 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSCF: Relation-Semantics Consistent Filter for Entity Embedding of Knowledge Graph
May 28, 2025In knowledge graph embedding, leveraging relation specific entity transformation has markedly enhanced performance. However, the consistency of embedding differences before and after transformation remains unaddressed, risking the loss of valuable inductive bias inherent in the embeddings. This inconsistency stems from two problems. First, transformation representations are specified for relations in a disconnected manner, allowing dissimilar transformations and corresponding entity embeddings for similar relations. Second, a generalized plug-in approach as a SFBR (Semantic Filter Based on Relations) disrupts this consistency through excessive concentration of entity embeddings under entity-based regularization, generating indistinguishable score distributions among relations. In this paper, we introduce a plug-in KGE method, Relation-Semantics Consistent Filter (RSCF). Its entity transformation has three features for enhancing semantic consistency: 1) shared affine transformation of relation embeddings across all relations, 2) rooted entity transformation that adds an entity embedding to its change represented by the transformed vector, and 3) normalization of the change to prevent scale reduction. To amplify the advantages of consistency that preserve semantics on embeddings, RSCF adds relation transformation and prediction modules for enhancing the semantics. In knowledge graph completion tasks with distance-based and tensor decomposition models, RSCF significantly outperforms state-of-the-art KGE methods, showing robustness across all relations and their frequencies.
Multiple Invertible and Partial-Equivariant Function for Latent Vector Transformation to Enhance Disentanglement in VAEs
Feb 06, 2025



Disentanglement learning is a core issue for understanding and re-using trained information in Variational AutoEncoder (VAE), and effective inductive bias has been reported as a key factor. However, the actual implementation of such bias is still vague. In this paper, we propose a novel method, called Multiple Invertible and partial-equivariant transformation (MIPE-transformation), to inject inductive bias by 1) guaranteeing the invertibility of latent-to-latent vector transformation while preserving a certain portion of equivariance of input-to-latent vector transformation, called Invertible and partial-equivariant transformation (IPE-transformation), 2) extending the form of prior and posterior in VAE frameworks to an unrestricted form through a learnable conversion to an approximated exponential family, called Exponential Family conversion (EF-conversion), and 3) integrating multiple units of IPE-transformation and EF-conversion, and their training. In experiments on 3D Cars, 3D Shapes, and dSprites datasets, MIPE-transformation improves the disentanglement performance of state-of-the-art VAEs.
Structural Optimization Ambiguity and Simplicity Bias in Unsupervised Neural Grammar Induction
Jul 23, 2024


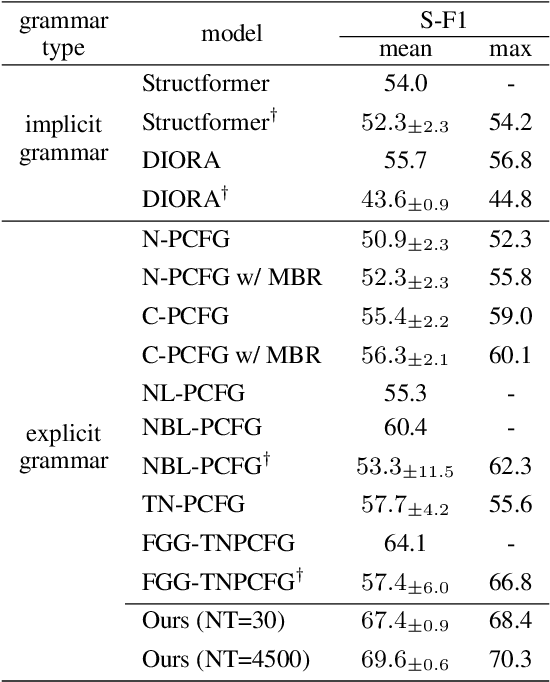
Neural parameterization has significantly advanced unsupervised grammar induction. However, training these models with a traditional likelihood loss for all possible parses exacerbates two issues: 1) $\textit{structural optimization ambiguity}$ that arbitrarily selects one among structurally ambiguous optimal grammars despite the specific preference of gold parses, and 2) $\textit{structural simplicity bias}$ that leads a model to underutilize rules to compose parse trees. These challenges subject unsupervised neural grammar induction (UNGI) to inevitable prediction errors, high variance, and the necessity for extensive grammars to achieve accurate predictions. This paper tackles these issues, offering a comprehensive analysis of their origins. As a solution, we introduce $\textit{sentence-wise parse-focusing}$ to reduce the parse pool per sentence for loss evaluation, using the structural bias from pre-trained parsers on the same dataset. In unsupervised parsing benchmark tests, our method significantly improves performance while effectively reducing variance and bias toward overly simplistic parses. Our research promotes learning more compact, accurate, and consistent explicit grammars, facilitating better interpretability.
Asymptotic Midpoint Mixup for Margin Balancing and Moderate Broadening
Jan 26, 2024In the feature space, the collapse between features invokes critical problems in representation learning by remaining the features undistinguished. Interpolation-based augmentation methods such as mixup have shown their effectiveness in relieving the collapse problem between different classes, called inter-class collapse. However, intra-class collapse raised in coarse-to-fine transfer learning has not been discussed in the augmentation approach. To address them, we propose a better feature augmentation method, asymptotic midpoint mixup. The method generates augmented features by interpolation but gradually moves them toward the midpoint of inter-class feature pairs. As a result, the method induces two effects: 1) balancing the margin for all classes and 2) only moderately broadening the margin until it holds maximal confidence. We empirically analyze the collapse effects by measuring alignment and uniformity with visualizing representations. Then, we validate the intra-class collapse effects in coarse-to-fine transfer learning and the inter-class collapse effects in imbalanced learning on long-tailed datasets. In both tasks, our method shows better performance than other augmentation methods.
CFASL: Composite Factor-Aligned Symmetry Learning for Disentanglement in Variational AutoEncoder
Jan 19, 2024Symmetries of input and latent vectors have provided valuable insights for disentanglement learning in VAEs.However, only a few works were proposed as an unsupervised method, and even these works require known factor information in training data. We propose a novel method, Composite Factor-Aligned Symmetry Learning (CFASL), which is integrated into VAEs for learning symmetry-based disentanglement in unsupervised learning without any knowledge of the dataset factor information.CFASL incorporates three novel features for learning symmetry-based disentanglement: 1) Injecting inductive bias to align latent vector dimensions to factor-aligned symmetries within an explicit learnable symmetry codebook 2) Learning a composite symmetry to express unknown factors change between two random samples by learning factor-aligned symmetries within the codebook 3) Inducing group equivariant encoder and decoder in training VAEs with the two conditions. In addition, we propose an extended evaluation metric for multi-factor changes in comparison to disentanglement evaluation in VAEs. In quantitative and in-depth qualitative analysis, CFASL demonstrates a significant improvement of disentanglement in single-factor change, and multi-factor change conditions compared to state-of-the-art methods.
Revisiting Softmax Masking for Stability in Continual Learning
Sep 26, 2023In continual learning, many classifiers use softmax function to learn confidence. However, numerous studies have pointed out its inability to accurately determine confidence distributions for outliers, often referred to as epistemic uncertainty. This inherent limitation also curtails the accurate decisions for selecting what to forget and keep in previously trained confidence distributions over continual learning process. To address the issue, we revisit the effects of masking softmax function. While this method is both simple and prevalent in literature, its implication for retaining confidence distribution during continual learning, also known as stability, has been under-investigated. In this paper, we revisit the impact of softmax masking, and introduce a methodology to utilize its confidence preservation effects. In class- and task-incremental learning benchmarks with and without memory replay, our approach significantly increases stability while maintaining sufficiently large plasticity. In the end, our methodology shows better overall performance than state-of-the-art methods, particularly in the use with zero or small memory. This lays a simple and effective foundation of strongly stable replay-based continual learning.
Enhancing Accuracy and Robustness through Adversarial Training in Class Incremental Continual Learning
May 23, 2023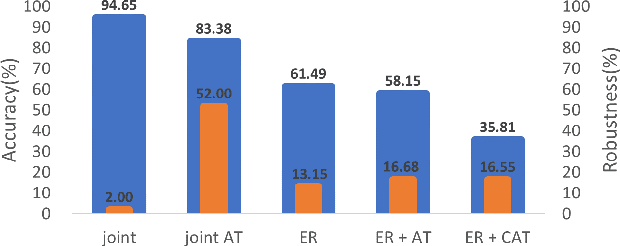
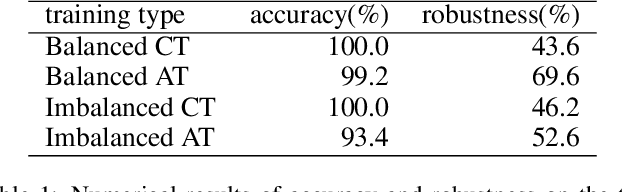
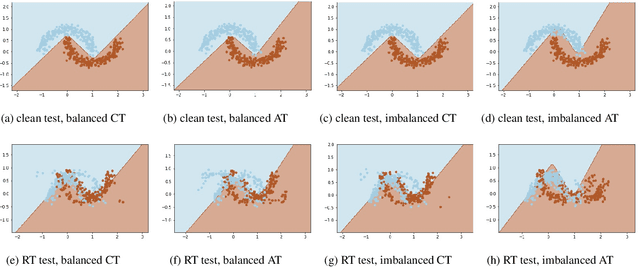

In real life, adversarial attack to deep learning models is a fatal security issue. However, the issue has been rarely discussed in a widely used class-incremental continual learning (CICL). In this paper, we address problems of applying adversarial training to CICL, which is well-known defense method against adversarial attack. A well-known problem of CICL is class-imbalance that biases a model to the current task by a few samples of previous tasks. Meeting with the adversarial training, the imbalance causes another imbalance of attack trials over tasks. Lacking clean data of a minority class by the class-imbalance and increasing of attack trials from a majority class by the secondary imbalance, adversarial training distorts optimal decision boundaries. The distortion eventually decreases both accuracy and robustness than adversarial training. To exclude the effects, we propose a straightforward but significantly effective method, External Adversarial Training (EAT) which can be applied to methods using experience replay. This method conduct adversarial training to an auxiliary external model for the current task data at each time step, and applies generated adversarial examples to train the target model. We verify the effects on a toy problem and show significance on CICL benchmarks of image classification. We expect that the results will be used as the first baseline for robustness research of CICL.
Learning from Matured Dumb Teacher for Fine Generalization
Aug 17, 2021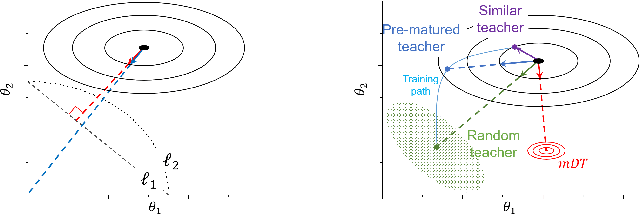
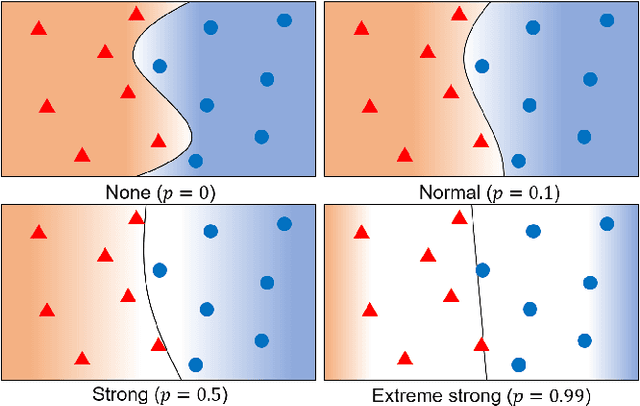
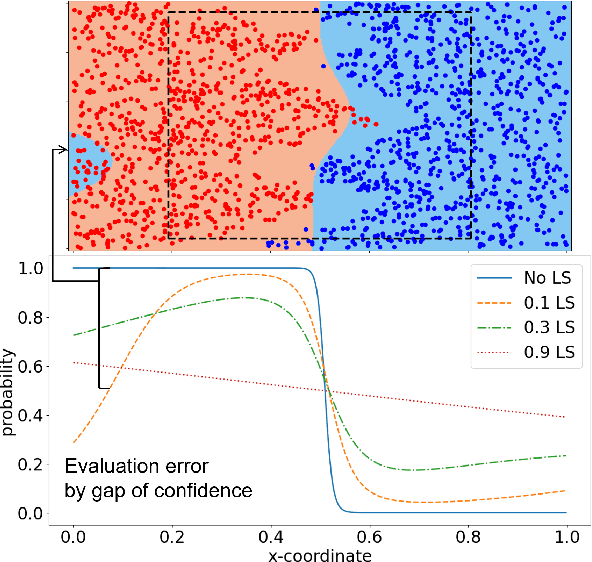
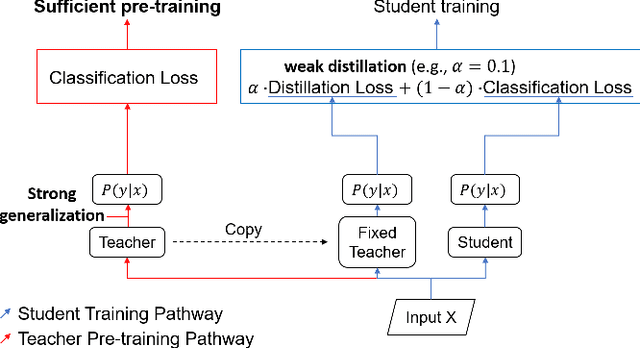
The flexibility of decision boundaries in neural networks that are unguided by training data is a well-known problem typically resolved with generalization methods. A surprising result from recent knowledge distillation (KD) literature is that random, untrained, and equally structured teacher networks can also vastly improve generalization performance. It raises the possibility of existence of undiscovered assumptions useful for generalization on an uncertain region. In this paper, we shed light on the assumptions by analyzing decision boundaries and confidence distributions of both simple and KD-based generalization methods. Assuming that a decision boundary exists to represent the most general tendency of distinction on an input sample space (i.e., the simplest hypothesis), we show the various limitations of methods when using the hypothesis. To resolve these limitations, we propose matured dumb teacher based KD, conservatively transferring the hypothesis for generalization of the student without massive destruction of trained information. In practical experiments on feed-forward and convolution neural networks for image classification tasks on MNIST, CIFAR-10, and CIFAR-100 datasets, the proposed method shows stable improvement to the best test performance in the grid search of hyperparameters. The analysis and results imply that the proposed method can provide finer generalization than existing methods.
What and When to Look?: Temporal Span Proposal Network for Video Visual Relation Detection
Jul 15, 2021
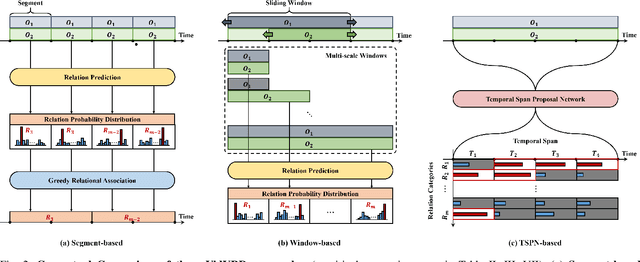
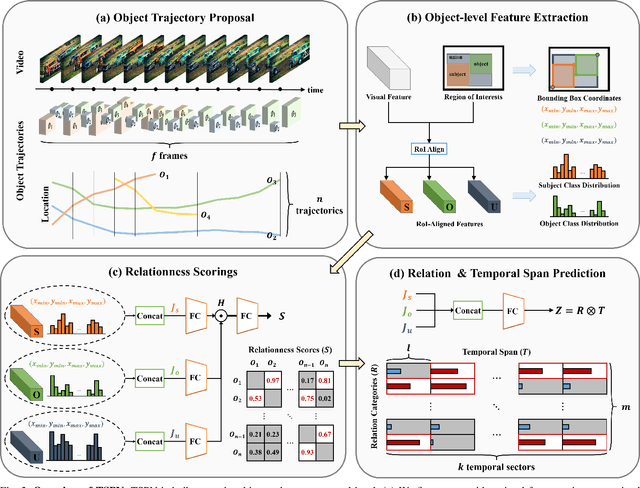

Identifying relations between objects is central to understanding the scene. While several works have been proposed for relation modeling in the image domain, there have been many constraints in the video domain due to challenging dynamics of spatio-temporal interactions (e.g., Between which objects are there an interaction? When do relations occur and end?). To date, two representative methods have been proposed to tackle Video Visual Relation Detection (VidVRD): segment-based and window-based. We first point out the limitations these two methods have and propose Temporal Span Proposal Network (TSPN), a novel method with two advantages in terms of efficiency and effectiveness. 1) TSPN tells what to look: it sparsifies relation search space by scoring relationness (i.e., confidence score for the existence of a relation between pair of objects) of object pair. 2) TSPN tells when to look: it leverages the full video context to simultaneously predict the temporal span and categories of the entire relations. TSPN demonstrates its effectiveness by achieving new state-of-the-art by a significant margin on two VidVRD benchmarks (ImageNet-VidVDR and VidOR) while also showing lower time complexity than existing methods - in particular, twice as efficient as a popular segment-based approach.
Tackling the Challenges in Scene Graph Generation with Local-to-Global Interactions
Jun 16, 2021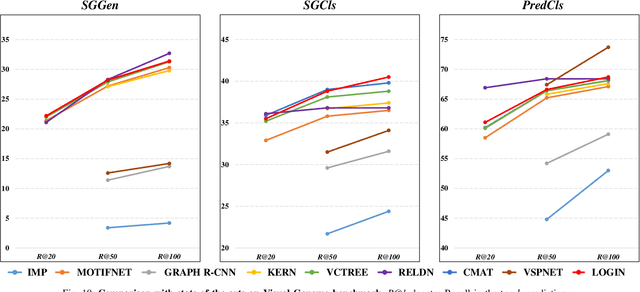
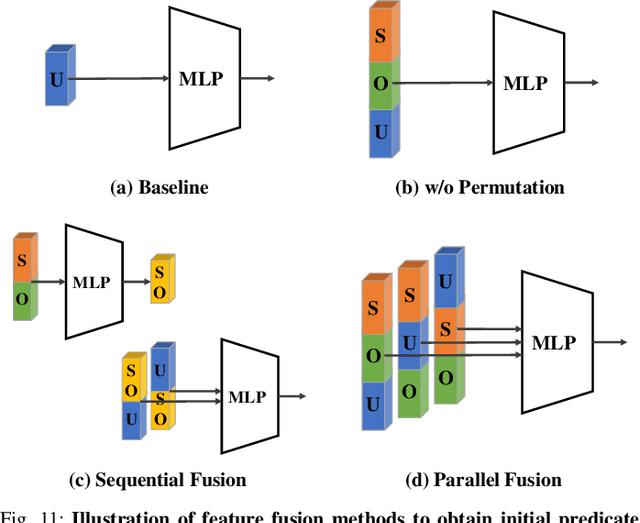
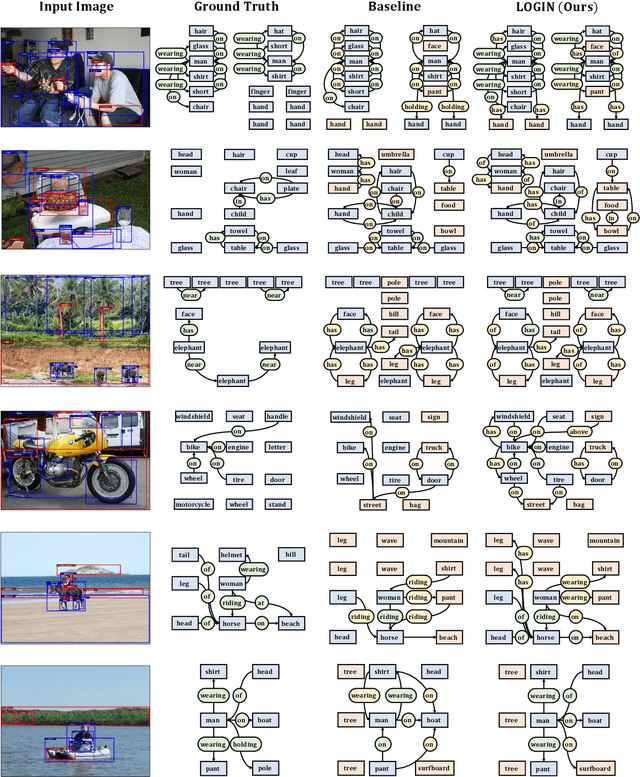
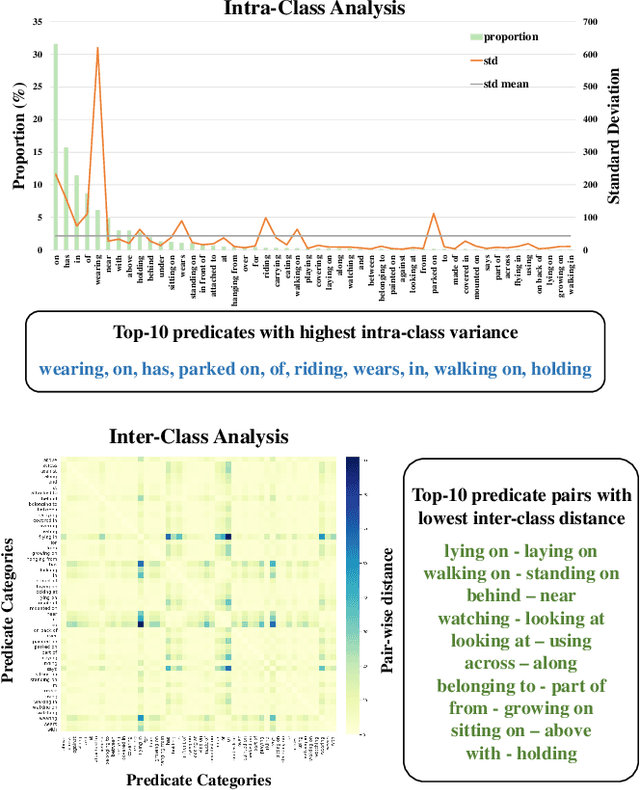
In this work, we seek new insights into the underlying challenges of the Scene Graph Generation (SGG) task. Quantitative and qualitative analysis of the Visual Genome dataset implies -- 1) Ambiguity: even if inter-object relationship contains the same object (or predicate), they may not be visually or semantically similar, 2) Asymmetry: despite the nature of the relationship that embodied the direction, it was not well addressed in previous studies, and 3) Higher-order contexts: leveraging the identities of certain graph elements can help to generate accurate scene graphs. Motivated by the analysis, we design a novel SGG framework, Local-to-Global Interaction Networks (LOGIN). Locally, interactions extract the essence between three instances - subject, object, and background - while baking direction awareness into the network by constraining the input order. Globally, interactions encode the contexts between every graph components -- nodes and edges. Also we introduce Attract & Repel loss which finely adjusts predicate embeddings. Our framework enables predicting the scene graph in a local-to-global manner by design, leveraging the possible complementariness. To quantify how much LOGIN is aware of relational direction, we propose a new diagnostic task called Bidirectional Relationship Classification (BRC). We see that LOGIN can successfully distinguish relational direction than existing methods (in BRC task) while showing state-of-the-art results on the Visual Genome benchmark (in SGG task).