 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit Time-Frequency Dynamics for Skeleton-Based Gait Recognition
Apr 03, 2026Skeleton-based gait recognizers excel at modeling spatial configurations but often underuse explicit motion dynamics that are crucial under appearance changes. We introduce a plug-and-play Wavelet Feature Stream that augments any skeleton backbone with time-frequency dynamics of joint velocities. Concretely, per-joint velocity sequences are transformed by the continuous wavelet transform (CWT) into multi-scale scalograms, from which a lightweight multi-scale CNN learns discriminative dynamic cues. The resulting descriptor is fused with the backbone representation for classification, requiring no changes to the backbone architecture or additional supervision. Across CASIA-B, the proposed stream delivers consistent gains on strong skeleton backbones (e.g., GaitMixer, GaitFormer, GaitGraph) and establishes a new skeleton-based state of the art when attached to GaitMixer. The improvements are especially pronounced under covariate shifts such as carrying bags (BG) and wearing coats (CL), highlighting the complementarity of explicit time-frequency modeling and standard spatio-temporal encoders.
Random Is Hard to Beat: Active Selection in online DPO with Modern LLMs
Apr 03, 2026Modern LLMs inherit strong priors from web-scale pretraining, which can limit the headroom of post-training data-selection strategies. While Active Preference Learning (APL) seeks to optimize query efficiency in online Direct Preference Optimization (DPO), the inherent richness of on-policy candidate pools often renders simple Random sampling a surprisingly formidable baseline. We evaluate uncertainty-based APL against Random across harmlessness, helpfulness, and instruction-following settings, utilizing both reward models and LLM-as-a-judge proxies. We find that APL yields negligible improvements in proxy win-rates compared to Random. Crucially, we observe a dissociation where win-rate improves even as general capability -- measured by standard benchmarks -- degrades. APL fails to mitigate this capability collapse or reduce variance significantly better than random sampling. Our findings suggest that in the regime of strong pre-trained priors, the computational overhead of active selection is difficult to justify against the ``cheap diversity'' provided by simple random samples. Our code is available at https://github.com/BootsofLagrangian/random-vs-apl.
Vicinity-Guided Discriminative Latent Diffusion for Privacy-Preserving Domain Adaptation
Oct 01, 2025Recent work on latent diffusion models (LDMs) has focused almost exclusively on generative tasks, leaving their potential for discriminative transfer largely unexplored. We introduce Discriminative Vicinity Diffusion (DVD), a novel LDM-based framework for a more practical variant of source-free domain adaptation (SFDA): the source provider may share not only a pre-trained classifier but also an auxiliary latent diffusion module, trained once on the source data and never exposing raw source samples. DVD encodes each source feature's label information into its latent vicinity by fitting a Gaussian prior over its k-nearest neighbors and training the diffusion network to drift noisy samples back to label-consistent representations. During adaptation, we sample from each target feature's latent vicinity, apply the frozen diffusion module to generate source-like cues, and use a simple InfoNCE loss to align the target encoder to these cues, explicitly transferring decision boundaries without source access. Across standard SFDA benchmarks, DVD outperforms state-of-the-art methods. We further show that the same latent diffusion module enhances the source classifier's accuracy on in-domain data and boosts performance in supervised classification and domain generalization experiments. DVD thus reinterprets LDMs as practical, privacy-preserving bridges for explicit knowledge transfer, addressing a core challenge in source-free domain adaptation that prior methods have yet to solve.
Generalized Coverage for More Robust Low-Budget Active Learning
Jul 16, 2024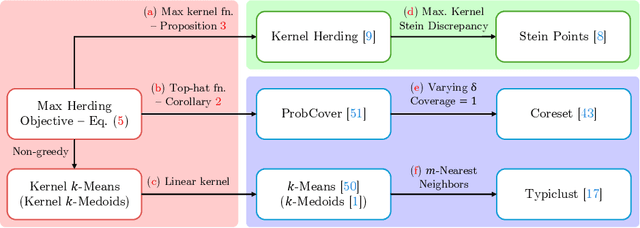
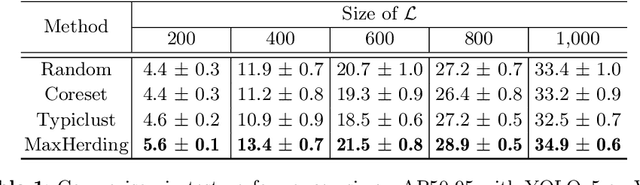
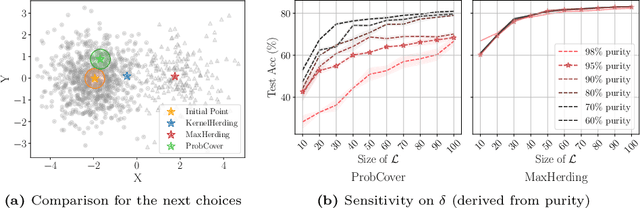
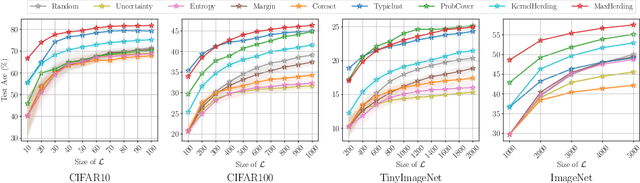
The ProbCover method of Yehuda et al. is a well-motivated algorithm for active learning in low-budget regimes, which attempts to "cover" the data distribution with balls of a given radius at selected data points. We demonstrate, however, that the performance of this algorithm is extremely sensitive to the choice of this radius hyper-parameter, and that tuning it is quite difficult, with the original heuristic frequently failing. We thus introduce (and theoretically motivate) a generalized notion of "coverage," including ProbCover's objective as a special case, but also allowing smoother notions that are far more robust to hyper-parameter choice. We propose an efficient greedy method to optimize this coverage, generalizing ProbCover's algorithm; due to its close connection to kernel herding, we call it "MaxHerding." The objective can also be optimized non-greedily through a variant of $k$-medoids, clarifying the relationship to other low-budget active learning methods. In comprehensive experiments, MaxHerding surpasses existing active learning methods across multiple low-budget image classification benchmarks, and does so with less computational cost than most competitive methods.
Scalp Diagnostic System With Label-Free Segmentation and Training-Free Image Translation
Jun 26, 2024Scalp diseases and alopecia affect millions of people around the world, underscoring the urgent need for early diagnosis and management of the disease. However, the development of a comprehensive AI-based diagnosis system encompassing these conditions remains an underexplored domain due to the challenges associated with data imbalance and the costly nature of labeling. To address these issues, we propose ScalpVision, an AI-driven system for the holistic diagnosis of scalp diseases and alopecia. In ScalpVision, effective hair segmentation is achieved using pseudo image-label pairs and an innovative prompting method in the absence of traditional hair masking labels. This approach is crucial for extracting key features such as hair thickness and count, which are then used to assess alopecia severity. Additionally, ScalpVision introduces DiffuseIT-M, a generative model adept at dataset augmentation while maintaining hair information, facilitating improved predictions of scalp disease severity. Our experimental results affirm ScalpVision's efficiency in diagnosing a variety of scalp conditions and alopecia, showcasing its potential as a valuable tool in dermatological care.
Object Discovery via Contrastive Learning for Weakly Supervised Object Detection
Aug 16, 2022
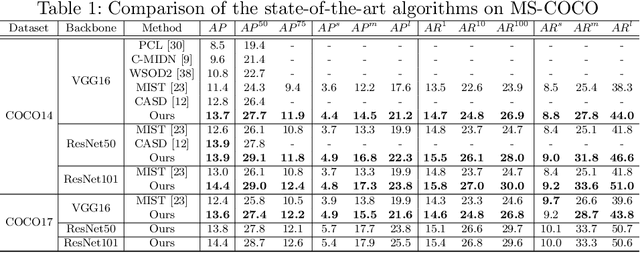
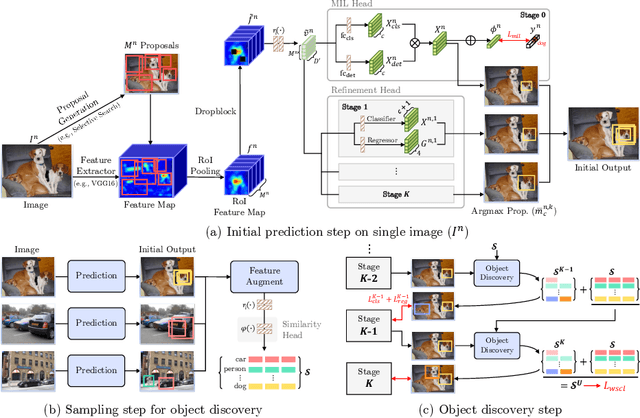
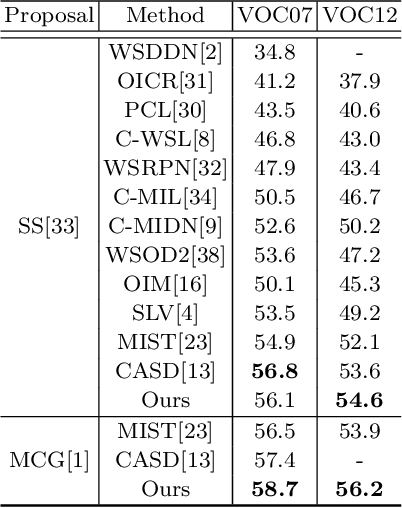
Weakly Supervised Object Detection (WSOD) is a task that detects objects in an image using a model trained only on image-level annotations. Current state-of-the-art models benefit from self-supervised instance-level supervision, but since weak supervision does not include count or location information, the most common ``argmax'' labeling method often ignores many instances of objects. To alleviate this issue, we propose a novel multiple instance labeling method called object discovery. We further introduce a new contrastive loss under weak supervision where no instance-level information is available for sampling, called weakly supervised contrastive loss (WSCL). WSCL aims to construct a credible similarity threshold for object discovery by leveraging consistent features for embedding vectors in the same class. As a result, we achieve new state-of-the-art results on MS-COCO 2014 and 2017 as well as PASCAL VOC 2012, and competitive results on PASCAL VOC 2007.
One Weird Trick to Improve Your Semi-Weakly Supervised Semantic Segmentation Model
May 02, 2022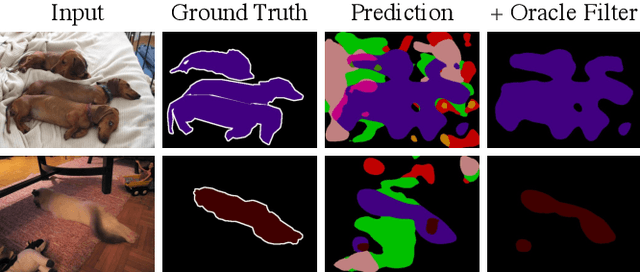
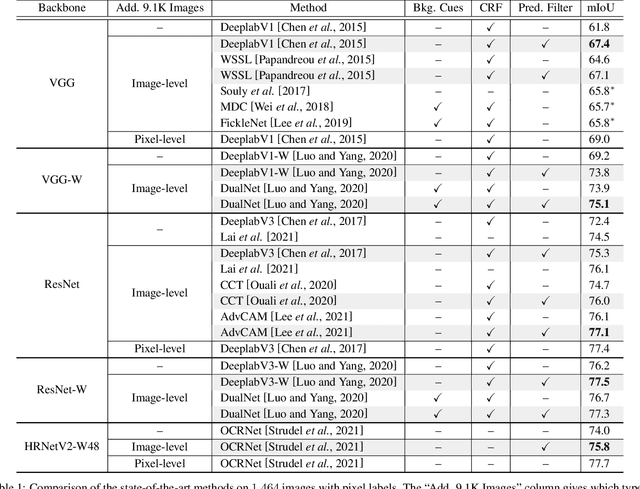
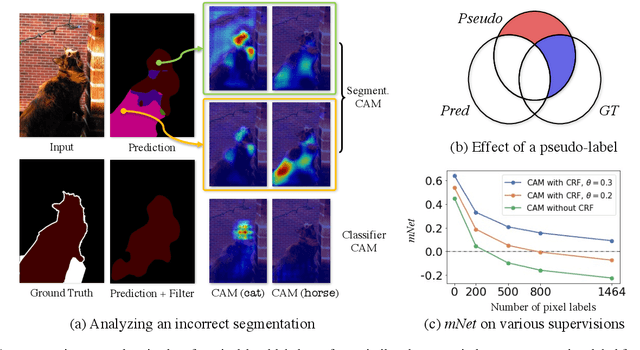

Semi-weakly supervised semantic segmentation (SWSSS) aims to train a model to identify objects in images based on a small number of images with pixel-level labels, and many more images with only image-level labels. Most existing SWSSS algorithms extract pixel-level pseudo-labels from an image classifier - a very difficult task to do well, hence requiring complicated architectures and extensive hyperparameter tuning on fully-supervised validation sets. We propose a method called prediction filtering, which instead of extracting pseudo-labels, just uses the classifier as a classifier: it ignores any segmentation predictions from classes which the classifier is confident are not present. Adding this simple post-processing method to baselines gives results competitive with or better than prior SWSSS algorithms. Moreover, it is compatible with pseudo-label methods: adding prediction filtering to existing SWSSS algorithms further improves segmentation performance.
What and When to Look?: Temporal Span Proposal Network for Video Visual Relation Detection
Jul 15, 2021
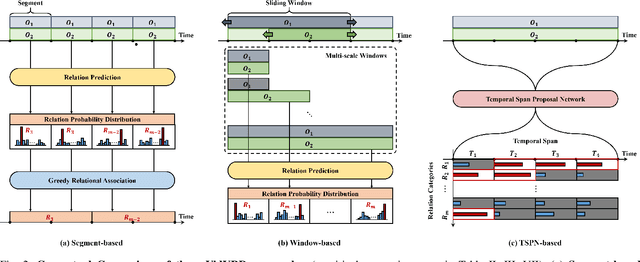
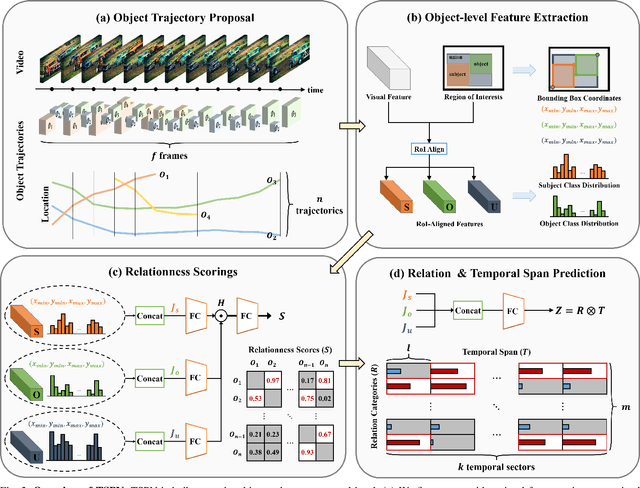

Identifying relations between objects is central to understanding the scene. While several works have been proposed for relation modeling in the image domain, there have been many constraints in the video domain due to challenging dynamics of spatio-temporal interactions (e.g., Between which objects are there an interaction? When do relations occur and end?). To date, two representative methods have been proposed to tackle Video Visual Relation Detection (VidVRD): segment-based and window-based. We first point out the limitations these two methods have and propose Temporal Span Proposal Network (TSPN), a novel method with two advantages in terms of efficiency and effectiveness. 1) TSPN tells what to look: it sparsifies relation search space by scoring relationness (i.e., confidence score for the existence of a relation between pair of objects) of object pair. 2) TSPN tells when to look: it leverages the full video context to simultaneously predict the temporal span and categories of the entire relations. TSPN demonstrates its effectiveness by achieving new state-of-the-art by a significant margin on two VidVRD benchmarks (ImageNet-VidVDR and VidOR) while also showing lower time complexity than existing methods - in particular, twice as efficient as a popular segment-based approach.
Tackling the Challenges in Scene Graph Generation with Local-to-Global Interactions
Jun 16, 2021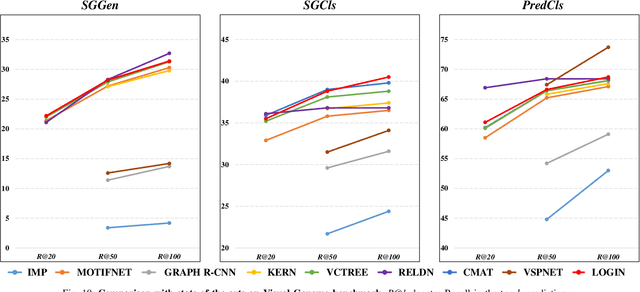
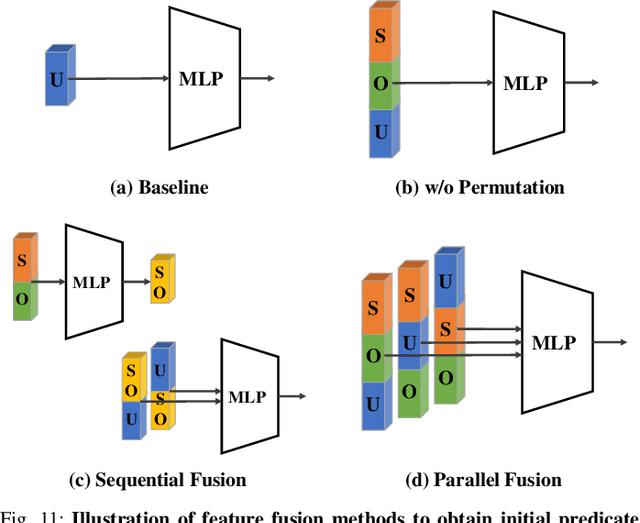
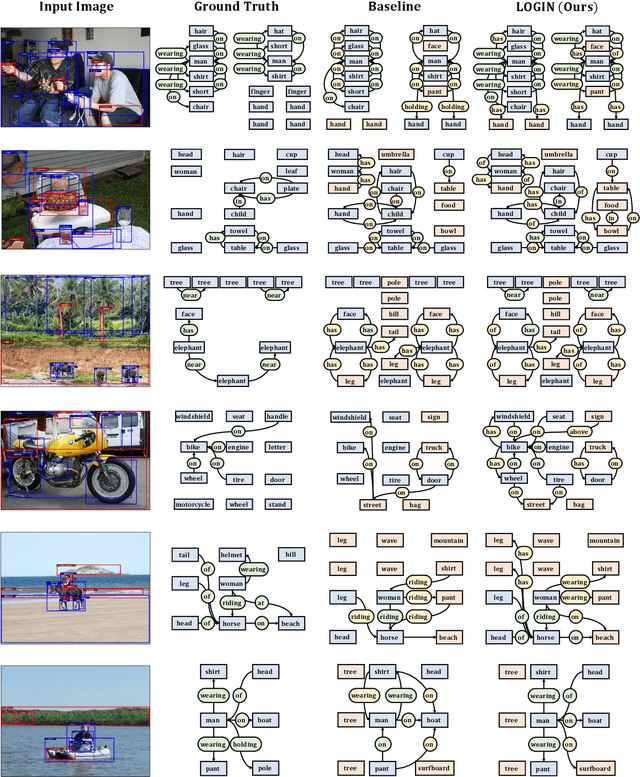
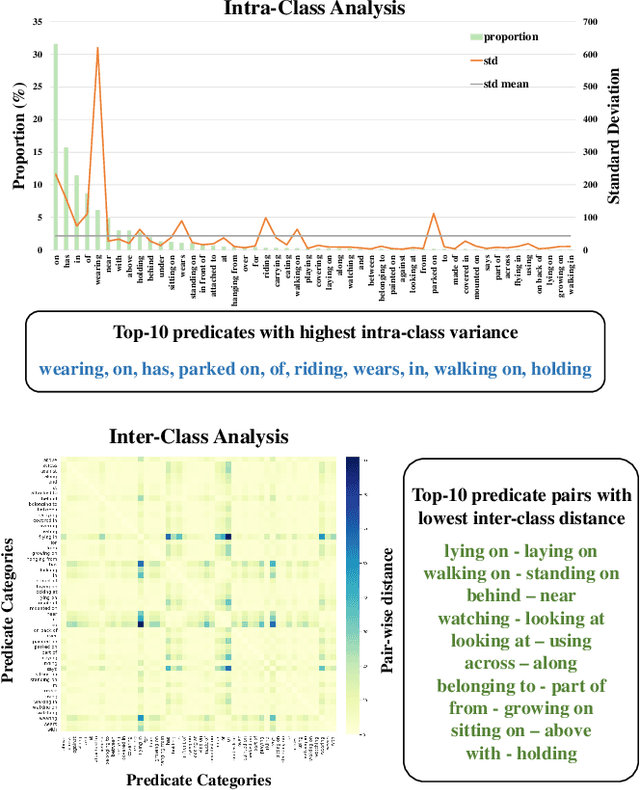
In this work, we seek new insights into the underlying challenges of the Scene Graph Generation (SGG) task. Quantitative and qualitative analysis of the Visual Genome dataset implies -- 1) Ambiguity: even if inter-object relationship contains the same object (or predicate), they may not be visually or semantically similar, 2) Asymmetry: despite the nature of the relationship that embodied the direction, it was not well addressed in previous studies, and 3) Higher-order contexts: leveraging the identities of certain graph elements can help to generate accurate scene graphs. Motivated by the analysis, we design a novel SGG framework, Local-to-Global Interaction Networks (LOGIN). Locally, interactions extract the essence between three instances - subject, object, and background - while baking direction awareness into the network by constraining the input order. Globally, interactions encode the contexts between every graph components -- nodes and edges. Also we introduce Attract & Repel loss which finely adjusts predicate embeddings. Our framework enables predicting the scene graph in a local-to-global manner by design, leveraging the possible complementariness. To quantify how much LOGIN is aware of relational direction, we propose a new diagnostic task called Bidirectional Relationship Classification (BRC). We see that LOGIN can successfully distinguish relational direction than existing methods (in BRC task) while showing state-of-the-art results on the Visual Genome benchmark (in SGG task).
LID 2020: The Learning from Imperfect Data Challenge Results
Oct 17, 2020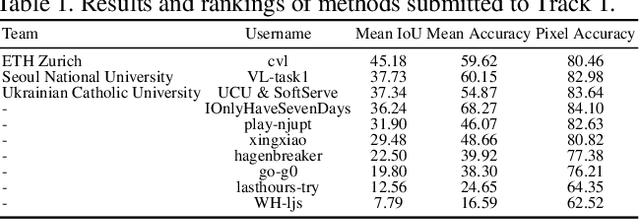
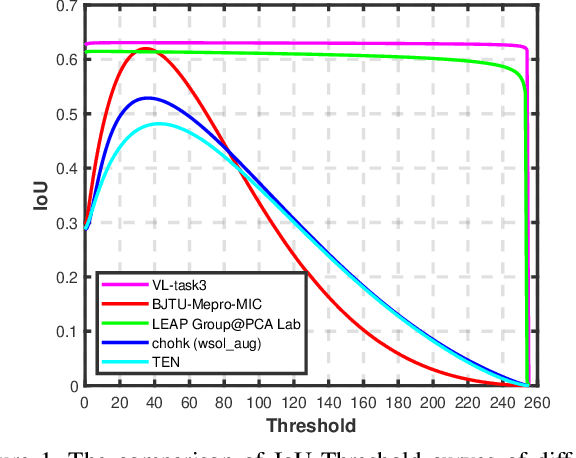

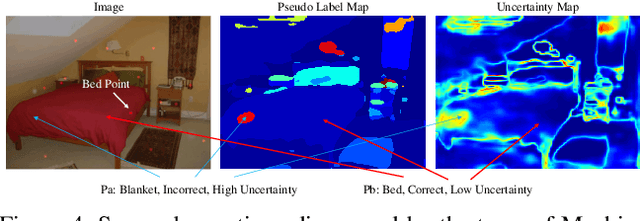
Learning from imperfect data becomes an issue in many industrial applications after the research community has made profound progress in supervised learning from perfectly annotated datasets. The purpose of the Learning from Imperfect Data (LID) workshop is to inspire and facilitate the research in developing novel approaches that would harness the imperfect data and improve the data-efficiency during training. A massive amount of user-generated data nowadays available on multiple internet services. How to leverage those and improve the machine learning models is a high impact problem. We organize the challenges in conjunction with the workshop. The goal of these challenges is to find the state-of-the-art approaches in the weakly supervised learning setting for object detection, semantic segmentation, and scene parsing. There are three tracks in the challenge, i.e., weakly supervised semantic segmentation (Track 1), weakly supervised scene parsing (Track 2), and weakly supervised object localization (Track 3). In Track 1, based on ILSVRC DET, we provide pixel-level annotations of 15K images from 200 categories for evaluation. In Track 2, we provide point-based annotations for the training set of ADE20K. In Track 3, based on ILSVRC CLS-LOC, we provide pixel-level annotations of 44,271 images for evaluation. Besides, we further introduce a new evaluation metric proposed by \cite{zhang2020rethinking}, i.e., IoU curve, to measure the quality of the generated object localization maps. This technical report summarizes the highlights from the challenge. The challenge submission server and the leaderboard will continue to open for the researchers who are interested in it. More details regarding the challenge and the benchmarks are available at https://lidchallenge.github.io