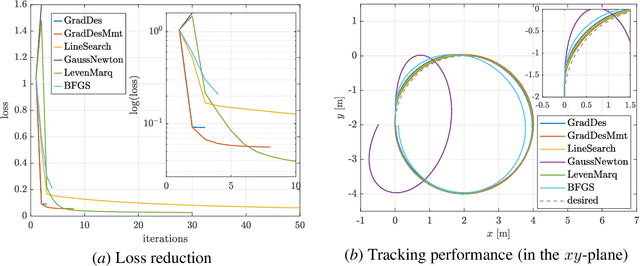
Controller tuning is a vital step to ensure the controller delivers its designed performance. DiffTune has been proposed as an automatic tuning method that unrolls the dynamical system and controller into a computational graph and uses auto-differentiation to obtain the gradient for the controller's parameter update. However, DiffTune uses the vanilla gradient descent to iteratively update the parameter, in which the performance largely depends on the choice of the learning rate (as a hyperparameter). In this paper, we propose to use hyperparameter-free methods to update the controller parameters. We find the optimal parameter update by maximizing the loss reduction, where a predicted loss based on the approximated state and control is used for the maximization. Two methods are proposed to optimally update the parameters and are compared with related variants in simulations on a Dubin's car and a quadrotor. Simulation experiments show that the proposed first-order method outperforms the hyperparameter-based methods and is more robust than the second-order hyperparameter-free methods.
DiffTune: Auto-Tuning through Auto-Differentiation
Sep 20, 2022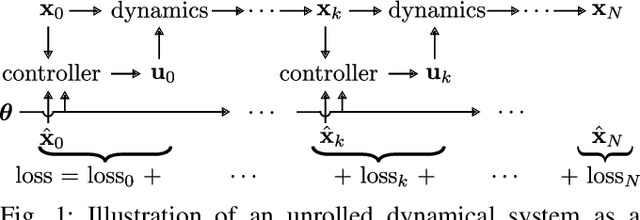


The performance of a robot controller depends on the choice of its parameters, which require careful tuning. In this paper, we present DiffTune, a novel, gradient-based automatic tuning framework. Our method unrolls the dynamical system and controller as a computational graph and updates the controller parameters through gradient-based optimization. Unlike the commonly used back-propagation scheme, the gradient in DiffTune is obtained through sensitivity propagation, a forward-mode auto differentiation technique that runs parallel to the system's evolution. We validate the proposed auto-tune approach on a Dubin's car and a quadrotor in challenging simulation environments. Simulation experiments show that the approach is robust to uncertainties in the system dynamics and environment and generalizes well to unseen trajectories in tuning.
Normality-Calibrated Autoencoder for Unsupervised Anomaly Detection on Data Contamination
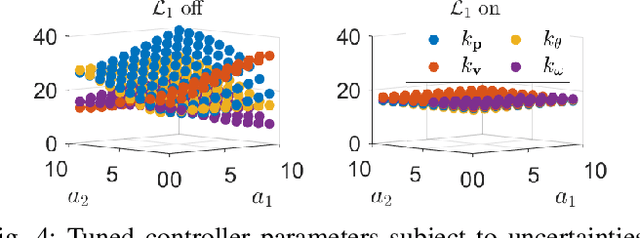
Oct 28, 2021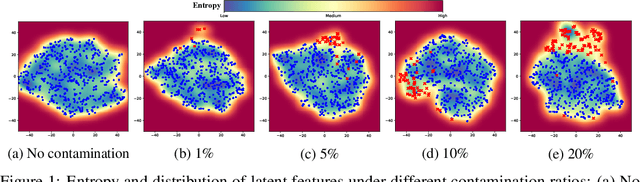
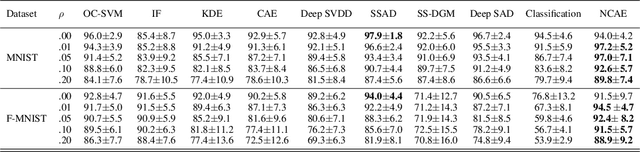
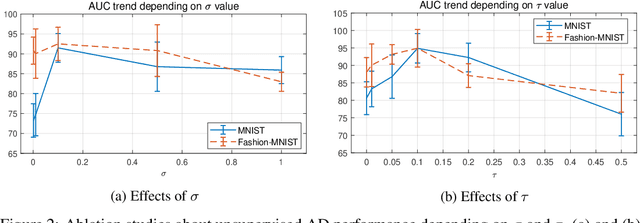
In this paper, we propose Normality-Calibrated Autoencoder (NCAE), which can boost anomaly detection performance on the contaminated datasets without any prior information or explicit abnormal samples in the training phase. The NCAE adversarially generates high confident normal samples from a latent space having low entropy and leverages them to predict abnormal samples in a training dataset. NCAE is trained to minimise reconstruction errors in uncontaminated samples and maximise reconstruction errors in contaminated samples. The experimental results demonstrate that our method outperforms shallow, hybrid, and deep methods for unsupervised anomaly detection and achieves comparable performance compared with semi-supervised methods using labelled anomaly samples in the training phase. The source code is publicly available on `https://github.com/andreYoo/NCAE_UAD.git'.
Camera-Tracklet-Aware Contrastive Learning for Unsupervised Vehicle Re-Identification
Sep 14, 2021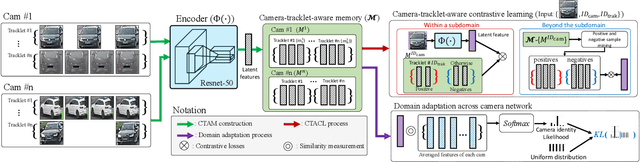
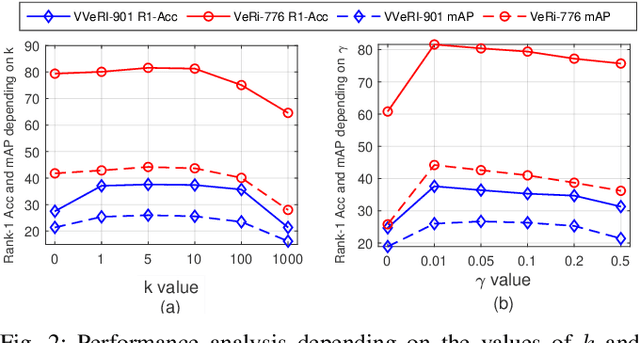
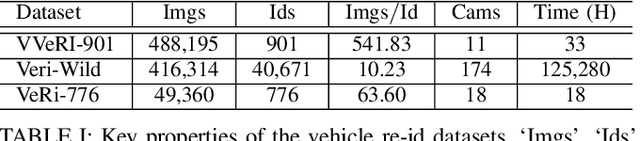
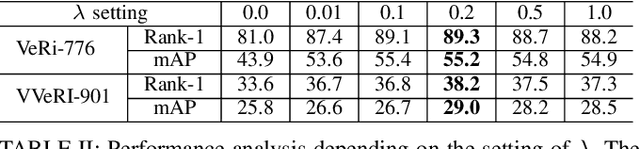
Recently, vehicle re-identification methods based on deep learning constitute remarkable achievement. However, this achievement requires large-scale and well-annotated datasets. In constructing the dataset, assigning globally available identities (Ids) to vehicles captured from a great number of cameras is labour-intensive, because it needs to consider their subtle appearance differences or viewpoint variations. In this paper, we propose camera-tracklet-aware contrastive learning (CTACL) using the multi-camera tracklet information without vehicle identity labels. The proposed CTACL divides an unlabelled domain, i.e., entire vehicle images, into multiple camera-level subdomains and conducts contrastive learning within and beyond the subdomains. The positive and negative samples for contrastive learning are defined using tracklet Ids of each camera. Additionally, the domain adaptation across camera networks is introduced to improve the generalisation performance of learnt representations and alleviate the performance degradation resulted from the domain gap between the subdomains. We demonstrate the effectiveness of our approach on video-based and image-based vehicle Re-ID datasets. Experimental results show that the proposed method outperforms the recent state-of-the-art unsupervised vehicle Re-ID methods. The source code for this paper is publicly available on `https://github.com/andreYoo/CTAM-CTACL-VVReID.git'.