 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Role Assignment for Multi-Agent Debate
Jan 23, 2026Multi-agent large language model (LLM) and vision-language model (VLM) debate systems employ specialized roles for complex problem-solving, yet model specializations are not leveraged to decide which model should fill which role. We propose dynamic role assignment, a framework that runs a Meta-Debate to select suitable agents before the actual debate. The meta-debate has two stages: (1) proposal, where candidates provide role-tailored arguments, and (2) peer review, where proposals are scored with data and role-specific criteria to choose the best agent for each position. We evaluate our method on LLM problem solving benchmarks. Applied on top of existing debate systems, our approach consistently outperforms uniform assignments (filling all roles with the same model) by up to 74.8% and random assignments (assigning models to roles without considering their suitability) by up to 29.7%, depending on the task and the specific assignment. This work establishes a new paradigm for multi-agent system design, shifting from static agent deployment to dynamic and capability-aware selection.
ELiC: Efficient LiDAR Geometry Compression via Cross-Bit-depth Feature Propagation and Bag-of-Encoders
Nov 18, 2025Hierarchical LiDAR geometry compression encodes voxel occupancies from low to high bit-depths, yet prior methods treat each depth independently and re-estimate local context from coordinates at every level, limiting compression efficiency. We present ELiC, a real-time framework that combines cross-bit-depth feature propagation, a Bag-of-Encoders (BoE) selection scheme, and a Morton-order-preserving hierarchy. Cross-bit-depth propagation reuses features extracted at denser, lower depths to support prediction at sparser, higher depths. BoE selects, per depth, the most suitable coding network from a small pool, adapting capacity to observed occupancy statistics without training a separate model for each level. The Morton hierarchy maintains global Z-order across depth transitions, eliminating per-level sorting and reducing latency. Together these components improve entropy modeling and computation efficiency, yielding state-of-the-art compression at real-time throughput on Ford and SemanticKITTI. Code and models will be released upon publication.
ATLANTIS: AI-driven Threat Localization, Analysis, and Triage Intelligence System
Sep 18, 2025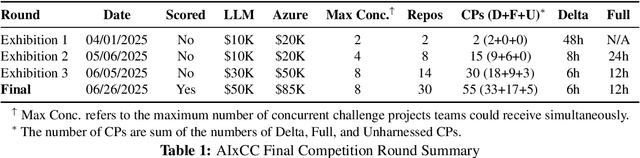
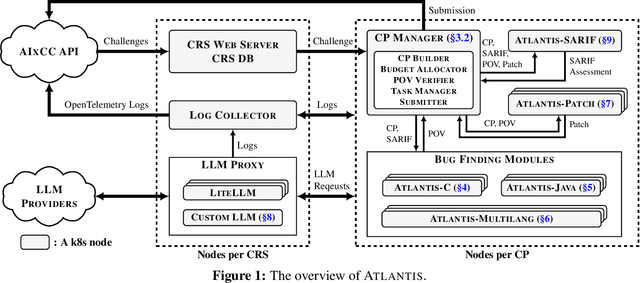
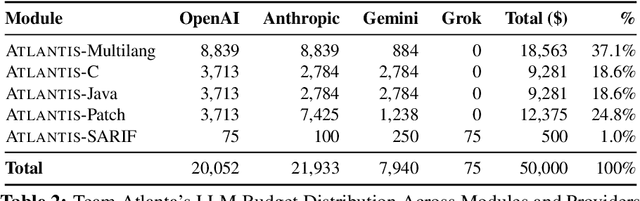
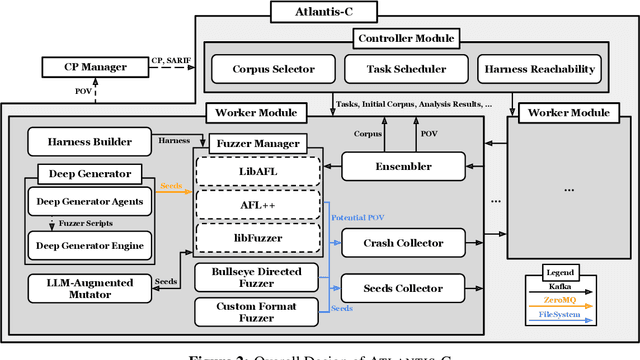
We present ATLANTIS, the cyber reasoning system developed by Team Atlanta that won 1st place in the Final Competition of DARPA's AI Cyber Challenge (AIxCC) at DEF CON 33 (August 2025). AIxCC (2023-2025) challenged teams to build autonomous cyber reasoning systems capable of discovering and patching vulnerabilities at the speed and scale of modern software. ATLANTIS integrates large language models (LLMs) with program analysis -- combining symbolic execution, directed fuzzing, and static analysis -- to address limitations in automated vulnerability discovery and program repair. Developed by researchers at Georgia Institute of Technology, Samsung Research, KAIST, and POSTECH, the system addresses core challenges: scaling across diverse codebases from C to Java, achieving high precision while maintaining broad coverage, and producing semantically correct patches that preserve intended behavior. We detail the design philosophy, architectural decisions, and implementation strategies behind ATLANTIS, share lessons learned from pushing the boundaries of automated security when program analysis meets modern AI, and release artifacts to support reproducibility and future research.
Virtual Multiplex Staining for Histological Images using a Marker-wise Conditioned Diffusion Model
Aug 20, 2025Multiplex imaging is revolutionizing pathology by enabling the simultaneous visualization of multiple biomarkers within tissue samples, providing molecular-level insights that traditional hematoxylin and eosin (H&E) staining cannot provide. However, the complexity and cost of multiplex data acquisition have hindered its widespread adoption. Additionally, most existing large repositories of H&E images lack corresponding multiplex images, limiting opportunities for multimodal analysis. To address these challenges, we leverage recent advances in latent diffusion models (LDMs), which excel at modeling complex data distributions utilizing their powerful priors for fine-tuning to a target domain. In this paper, we introduce a novel framework for virtual multiplex staining that utilizes pretrained LDM parameters to generate multiplex images from H&E images using a conditional diffusion model. Our approach enables marker-by-marker generation by conditioning the diffusion model on each marker, while sharing the same architecture across all markers. To tackle the challenge of varying pixel value distributions across different marker stains and to improve inference speed, we fine-tune the model for single-step sampling, enhancing both color contrast fidelity and inference efficiency through pixel-level loss functions. We validate our framework on two publicly available datasets, notably demonstrating its effectiveness in generating up to 18 different marker types with improved accuracy, a substantial increase over the 2-3 marker types achieved in previous approaches. This validation highlights the potential of our framework, pioneering virtual multiplex staining. Finally, this paper bridges the gap between H&E and multiplex imaging, potentially enabling retrospective studies and large-scale analyses of existing H&E image repositories.
State-Inference-Based Prompting for Natural Language Trading with Game NPCs
Jul 09, 2025Large Language Models enable dynamic game interactions but struggle with rule-governed trading systems. Current implementations suffer from rule violations, such as item hallucinations and calculation errors, that erode player trust. Here, State-Inference-Based Prompting (SIBP) enables reliable trading through autonomous dialogue state inference and context-specific rule adherence. The approach decomposes trading into six states within a unified prompt framework, implementing context-aware item referencing and placeholder-based price calculations. Evaluation across 100 trading dialogues demonstrates >97% state compliance, >95% referencing accuracy, and 99.7% calculation precision. SIBP maintains computational efficiency while outperforming baseline approaches, establishing a practical foundation for trustworthy NPC interactions in commercial games.
DualEdit: Dual Editing for Knowledge Updating in Vision-Language Models
Jun 16, 2025Model editing aims to efficiently update a pre-trained model's knowledge without the need for time-consuming full retraining. While existing pioneering editing methods achieve promising results, they primarily focus on editing single-modal language models (LLMs). However, for vision-language models (VLMs), which involve multiple modalities, the role and impact of each modality on editing performance remain largely unexplored. To address this gap, we explore the impact of textual and visual modalities on model editing and find that: (1) textual and visual representations reach peak sensitivity at different layers, reflecting their varying importance; and (2) editing both modalities can efficiently update knowledge, but this comes at the cost of compromising the model's original capabilities. Based on our findings, we propose DualEdit, an editor that modifies both textual and visual modalities at their respective key layers. Additionally, we introduce a gating module within the more sensitive textual modality, allowing DualEdit to efficiently update new knowledge while preserving the model's original information. We evaluate DualEdit across multiple VLM backbones and benchmark datasets, demonstrating its superiority over state-of-the-art VLM editing baselines as well as adapted LLM editing methods on different evaluation metrics.
RSCF: Relation-Semantics Consistent Filter for Entity Embedding of Knowledge Graph
May 28, 2025In knowledge graph embedding, leveraging relation specific entity transformation has markedly enhanced performance. However, the consistency of embedding differences before and after transformation remains unaddressed, risking the loss of valuable inductive bias inherent in the embeddings. This inconsistency stems from two problems. First, transformation representations are specified for relations in a disconnected manner, allowing dissimilar transformations and corresponding entity embeddings for similar relations. Second, a generalized plug-in approach as a SFBR (Semantic Filter Based on Relations) disrupts this consistency through excessive concentration of entity embeddings under entity-based regularization, generating indistinguishable score distributions among relations. In this paper, we introduce a plug-in KGE method, Relation-Semantics Consistent Filter (RSCF). Its entity transformation has three features for enhancing semantic consistency: 1) shared affine transformation of relation embeddings across all relations, 2) rooted entity transformation that adds an entity embedding to its change represented by the transformed vector, and 3) normalization of the change to prevent scale reduction. To amplify the advantages of consistency that preserve semantics on embeddings, RSCF adds relation transformation and prediction modules for enhancing the semantics. In knowledge graph completion tasks with distance-based and tensor decomposition models, RSCF significantly outperforms state-of-the-art KGE methods, showing robustness across all relations and their frequencies.
Affordance-Aware Object Insertion via Mask-Aware Dual Diffusion
Dec 19, 2024As a common image editing operation, image composition involves integrating foreground objects into background scenes. In this paper, we expand the application of the concept of Affordance from human-centered image composition tasks to a more general object-scene composition framework, addressing the complex interplay between foreground objects and background scenes. Following the principle of Affordance, we define the affordance-aware object insertion task, which aims to seamlessly insert any object into any scene with various position prompts. To address the limited data issue and incorporate this task, we constructed the SAM-FB dataset, which contains over 3 million examples across more than 3,000 object categories. Furthermore, we propose the Mask-Aware Dual Diffusion (MADD) model, which utilizes a dual-stream architecture to simultaneously denoise the RGB image and the insertion mask. By explicitly modeling the insertion mask in the diffusion process, MADD effectively facilitates the notion of affordance. Extensive experimental results show that our method outperforms the state-of-the-art methods and exhibits strong generalization performance on in-the-wild images. Please refer to our code on https://github.com/KaKituken/affordance-aware-any.
Multimodal Learning for Embryo Viability Prediction in Clinical IVF
Oct 21, 2024In clinical In-Vitro Fertilization (IVF), identifying the most viable embryo for transfer is important to increasing the likelihood of a successful pregnancy. Traditionally, this process involves embryologists manually assessing embryos' static morphological features at specific intervals using light microscopy. This manual evaluation is not only time-intensive and costly, due to the need for expert analysis, but also inherently subjective, leading to variability in the selection process. To address these challenges, we develop a multimodal model that leverages both time-lapse video data and Electronic Health Records (EHRs) to predict embryo viability. One of the primary challenges of our research is to effectively combine time-lapse video and EHR data, owing to their inherent differences in modality. We comprehensively analyze our multimodal model with various modality inputs and integration approaches. Our approach will enable fast and automated embryo viability predictions in scale for clinical IVF.
Is What You Ask For What You Get? Investigating Concept Associations in Text-to-Image Models
Oct 06, 2024


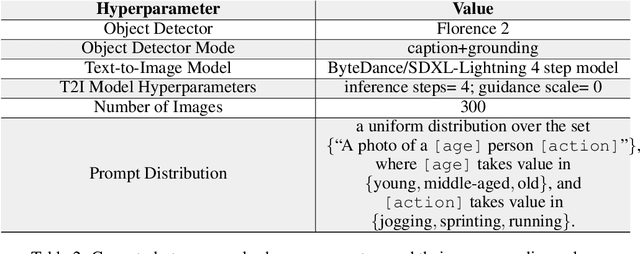
Text-to-image (T2I) models are increasingly used in impactful real-life applications. As such, there is a growing need to audit these models to ensure that they generate desirable, task-appropriate images. However, systematically inspecting the associations between prompts and generated content in a human-understandable way remains challenging. To address this, we propose \emph{Concept2Concept}, a framework where we characterize conditional distributions of vision language models using interpretable concepts and metrics that can be defined in terms of these concepts. This characterization allows us to use our framework to audit models and prompt-datasets. To demonstrate, we investigate several case studies of conditional distributions of prompts, such as user defined distributions or empirical, real world distributions. Lastly, we implement Concept2Concept as an open-source interactive visualization tool facilitating use by non-technical end-users. Warning: This paper contains discussions of harmful content, including CSAM and NSFW material, which may be disturbing to some readers.