 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Iterative Method for Unsupervised Robust Anomaly Detection Under Data Contamination
Sep 18, 2023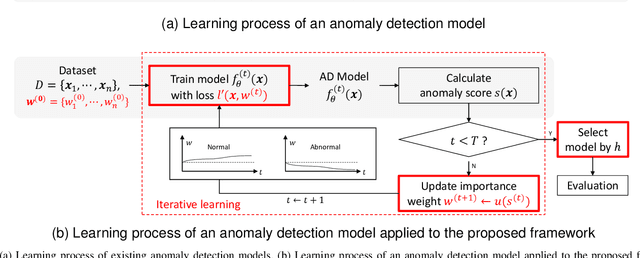
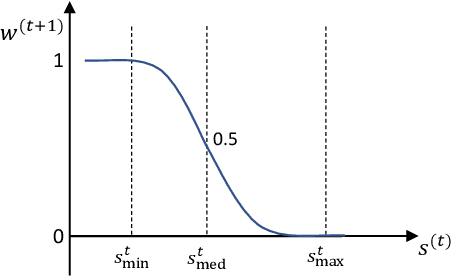
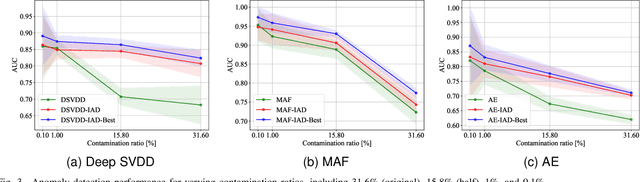
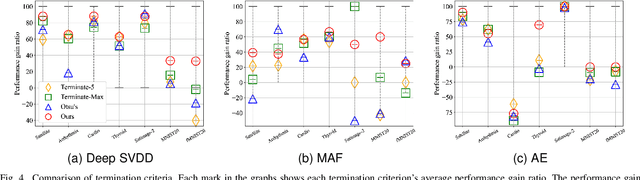
Most deep anomaly detection models are based on learning normality from datasets due to the difficulty of defining abnormality by its diverse and inconsistent nature. Therefore, it has been a common practice to learn normality under the assumption that anomalous data are absent in a training dataset, which we call normality assumption. However, in practice, the normality assumption is often violated due to the nature of real data distributions that includes anomalous tails, i.e., a contaminated dataset. Thereby, the gap between the assumption and actual training data affects detrimentally in learning of an anomaly detection model. In this work, we propose a learning framework to reduce this gap and achieve better normality representation. Our key idea is to identify sample-wise normality and utilize it as an importance weight, which is updated iteratively during the training. Our framework is designed to be model-agnostic and hyperparameter insensitive so that it applies to a wide range of existing methods without careful parameter tuning. We apply our framework to three different representative approaches of deep anomaly detection that are classified into one-class classification-, probabilistic model-, and reconstruction-based approaches. In addition, we address the importance of a termination condition for iterative methods and propose a termination criterion inspired by the anomaly detection objective. We validate that our framework improves the robustness of the anomaly detection models under different levels of contamination ratios on five anomaly detection benchmark datasets and two image datasets. On various contaminated datasets, our framework improves the performance of three representative anomaly detection methods, measured by area under the ROC curve.
Active anomaly detection based on deep one-class classification
Sep 18, 2023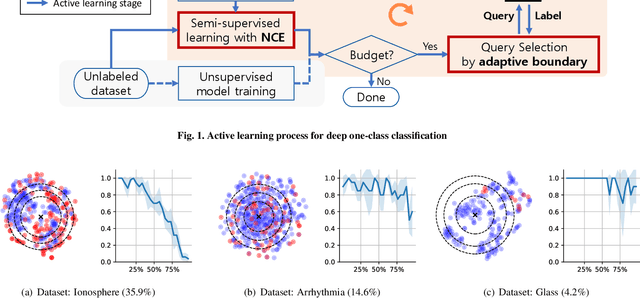
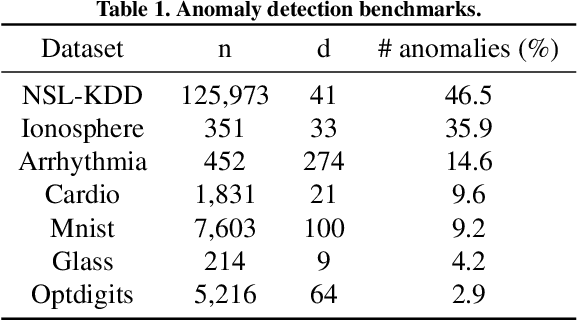
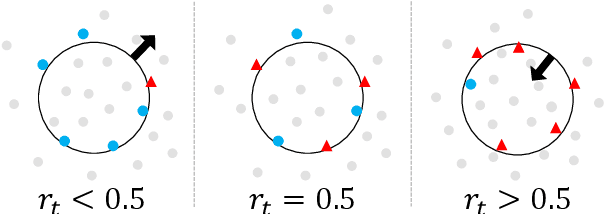
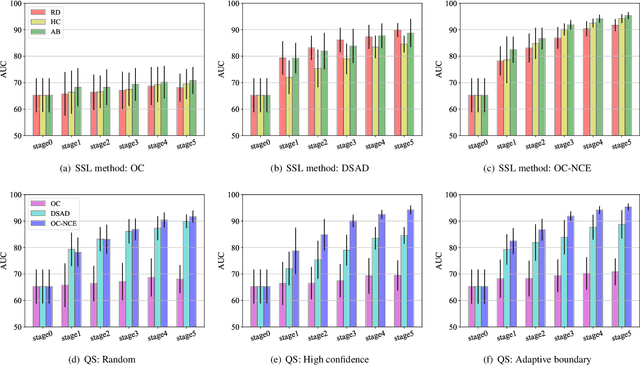
Active learning has been utilized as an efficient tool in building anomaly detection models by leveraging expert feedback. In an active learning framework, a model queries samples to be labeled by experts and re-trains the model with the labeled data samples. It unburdens in obtaining annotated datasets while improving anomaly detection performance. However, most of the existing studies focus on helping experts identify as many abnormal data samples as possible, which is a sub-optimal approach for one-class classification-based deep anomaly detection. In this paper, we tackle two essential problems of active learning for Deep SVDD: query strategy and semi-supervised learning method. First, rather than solely identifying anomalies, our query strategy selects uncertain samples according to an adaptive boundary. Second, we apply noise contrastive estimation in training a one-class classification model to incorporate both labeled normal and abnormal data effectively. We analyze that the proposed query strategy and semi-supervised loss individually improve an active learning process of anomaly detection and further improve when combined together on seven anomaly detection datasets.
* Pattern Recognition Letters 2023
Unsupervised Deep One-Class Classification with Adaptive Threshold based on Training Dynamics
Feb 13, 2023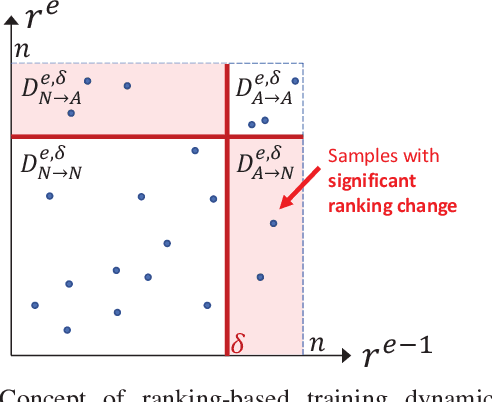
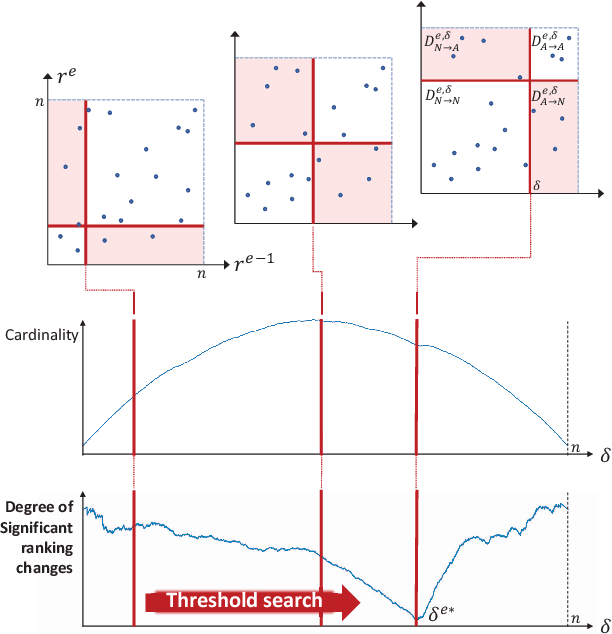
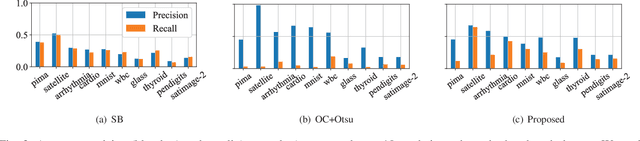
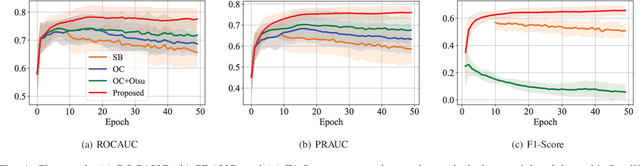
One-class classification has been a prevailing method in building deep anomaly detection models under the assumption that a dataset consisting of normal samples is available. In practice, however, abnormal samples are often mixed in a training dataset, and they detrimentally affect the training of deep models, which limits their applicability. For robust normality learning of deep practical models, we propose an unsupervised deep one-class classification that learns normality from pseudo-labeled normal samples, i.e., outlier detection in single cluster scenarios. To this end, we propose a pseudo-labeling method by an adaptive threshold selected by ranking-based training dynamics. The experiments on 10 anomaly detection benchmarks show that our method effectively improves performance on anomaly detection by sizable margins.